How Easily do Irrelevant Inputs Skew the Responses of Large Language Models?

0

Sign in to get full access
Overview
- This paper examines how easily large language models can be influenced by irrelevant inputs.
- The researchers conducted experiments to test the robustness of language models to skewed or irrelevant information.
- The findings have implications for the reliability and trustworthiness of language models in real-world applications.
Plain English Explanation
Language models are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes be swayed by irrelevant or misleading information provided in the input. This paper investigates how easily large language models can have their responses skewed by such irrelevant inputs.
The researchers ran experiments where they fed language models prompts that contained irrelevant information, like random words or unrelated facts. They then analyzed how the models' outputs changed compared to when they were given more relevant inputs. The goal was to understand how robust these models are to distracting or misleading inputs, and whether they can reliably focus on the core task at hand.
The results showed that large language models can indeed be quite susceptible to skewing from irrelevant inputs. Even small amounts of extraneous information were enough to noticeably alter the models' responses. This raises concerns about the reliability of these models in real-world settings, where they may encounter all sorts of irrelevant or misleading data.
Overall, this research highlights an important limitation of current large language models. While they are incredibly capable in many ways, their vulnerability to irrelevant inputs suggests they may not be as trustworthy or dependable as one might hope, at least in their present form. Further work is needed to improve the robustness of these models and ensure they can stay focused on the task at hand, even when faced with distractions.
Technical Explanation
The paper explores the phenomenon of "input skew" in large language models - the tendency for these models to have their responses biased or altered by the inclusion of irrelevant or misleading information in the input prompts.
The researchers conducted a series of experiments using several state-of-the-art language models, including GPT-3 and T5. They generated prompts that contained a mix of relevant and irrelevant information, and analyzed how the models' outputs changed compared to prompts with only relevant content.
The experiments involved inserting random words, unrelated facts, or tangential context into the input prompts. The researchers then used both automatic and human evaluation metrics to assess the degree to which the models' responses were skewed or influenced by the irrelevant information.
The results showed that even small amounts of irrelevant content were sufficient to noticeably alter the language models' outputs. The models seemed to latch onto the extraneous information and incorporate it into their responses, even when it was clearly not relevant to the task at hand.
This input skew effect was observed across a range of different language modeling tasks, including text generation, question answering, and commonsense reasoning. The magnitude of the skew varied depending on factors like the model architecture, the type of irrelevant information, and the specific task.
Overall, the findings highlight a key limitation of current large language models - their susceptibility to being influenced by irrelevant inputs. This raises concerns about the reliability and trustworthiness of these models in real-world applications, where they may encounter all kinds of noisy, distracting, or misleading information.
Critical Analysis
The paper provides a thorough experimental investigation of the input skew phenomenon, and the results are quite concerning from the perspective of real-world deployment of language models. The researchers did a commendable job of testing the models across a variety of tasks and input conditions.
That said, the paper does not delve deeply into potential explanations for why language models exhibit this vulnerability. It would be valuable to have a more in-depth analysis of the underlying mechanisms and architectural factors that contribute to this behavior. A better understanding of the root causes could help inform strategies for mitigating the problem.
Additionally, the paper does not address the generalizability of the findings. The experiments were conducted on a limited set of language models and tasks - it's unclear how the results would scale to the ever-growing landscape of large language models and their diverse applications. Further research is needed to understand the breadth and consistency of the input skew phenomenon.
Another limitation is that the paper focuses solely on the negative impacts of input skew, without considering potential upsides or beneficial applications. In some cases, the ability of language models to latch onto tangential information could be leveraged for creative or exploratory purposes. The paper could have provided a more balanced perspective on the implications of this behavior.
Overall, this research makes an important contribution by drawing attention to a critical weakness in current large language models. While the findings are concerning, they also present an opportunity for the field to develop more robust and reliable AI systems that are less susceptible to external influences.
Conclusion
This paper offers a thought-provoking examination of how easily the responses of large language models can be skewed by the inclusion of irrelevant inputs. The experimental results demonstrate that these powerful AI systems are surprisingly vulnerable to having their outputs biased or altered by distracting or misleading information, even in small amounts.
The implications of this finding are significant, as it calls into question the reliability and trustworthiness of language models in real-world applications where they may encounter all kinds of noisy, tangential, or adversarial data. The research highlights an important limitation that must be addressed for these models to be safely and responsibly deployed.
While the paper raises valid concerns, it also presents an opportunity for the field of AI to develop more robust and discerning language models that can maintain focus on the core task at hand, even in the face of distractions. Continued research into the underlying mechanisms of input skew, as well as strategies for mitigating it, will be crucial for unlocking the full potential of large language models and ensuring they can be trusted to provide accurate and reliable outputs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How Easily do Irrelevant Inputs Skew the Responses of Large Language Models?
Siye Wu, Jian Xie, Jiangjie Chen, Tinghui Zhu, Kai Zhang, Yanghua Xiao
By leveraging the retrieval of information from external knowledge databases, Large Language Models (LLMs) exhibit enhanced capabilities for accomplishing many knowledge-intensive tasks. However, due to the inherent flaws of current retrieval systems, there might exist irrelevant information within those retrieving top-ranked passages. In this work, we present a comprehensive investigation into the robustness of LLMs to different types of irrelevant information under various conditions. We initially introduce a framework to construct high-quality irrelevant information that ranges from semantically unrelated, partially related, and related to questions. Furthermore, our analysis demonstrates that the constructed irrelevant information not only scores highly on similarity metrics, being highly retrieved by existing systems, but also bears semantic connections to the context. Our investigation reveals that current LLMs still face challenges in discriminating highly semantically related information and can be easily distracted by these irrelevant yet misleading content. Besides, we also find that current solutions for handling irrelevant information have limitations in improving the robustness of LLMs to such distractions. All the resources are available on GitHub at https://github.com/Di-viner/LLM-Robustness-to-Irrelevant-Information.
Read more9/14/2024

0
Enhancing Robustness in Large Language Models: Prompting for Mitigating the Impact of Irrelevant Information
Ming Jiang, Tingting Huang, Biao Guo, Yao Lu, Feng Zhang
In recent years, Large language models (LLMs) have garnered significant attention due to their superior performance in complex reasoning tasks. However, recent studies may diminish their reasoning capabilities markedly when problem descriptions contain irrelevant information, even with the use of advanced prompting techniques. To further investigate this issue, a dataset of primary school mathematics problems containing irrelevant information, named GSMIR, was constructed. Testing prominent LLMs and prompting techniques on this dataset revealed that while LLMs can identify irrelevant information, they do not effectively mitigate the interference it causes once identified. A novel automatic construction method, ATF, which enhances the ability of LLMs to identify and self-mitigate the influence of irrelevant information, is proposed to address this shortcoming. This method operates in two steps: first, analysis of irrelevant information, followed by its filtering. The ATF method, as demonstrated by experimental results, significantly improves the reasoning performance of LLMs and prompting techniques, even in the presence of irrelevant information on the GSMIR dataset.
Read more8/21/2024
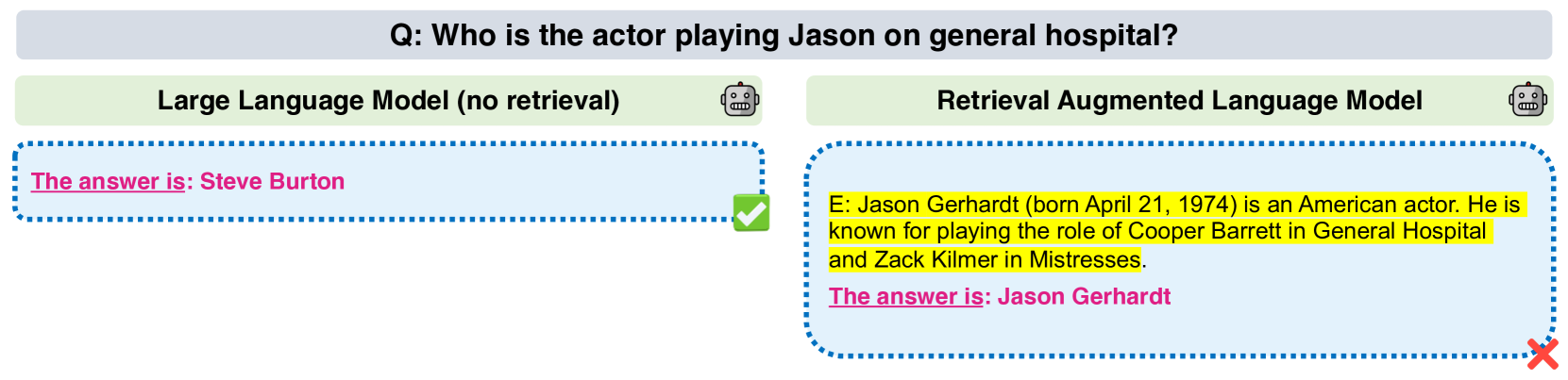
0
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Ori Yoran, Tomer Wolfson, Ori Ram, Jonathan Berant
Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
Read more5/7/2024
💬
0
Assessing Implicit Retrieval Robustness of Large Language Models
Xiaoyu Shen, Rexhina Blloshmi, Dawei Zhu, Jiahuan Pei, Wei Zhang
Retrieval-augmented generation has gained popularity as a framework to enhance large language models with external knowledge. However, its effectiveness hinges on the retrieval robustness of the model. If the model lacks retrieval robustness, its performance is constrained by the accuracy of the retriever, resulting in significant compromises when the retrieved context is irrelevant. In this paper, we evaluate the implicit retrieval robustness of various large language models, instructing them to directly output the final answer without explicitly judging the relevance of the retrieved context. Our findings reveal that fine-tuning on a mix of gold and distracting context significantly enhances the model's robustness to retrieval inaccuracies, while still maintaining its ability to extract correct answers when retrieval is accurate. This suggests that large language models can implicitly handle relevant or irrelevant retrieved context by learning solely from the supervision of the final answer in an end-to-end manner. Introducing an additional process for explicit relevance judgment can be unnecessary and disrupts the end-to-end approach.
Read more6/27/2024