Enhancing Research Information Systems with Identification of Domain Experts

0

Sign in to get full access
Overview
- The paper explores enhancing research information systems by identifying domain experts.
- It investigates using large language models and scholarly datasets to classify research areas and find relevant experts.
- The goal is to improve search and discovery capabilities in research databases and platforms.
Plain English Explanation
The paper aims to make it easier for researchers to find relevant experts and information in their fields. Current research databases and search engines can be limited in their ability to accurately classify research topics and match users with the right experts or resources.
The researchers propose using large language models, which are powerful AI systems trained on massive amounts of text data, to better understand and categorize research areas. By analyzing scholarly publications and other data, these models can learn to identify the key concepts, methodologies, and experts associated with different research domains.
This classification could then be used to enhance search and discovery features on research platforms. For example, when a user searches for information on a particular topic, the system could surface not only relevant publications, but also suggest relevant experts they could consult or collaborate with. This could help researchers more efficiently find the right people and information to support their work.
Overall, the goal is to leverage advanced AI and data analysis techniques to make research information systems more intelligent and user-friendly, ultimately accelerating the pace of scientific progress.
Technical Explanation
The paper presents a framework for enhancing research information systems through the identification of domain experts. The key components include:
-
Research Area Classification: The researchers use a large language model, specifically a BERT-based model, to classify research publications into relevant domains or areas of study. This involves training the model on a large scholarly dataset to learn the linguistic patterns and conceptual relationships that characterize different research fields.
-
Expert Identification: Building on the research area classification, the framework then uses the language model to identify domain experts based on their published works, citations, and other metadata. Experts are identified as individuals who have made significant contributions to a particular research area.
-
Integration with Search and Discovery: The classified research areas and identified experts are then integrated into a research information system, such as a search engine or research database. This allows users to more effectively discover relevant publications, experts, and connections between different domains of study.
The researchers evaluated their approach using a real-world scholarly dataset and found that it outperformed traditional methods for research area classification and expert identification. This suggests that the integration of large language models and scholarly data can enhance the capabilities of research information systems, ultimately benefiting researchers and advancing scientific progress.
Critical Analysis
The paper presents a compelling approach to improving research information systems, but there are a few potential limitations and areas for further exploration:
-
Bias and Fairness: The performance of the language model and expert identification system may be influenced by biases present in the scholarly dataset used for training. This could lead to the exclusion or underrepresentation of certain research areas or demographics of experts. Addressing these biases would be an important area for future research.
-
Contextual Understanding: While large language models excel at capturing the semantic relationships between concepts, they may struggle to fully understand the nuanced context and methodologies that characterize different research domains. Incorporating additional domain-specific knowledge or expert feedback could further improve the accuracy of the research area classification.
-
Interdisciplinary Research: The paper focuses on identifying experts within specific research areas, but the increasingly interdisciplinary nature of science may require approaches that can better recognize and connect experts across different fields. Exploring ways to capture these cross-disciplinary connections could be a valuable extension of this work.
-
User Experience and Adoption: Ultimately, the success of this framework will depend on its practical implementation and adoption by researchers and research organizations. Careful attention to user interface design, integration with existing systems, and user feedback will be crucial for ensuring the system is intuitive and valuable in real-world settings.
Conclusion
The paper presents a promising approach to enhancing research information systems by leveraging large language models and scholarly data to identify domain experts. This could lead to more effective search, discovery, and collaboration capabilities for researchers, ultimately accelerating scientific progress. While there are some potential limitations and areas for further exploration, the core ideas and technical approach demonstrated in this work have significant potential to improve how researchers access and engage with the vast and ever-growing body of knowledge in their fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Research Information Systems with Identification of Domain Experts
Gautam Kishore Shahi, Oliver Hummel
Research organisations and their research outputs have been growing considerably in the past decades. This large body of knowledge attracts various stakeholders, e.g., for knowledge sharing, technology transfer, or potential collaborations. However, due to the large amount of complex knowledge created, traditional methods of manually curating catalogues are often out of time, imprecise, and cumbersome. Finding domain experts and knowledge within any larger organisation, scientific and also industrial, has thus become a serious challenge. Hence, exploring an institutions domain knowledge and finding its experts can only be solved by an automated solution. This work presents the scheme of an automated approach for identifying scholarly experts based on their publications and, prospectively, their teaching materials. Based on a search engine, this approach is currently being implemented for two universities, for which some examples are presented. The proposed system will be helpful for finding peer researchers as well as starting points for knowledge exploitation and technology transfer. As the system is designed in a scalable manner, it can easily include additional institutions and hence provide a broader coverage of research facilities in the future.
Read more4/5/2024
0
Fact Finder -- Enhancing Domain Expertise of Large Language Models by Incorporating Knowledge Graphs
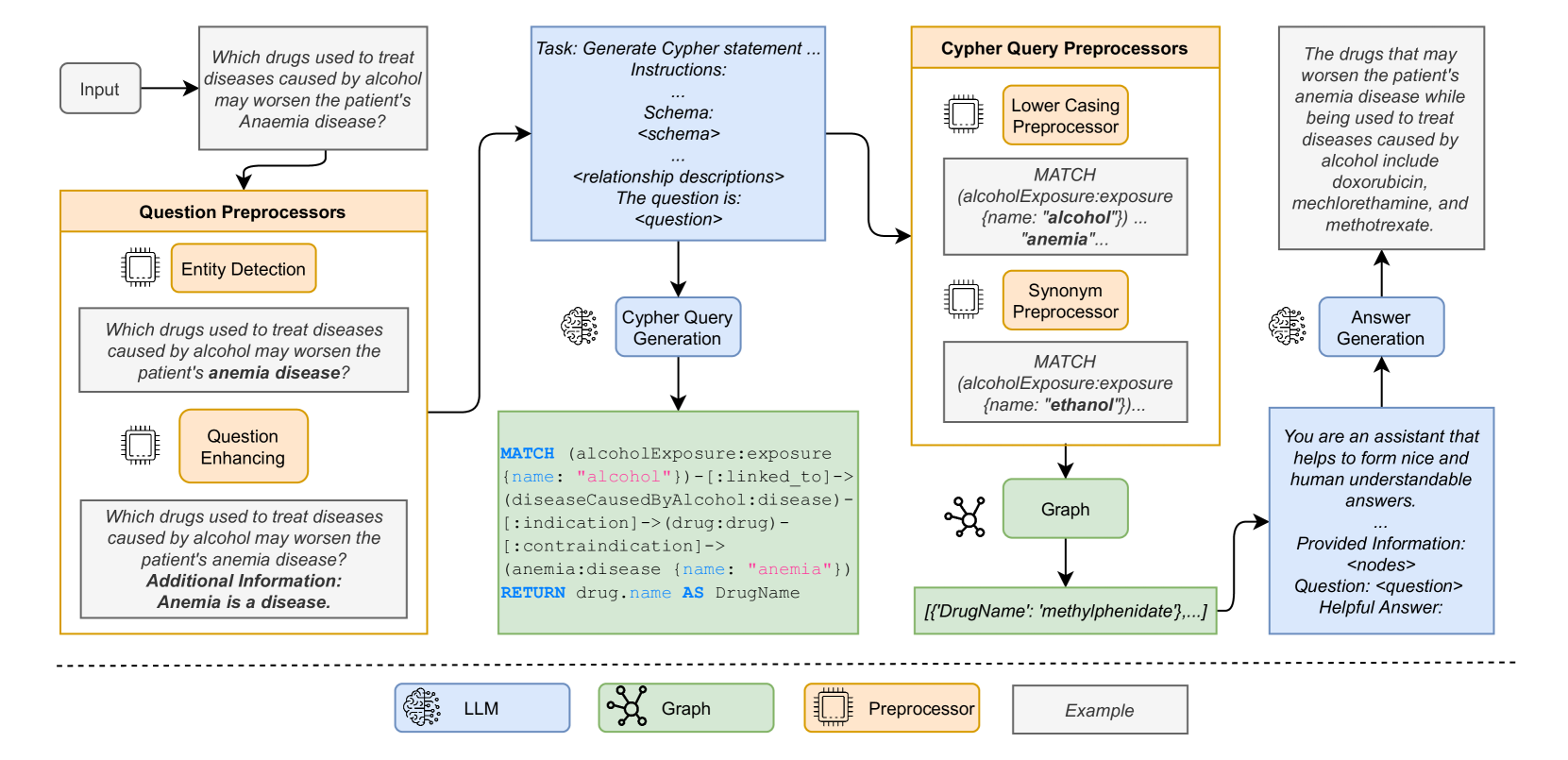
Daniel Steinigen, Roman Teucher, Timm Heine Ruland, Max Rudat, Nicolas Flores-Herr, Peter Fischer, Nikola Milosevic, Christopher Schymura, Angelo Ziletti
Recent advancements in Large Language Models (LLMs) have showcased their proficiency in answering natural language queries. However, their effectiveness is hindered by limited domain-specific knowledge, raising concerns about the reliability of their responses. We introduce a hybrid system that augments LLMs with domain-specific knowledge graphs (KGs), thereby aiming to enhance factual correctness using a KG-based retrieval approach. We focus on a medical KG to demonstrate our methodology, which includes (1) pre-processing, (2) Cypher query generation, (3) Cypher query processing, (4) KG retrieval, and (5) LLM-enhanced response generation. We evaluate our system on a curated dataset of 69 samples, achieving a precision of 78% in retrieving correct KG nodes. Our findings indicate that the hybrid system surpasses a standalone LLM in accuracy and completeness, as verified by an LLM-as-a-Judge evaluation method. This positions the system as a promising tool for applications that demand factual correctness and completeness, such as target identification -- a critical process in pinpointing biological entities for disease treatment or crop enhancement. Moreover, its intuitive search interface and ability to provide accurate responses within seconds make it well-suited for time-sensitive, precision-focused research contexts. We publish the source code together with the dataset and the prompt templates used.
Read more8/7/2024
0
Automating Research Synthesis with Domain-Specific Large Language Model Fine-Tuning
Teo Susnjak, Peter Hwang, Napoleon H. Reyes, Andre L. C. Barczak, Timothy R. McIntosh, Surangika Ranathunga
This research pioneers the use of fine-tuned Large Language Models (LLMs) to automate Systematic Literature Reviews (SLRs), presenting a significant and novel contribution in integrating AI to enhance academic research methodologies. Our study employed the latest fine-tuning methodologies together with open-sourced LLMs, and demonstrated a practical and efficient approach to automating the final execution stages of an SLR process that involves knowledge synthesis. The results maintained high fidelity in factual accuracy in LLM responses, and were validated through the replication of an existing PRISMA-conforming SLR. Our research proposed solutions for mitigating LLM hallucination and proposed mechanisms for tracking LLM responses to their sources of information, thus demonstrating how this approach can meet the rigorous demands of scholarly research. The findings ultimately confirmed the potential of fine-tuned LLMs in streamlining various labor-intensive processes of conducting literature reviews. Given the potential of this approach and its applicability across all research domains, this foundational study also advocated for updating PRISMA reporting guidelines to incorporate AI-driven processes, ensuring methodological transparency and reliability in future SLRs. This study broadens the appeal of AI-enhanced tools across various academic and research fields, setting a new standard for conducting comprehensive and accurate literature reviews with more efficiency in the face of ever-increasing volumes of academic studies.
Read more4/16/2024

0
Comparative Study of Domain Driven Terms Extraction Using Large Language Models
Sandeep Chataut, Tuyen Do, Bichar Dip Shrestha Gurung, Shiva Aryal, Anup Khanal, Carol Lushbough, Etienne Gnimpieba
Keywords play a crucial role in bridging the gap between human understanding and machine processing of textual data. They are essential to data enrichment because they form the basis for detailed annotations that provide a more insightful and in-depth view of the underlying data. Keyword/domain driven term extraction is a pivotal task in natural language processing, facilitating information retrieval, document summarization, and content categorization. This review focuses on keyword extraction methods, emphasizing the use of three major Large Language Models(LLMs): Llama2-7B, GPT-3.5, and Falcon-7B. We employed a custom Python package to interface with these LLMs, simplifying keyword extraction. Our study, utilizing the Inspec and PubMed datasets, evaluates the performance of these models. The Jaccard similarity index was used for assessment, yielding scores of 0.64 (Inspec) and 0.21 (PubMed) for GPT-3.5, 0.40 and 0.17 for Llama2-7B, and 0.23 and 0.12 for Falcon-7B. This paper underlines the role of prompt engineering in LLMs for better keyword extraction and discusses the impact of hallucination in LLMs on result evaluation. It also sheds light on the challenges in using LLMs for keyword extraction, including model complexity, resource demands, and optimization techniques.
Read more4/4/2024