Fact Finder -- Enhancing Domain Expertise of Large Language Models by Incorporating Knowledge Graphs

0
Sign in to get full access
Overview
- This paper explores how to enhance the domain expertise of large language models by incorporating knowledge graphs.
- The researchers developed a system called "Fact Finder" that leverages structured knowledge from knowledge graphs to improve the factual accuracy and domain-specific capabilities of language models.
- The paper presents experiments evaluating Fact Finder's performance on various tasks compared to standard language models.
Plain English Explanation
The paper discusses a way to make large language models, like those used in chatbots and virtual assistants, more knowledgeable about specific topics. Language models are trained on vast amounts of text data, which allows them to understand and generate human-like language. However, they can sometimes lack deep expertise in particular domains.
The researchers created a system called "Fact Finder" that combines the language understanding capabilities of these models with structured knowledge from knowledge graphs. Knowledge graphs are databases that store information about concepts and the relationships between them. By integrating this factual knowledge, the researchers aimed to enhance the domain expertise of the language models.
In their experiments, the researchers evaluated how well Fact Finder performed on tasks that require in-depth knowledge, such as answering questions about a specific topic or summarizing key information. They found that the Fact Finder system was able to outperform standard language models, demonstrating the benefits of combining language understanding with structured knowledge.
Technical Explanation
The paper presents the "Fact Finder" system, which integrates knowledge graphs into large language models to enhance their domain-specific expertise. The researchers first pre-train a base language model on a large corpus of text data. They then fine-tune this model using a knowledge graph relevant to the target domain, such as a medical knowledge graph for healthcare-related tasks.
The key components of Fact Finder are:
- Knowledge Graph Encoding: The researchers develop techniques to effectively encode the knowledge graph structure and entity information into the language model.
- Knowledge-Augmented Fine-Tuning: The language model is further fine-tuned on the knowledge-enriched data, allowing it to learn from the structured knowledge in the graph.
- Knowledge-Aware Inference: During inference, the system leverages the encoded knowledge graph to improve the model's factual accuracy and domain-specific capabilities.
The paper evaluates Fact Finder on a range of tasks, including question answering, fact checking, and document summarization. The results demonstrate that the Fact Finder system consistently outperforms standard language models, highlighting the benefits of incorporating structured knowledge to enhance domain expertise.
Critical Analysis
The paper presents a compelling approach to improving the factual accuracy and domain-specific capabilities of large language models. By leveraging knowledge graphs, the Fact Finder system addresses an important limitation of these models, which can sometimes struggle with tasks that require in-depth, contextual knowledge.
One potential limitation of the research is the reliance on pre-existing knowledge graphs. The performance of the Fact Finder system may be constrained by the coverage and quality of the available knowledge graphs. As the authors mention, further research is needed to explore techniques for dynamically updating or efficiently infusing knowledge into the language models.
Additionally, the paper does not provide a detailed analysis of the computational and memory overhead introduced by the knowledge graph integration. As language models become larger and more complex, the scalability and efficiency of such hybrid approaches will be an important consideration.
Overall, the Fact Finder system represents a promising step forward in enhancing the domain expertise of large language models. The research highlights the potential benefits of combining language understanding with structured knowledge, and encourages further exploration of this area.
Conclusion
This paper presents the Fact Finder system, which incorporates knowledge graphs into large language models to improve their factual accuracy and domain-specific capabilities. The results demonstrate that this approach can outperform standard language models on tasks that require in-depth knowledge, such as question answering and document summarization.
The research highlights the importance of combining language understanding with structured knowledge to address the limitations of current language models. As these models continue to play a growing role in various applications, the ability to enhance their domain expertise will be crucial for ensuring their reliability and usefulness in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fact Finder -- Enhancing Domain Expertise of Large Language Models by Incorporating Knowledge Graphs
Daniel Steinigen, Roman Teucher, Timm Heine Ruland, Max Rudat, Nicolas Flores-Herr, Peter Fischer, Nikola Milosevic, Christopher Schymura, Angelo Ziletti
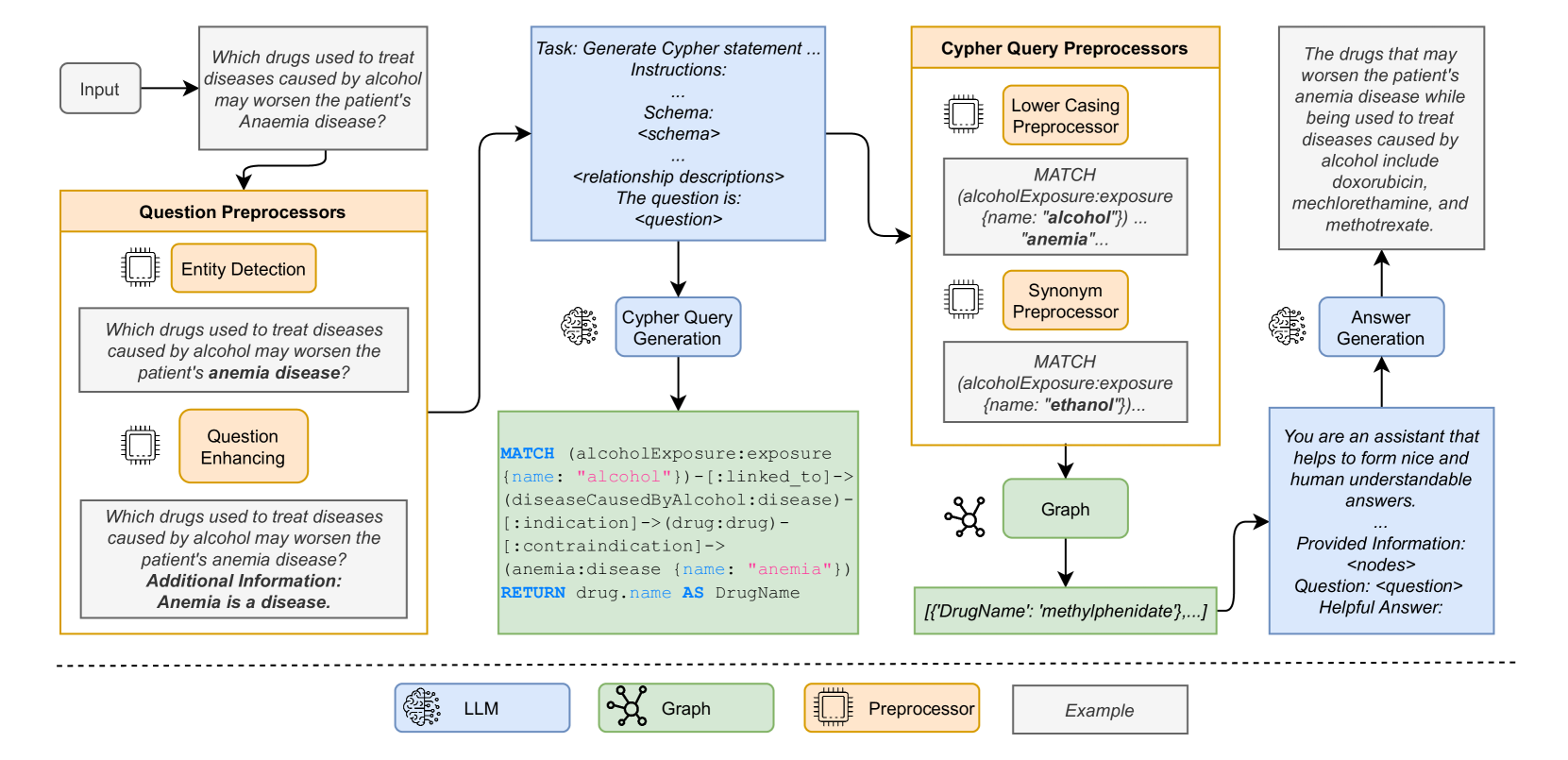
Recent advancements in Large Language Models (LLMs) have showcased their proficiency in answering natural language queries. However, their effectiveness is hindered by limited domain-specific knowledge, raising concerns about the reliability of their responses. We introduce a hybrid system that augments LLMs with domain-specific knowledge graphs (KGs), thereby aiming to enhance factual correctness using a KG-based retrieval approach. We focus on a medical KG to demonstrate our methodology, which includes (1) pre-processing, (2) Cypher query generation, (3) Cypher query processing, (4) KG retrieval, and (5) LLM-enhanced response generation. We evaluate our system on a curated dataset of 69 samples, achieving a precision of 78% in retrieving correct KG nodes. Our findings indicate that the hybrid system surpasses a standalone LLM in accuracy and completeness, as verified by an LLM-as-a-Judge evaluation method. This positions the system as a promising tool for applications that demand factual correctness and completeness, such as target identification -- a critical process in pinpointing biological entities for disease treatment or crop enhancement. Moreover, its intuitive search interface and ability to provide accurate responses within seconds make it well-suited for time-sensitive, precision-focused research contexts. We publish the source code together with the dataset and the prompt templates used.
Read more8/7/2024

0
Efficient Knowledge Infusion via KG-LLM Alignment
Zhouyu Jiang, Ling Zhong, Mengshu Sun, Jun Xu, Rui Sun, Hui Cai, Shuhan Luo, Zhiqiang Zhang
To tackle the problem of domain-specific knowledge scarcity within large language models (LLMs), knowledge graph-retrievalaugmented method has been proven to be an effective and efficient technique for knowledge infusion. However, existing approaches face two primary challenges: knowledge mismatch between public available knowledge graphs and the specific domain of the task at hand, and poor information compliance of LLMs with knowledge graphs. In this paper, we leverage a small set of labeled samples and a large-scale corpus to efficiently construct domain-specific knowledge graphs by an LLM, addressing the issue of knowledge mismatch. Additionally, we propose a three-stage KG-LLM alignment strategyto enhance the LLM's capability to utilize information from knowledge graphs. We conduct experiments with a limited-sample setting on two biomedical question-answering datasets, and the results demonstrate that our approach outperforms existing baselines.
Read more6/7/2024
0
KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques
Rui Yang, Haoran Liu, Edison Marrese-Taylor, Qingcheng Zeng, Yu He Ke, Wanxin Li, Lechao Cheng, Qingyu Chen, James Caverlee, Yutaka Matsuo, Irene Li
Large language models (LLMs) have demonstrated impressive generative capabilities with the potential to innovate in medicine. However, the application of LLMs in real clinical settings remains challenging due to the lack of factual consistency in the generated content. In this work, we develop an augmented LLM framework, KG-Rank, which leverages a medical knowledge graph (KG) along with ranking and re-ranking techniques, to improve the factuality of long-form question answering (QA) in the medical domain. Specifically, when receiving a question, KG-Rank automatically identifies medical entities within the question and retrieves the related triples from the medical KG to gather factual information. Subsequently, KG-Rank innovatively applies multiple ranking techniques to refine the ordering of these triples, providing more relevant and precise information for LLM inference. To the best of our knowledge, KG-Rank is the first application of KG combined with ranking models in medical QA specifically for generating long answers. Evaluation on four selected medical QA datasets demonstrates that KG-Rank achieves an improvement of over 18% in ROUGE-L score. Additionally, we extend KG-Rank to open domains, including law, business, music, and history, where it realizes a 14% improvement in ROUGE-L score, indicating the effectiveness and great potential of KG-Rank.
Read more7/8/2024
💬
0
Combining Knowledge Graphs and Large Language Models
Amanda Kau, Xuzeng He, Aishwarya Nambissan, Aland Astudillo, Hui Yin, Amir Aryani
In recent years, Natural Language Processing (NLP) has played a significant role in various Artificial Intelligence (AI) applications such as chatbots, text generation, and language translation. The emergence of large language models (LLMs) has greatly improved the performance of these applications, showing astonishing results in language understanding and generation. However, they still show some disadvantages, such as hallucinations and lack of domain-specific knowledge, that affect their performance in real-world tasks. These issues can be effectively mitigated by incorporating knowledge graphs (KGs), which organise information in structured formats that capture relationships between entities in a versatile and interpretable fashion. Likewise, the construction and validation of KGs present challenges that LLMs can help resolve. The complementary relationship between LLMs and KGs has led to a trend that combines these technologies to achieve trustworthy results. This work collected 28 papers outlining methods for KG-powered LLMs, LLM-based KGs, and LLM-KG hybrid approaches. We systematically analysed and compared these approaches to provide a comprehensive overview highlighting key trends, innovative techniques, and common challenges. This synthesis will benefit researchers new to the field and those seeking to deepen their understanding of how KGs and LLMs can be effectively combined to enhance AI applications capabilities.
Read more7/10/2024