Enhancing Robustness in Large Language Models: Prompting for Mitigating the Impact of Irrelevant Information

0

Sign in to get full access
Overview
- Large language models (LLMs) have become powerful tools for various tasks, but their robustness to irrelevant information is a concern.
- This paper explores prompting techniques to mitigate the impact of irrelevant information on LLM performance, particularly in arithmetic reasoning tasks.
- The research aims to enhance the robustness of LLMs by improving their ability to focus on relevant information and disregard irrelevant details.
Plain English Explanation
Large language models (LLMs) are advanced AI systems that can understand and generate human-like text. While these models have become incredibly capable, they can sometimes be influenced by irrelevant information when performing tasks. This can be a problem, especially in critical applications like arithmetic reasoning, where the model needs to focus on the relevant numbers and operations.
The researchers in this paper explored ways to make LLMs more robust to irrelevant information. They experimented with different "prompts" - the instructions or context given to the model before it generates a response. By carefully crafting these prompts, the researchers were able to help the LLMs concentrate on the important details and ignore the irrelevant ones, leading to better performance on arithmetic reasoning tasks.
The key idea is to train the LLMs to be more discerning - to distinguish between relevant and irrelevant information, and to prioritize the relevant parts when generating their answers. This can be particularly useful in real-world scenarios where there is often a lot of extraneous information that could potentially distract the model.
Overall, this research represents an important step towards making LLMs more robust and reliable, which is crucial as they become more widely adopted in various applications.
Technical Explanation
The paper explores techniques to enhance the robustness of large language models (LLMs) in the context of arithmetic reasoning tasks. The researchers investigate the impact of irrelevant information on the performance of LLMs and propose prompting strategies to mitigate this issue.
The study involves designing prompts that guide the LLMs to focus on the relevant information and disregard irrelevant details. The researchers experiment with different prompt configurations, such as providing explicit instructions to consider only the relevant information or including contextual cues to highlight the important aspects of the task.
Through a series of experiments, the paper demonstrates that carefully crafted prompts can significantly improve the LLMs' ability to perform arithmetic reasoning tasks in the presence of irrelevant information. The findings suggest that prompting can be a powerful tool for enhancing the robustness of LLMs, allowing them to better filter out irrelevant details and concentrate on the key elements required for the task at hand.
The researchers also analyze the performance of LLMs across different levels of irrelevant information and provide insights into the model's behavior and limitations. This analysis helps identify the strengths and weaknesses of the proposed prompting strategies, informing future research and development efforts in this area.
Critical Analysis
The paper presents a promising approach to improving the robustness of large language models, but it also highlights some potential limitations and areas for further exploration.
One potential concern is the generalizability of the findings. The experiments are primarily focused on arithmetic reasoning tasks, and it's unclear whether the same prompting strategies would be equally effective in other domains or tasks. Extending the research to a broader range of applications could provide a more comprehensive understanding of the approach's applicability.
Additionally, the paper does not delve deeply into the underlying mechanisms by which the prompts influence the LLMs' behavior. A more detailed investigation into the cognitive and architectural factors that contribute to the observed improvements could lead to further refinements and advancements in the prompting techniques.
Another area for further research could be the exploration of more automated or adaptive prompting strategies. The current approach relies on manually crafted prompts, which may not scale well as the complexity and diversity of tasks increase. Developing methods to automatically generate or dynamically adjust prompts based on the task and model characteristics could enhance the practical applicability of the proposed techniques.
Overall, the research presented in this paper represents a valuable contribution to the field of large language model robustness. The insights gained from this work can inform future efforts to develop more reliable and trustworthy AI systems capable of handling real-world complexities and challenges.
Conclusion
This paper explores the use of prompting techniques to enhance the robustness of large language models (LLMs) in the context of arithmetic reasoning tasks. The researchers demonstrate that carefully crafted prompts can help LLMs focus on the relevant information and disregard irrelevant details, leading to improved performance.
The findings of this study have important implications for the development of more reliable and trustworthy AI systems. As LLMs become increasingly prevalent in various applications, ensuring their robustness to irrelevant information is crucial. The prompting strategies proposed in this paper offer a promising approach to addressing this challenge, paving the way for more robust and well-behaved LLMs that can operate effectively in complex, real-world scenarios.
Further research is needed to explore the generalizability of the findings, investigate the underlying mechanisms driving the observed improvements, and develop more automated or adaptive prompting techniques. Nonetheless, this work represents a significant step forward in enhancing the robustness of large language models, a critical requirement for the widespread adoption and responsible deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Robustness in Large Language Models: Prompting for Mitigating the Impact of Irrelevant Information
Ming Jiang, Tingting Huang, Biao Guo, Yao Lu, Feng Zhang
In recent years, Large language models (LLMs) have garnered significant attention due to their superior performance in complex reasoning tasks. However, recent studies may diminish their reasoning capabilities markedly when problem descriptions contain irrelevant information, even with the use of advanced prompting techniques. To further investigate this issue, a dataset of primary school mathematics problems containing irrelevant information, named GSMIR, was constructed. Testing prominent LLMs and prompting techniques on this dataset revealed that while LLMs can identify irrelevant information, they do not effectively mitigate the interference it causes once identified. A novel automatic construction method, ATF, which enhances the ability of LLMs to identify and self-mitigate the influence of irrelevant information, is proposed to address this shortcoming. This method operates in two steps: first, analysis of irrelevant information, followed by its filtering. The ATF method, as demonstrated by experimental results, significantly improves the reasoning performance of LLMs and prompting techniques, even in the presence of irrelevant information on the GSMIR dataset.
Read more8/21/2024

0
Towards Building a Robust Knowledge Intensive Question Answering Model with Large Language Models
Xingyun Hong, Yan Shao, Zhilin Wang, Manni Duan, Jin Xiongnan
The development of LLMs has greatly enhanced the intelligence and fluency of question answering, while the emergence of retrieval enhancement has enabled models to better utilize external information. However, the presence of noise and errors in retrieved information poses challenges to the robustness of LLMs. In this work, to evaluate the model's performance under multiple interferences, we first construct a dataset based on machine reading comprehension datasets simulating various scenarios, including critical information absence, noise, and conflicts. To address the issue of model accuracy decline caused by noisy external information, we propose a data augmentation-based fine-tuning method to enhance LLM's robustness against noise. Additionally, contrastive learning approach is utilized to preserve the model's discrimination capability of external information. We have conducted experiments on both existing LLMs and our approach, the results are evaluated by GPT-4, which indicates that our proposed methods improve model robustness while strengthening the model's discrimination capability.
Read more9/19/2024

0
How Easily do Irrelevant Inputs Skew the Responses of Large Language Models?
Siye Wu, Jian Xie, Jiangjie Chen, Tinghui Zhu, Kai Zhang, Yanghua Xiao
By leveraging the retrieval of information from external knowledge databases, Large Language Models (LLMs) exhibit enhanced capabilities for accomplishing many knowledge-intensive tasks. However, due to the inherent flaws of current retrieval systems, there might exist irrelevant information within those retrieving top-ranked passages. In this work, we present a comprehensive investigation into the robustness of LLMs to different types of irrelevant information under various conditions. We initially introduce a framework to construct high-quality irrelevant information that ranges from semantically unrelated, partially related, and related to questions. Furthermore, our analysis demonstrates that the constructed irrelevant information not only scores highly on similarity metrics, being highly retrieved by existing systems, but also bears semantic connections to the context. Our investigation reveals that current LLMs still face challenges in discriminating highly semantically related information and can be easily distracted by these irrelevant yet misleading content. Besides, we also find that current solutions for handling irrelevant information have limitations in improving the robustness of LLMs to such distractions. All the resources are available on GitHub at https://github.com/Di-viner/LLM-Robustness-to-Irrelevant-Information.
Read more9/14/2024
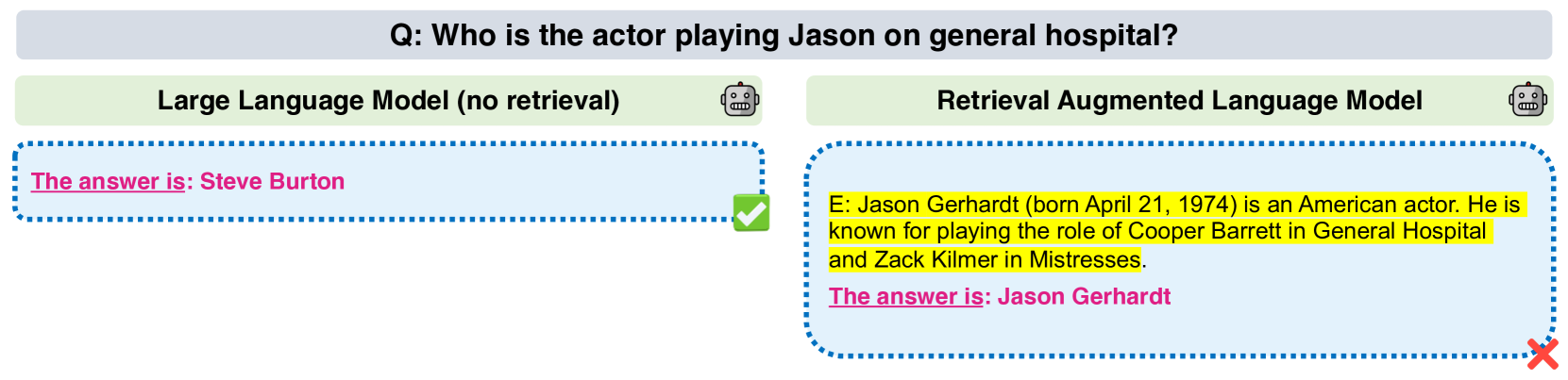
0
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Ori Yoran, Tomer Wolfson, Ori Ram, Jonathan Berant
Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
Read more5/7/2024