LLM-enhanced Reranking in Recommender Systems
2406.12433
0
0

Abstract
Reranking is a critical component in recommender systems, playing an essential role in refining the output of recommendation algorithms. Traditional reranking models have focused predominantly on accuracy, but modern applications demand consideration of additional criteria such as diversity and fairness. Existing reranking approaches often fail to harmonize these diverse criteria effectively at the model level. Moreover, these models frequently encounter challenges with scalability and personalization due to their complexity and the varying significance of different reranking criteria in diverse scenarios. In response, we introduce a comprehensive reranking framework enhanced by LLM, designed to seamlessly integrate various reranking criteria while maintaining scalability and facilitating personalized recommendations. This framework employs a fully connected graph structure, allowing the LLM to simultaneously consider multiple aspects such as accuracy, diversity, and fairness through a coherent Chain-of-Thought (CoT) process. A customizable input mechanism is also integrated, enabling the tuning of the language model's focus to meet specific reranking needs. We validate our approach using three popular public datasets, where our framework demonstrates superior performance over existing state-of-the-art reranking models in balancing multiple criteria. The code for this implementation is publicly available.
Create account to get full access
Overview
- This paper proposes a framework for enhancing recommender systems by leveraging large language models (LLMs) to rerank recommendations.
- The approach aims to improve the diversity and relevance of recommendations beyond what can be achieved with traditional collaborative filtering techniques.
- The framework integrates LLMs with collaborative filtering models to capture both semantic and collaborative signals for more effective recommendation.
Plain English Explanation
The paper presents a way to make recommendation systems better by using large language models (LLMs) to reorder the recommendations. Recommendation systems are tools that suggest products or content that a user might like, based on their past preferences and what similar users have liked.
Traditional recommendation systems use collaborative filtering, which looks at patterns in what users have liked before. This paper argues that you can improve recommendations by also considering the actual meaning and context of the items, not just the patterns.
The key idea is to use powerful LLM AI models, which are trained on huge amounts of text data, to better understand the semantic relationships between items. By combining this semantic understanding with the collaborative filtering approach, the system can make more diverse and relevant recommendations that better match what the user is likely to find interesting.
This builds on previous work that has looked at ways to integrate LLMs with recommendation systems. The new framework proposed in this paper provides a more principled way to leverage the strengths of both LLMs and collaborative filtering.
Technical Explanation
The paper formulates the problem of LLM-enhanced reranking in recommender systems, where the goal is to leverage LLMs to reorder an initial set of recommendations generated by a collaborative filtering model.
The proposed framework has three key components:
-
Initial Ranking: A traditional collaborative filtering model is used to generate an initial ranking of recommended items.
-
LLM-based Reranking: An LLM is used to compute semantic similarity scores between the user's context (e.g., past interactions, current query) and the candidate items. These scores are then combined with the initial ranking to produce a final reranked list of recommendations.
-
Fusion Mechanism: The paper explores different ways to integrate the collaborative filtering and LLM-based scores, including linear combination and neural network-based fusion models.
The authors evaluate their approach on several public recommendation datasets and show that it can significantly improve the diversity and relevance of recommendations compared to using collaborative filtering alone. The results build on insights from related work on effectively combining LLMs with traditional recommendation techniques.
Critical Analysis
The paper presents a well-designed framework that effectively integrates LLMs with collaborative filtering for enhanced recommendation. The authors carefully consider different fusion mechanisms and provide a thorough experimental evaluation.
One potential limitation is that the approach relies on the availability of high-quality LLM models, which can be computationally expensive to deploy at scale. Further research may be needed to make the approach more efficient and practical for real-world recommender systems.
Additionally, the paper does not explore potential biases or fairness issues that may arise from using LLMs, which are known to exhibit various societal biases. Addressing these concerns would be an important direction for future work to ensure the ethical and responsible deployment of these techniques.
Overall, the proposed framework represents a promising step forward in enhancing recommender systems by leveraging the power of large language models, and the insights from this work can inform further advancements in this important area of research.
Conclusion
This paper presents a novel framework for improving recommender systems by integrating large language models (LLMs) to rerank initial recommendations generated by traditional collaborative filtering techniques. The key idea is to leverage the semantic understanding provided by LLMs to complement the collaborative signals, resulting in more diverse and relevant recommendations.
The authors demonstrate the effectiveness of their approach through extensive experiments, showing significant improvements in recommendation quality compared to using collaborative filtering alone. This work builds on and extends previous research on combining LLMs with recommender systems, providing a more principled and effective way to harness the strengths of both approaches.
While the framework has some practical considerations around computational efficiency and potential biases, the core insights from this paper represent an important contribution to the field of recommender systems, paving the way for further advancements in this rapidly evolving area of AI research and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enhancing Recommendation Diversity by Re-ranking with Large Language Models
Diego Carraro, Derek Bridge
0
0
It has long been recognized that it is not enough for a Recommender System (RS) to provide recommendations based only on their relevance to users. Among many other criteria, the set of recommendations may need to be diverse. Diversity is one way of handling recommendation uncertainty and ensuring that recommendations offer users a meaningful choice. The literature reports many ways of measuring diversity and improving the diversity of a set of recommendations, most notably by re-ranking and selecting from a larger set of candidate recommendations. Driven by promising insights from the literature on how to incorporate versatile Large Language Models (LLMs) into the RS pipeline, in this paper we show how LLMs can be used for diversity re-ranking. We begin with an informal study that verifies that LLMs can be used for re-ranking tasks and do have some understanding of the concept of item diversity. Then, we design a more rigorous methodology where LLMs are prompted to generate a diverse ranking from a candidate ranking using various prompt templates with different re-ranking instructions in a zero-shot fashion. We conduct comprehensive experiments testing state-of-the-art LLMs from the GPT and Llama families. We compare their re-ranking capabilities with random re-ranking and various traditional re-ranking methods from the literature. We open-source the code of our experiments for reproducibility. Our findings suggest that the trade-offs (in terms of performance and costs, among others) of LLM-based re-rankers are superior to those of random re-rankers but, as yet, inferior to the ones of traditional re-rankers. However, the LLM approach is promising. LLMs exhibit improved performance on many natural language processing and recommendation tasks and lower inference costs. Given these trends, we can expect LLM-based re-ranking to become more competitive soon.
6/19/2024
💬
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, Ji-Rong Wen
0
0
Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
4/22/2024
Make Large Language Model a Better Ranker
Wenshuo Chao, Zhi Zheng, Hengshu Zhu, Hao Liu
0
0
Large Language Models (LLMs) demonstrate robust capabilities across various fields, leading to a paradigm shift in LLM-enhanced Recommender System (RS). Research to date focuses on point-wise and pair-wise recommendation paradigms, which are inefficient for LLM-based recommenders due to high computational costs. However, existing list-wise approaches also fall short in ranking tasks due to misalignment between ranking objectives and next-token prediction. Moreover, these LLM-based methods struggle to effectively address the order relation among candidates, particularly given the scale of ratings. To address these challenges, this paper introduces the large language model framework with Aligned Listwise Ranking Objectives (ALRO). ALRO is designed to bridge the gap between the capabilities of LLMs and the nuanced requirements of ranking tasks. Specifically, ALRO employs explicit feedback in a listwise manner by introducing soft lambda loss, a customized adaptation of lambda loss designed for optimizing order relations. This mechanism provides more accurate optimization goals, enhancing the ranking process. Additionally, ALRO incorporates a permutation-sensitive learning mechanism that addresses position bias, a prevalent issue in generative models, without imposing additional computational burdens during inference. Our evaluative studies reveal that ALRO outperforms both existing embedding-based recommendation methods and LLM-based recommendation baselines.
6/26/2024
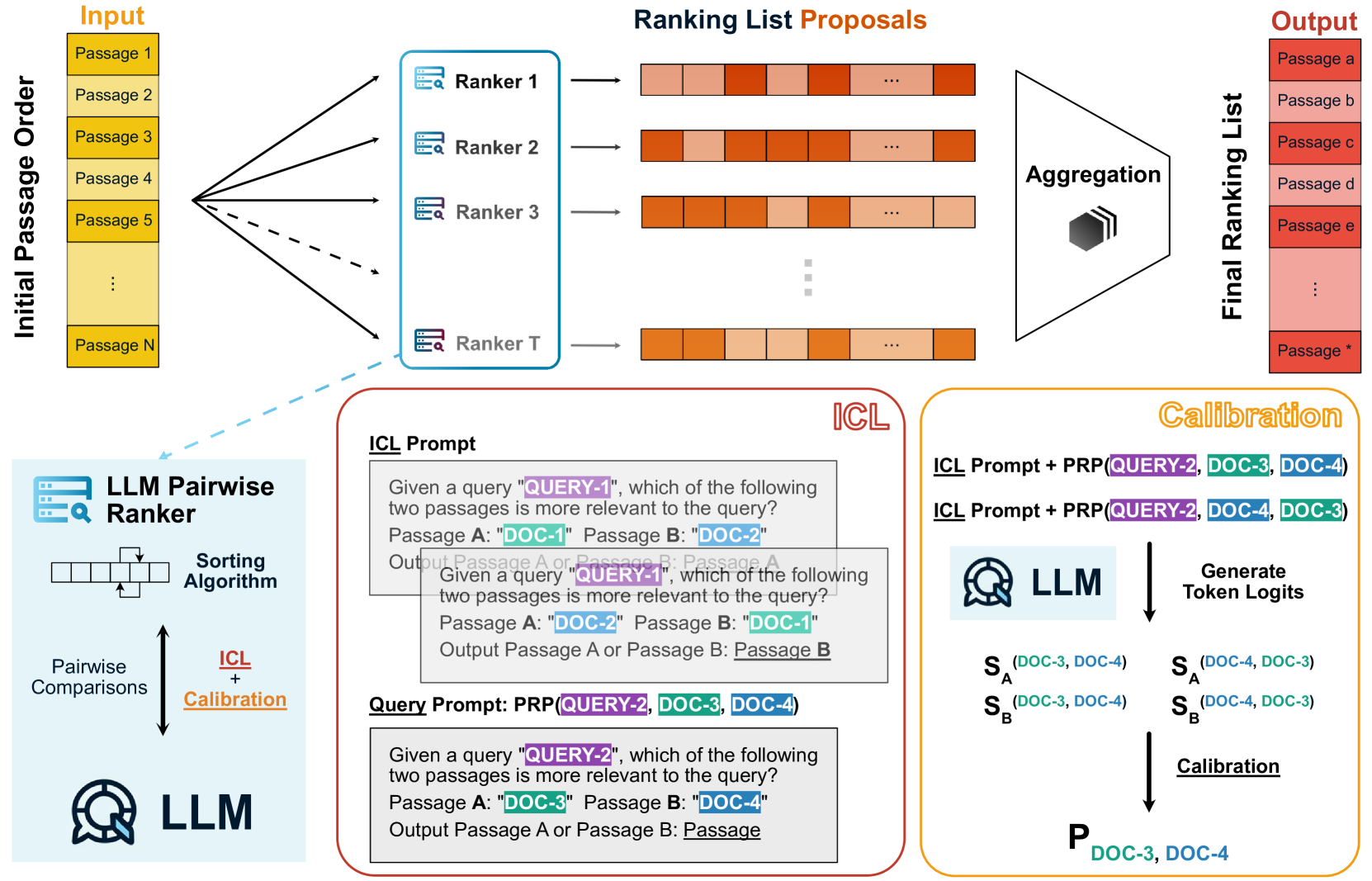
LLM-RankFusion: Mitigating Intrinsic Inconsistency in LLM-based Ranking
Yifan Zeng, Ojas Tendolkar, Raymond Baartmans, Qingyun Wu, Huazheng Wang, Lizhong Chen
0
0
Ranking passages by prompting a large language model (LLM) can achieve promising performance in modern information retrieval (IR) systems. A common approach is to sort the ranking list by prompting LLMs for pairwise comparison. However, sorting-based methods require consistent comparisons to correctly sort the passages, which we show that LLMs often violate. We identify two kinds of intrinsic inconsistency in LLM-based pairwise comparisons: order inconsistency which leads to conflicting results when switching the passage order, and transitive inconsistency which leads to non-transitive triads among all preference pairs. In this paper, we propose LLM-RankFusion, an LLM-based ranking framework that mitigates these inconsistencies and produces a robust ranking list. LLM-RankFusion mitigates order inconsistency using in-context learning (ICL) to demonstrate order-agnostic comparisons and calibration to estimate the underlying preference probability between two passages. We then address transitive inconsistency by aggregating the ranking results from multiple rankers. In our experiments, we empirically show that LLM-RankFusion can significantly reduce inconsistent pairwise comparison results, and improve the ranking quality by making the final ranking list more robust.
6/4/2024