Enhancing SLM via ChatGPT and Dataset Augmentation

0

Sign in to get full access
Overview
- Small language models have limited capabilities compared to large language models like GPT-3
- This paper explores techniques to enhance the performance of small language models, including:
- Knowledge distillation from a large model like ChatGPT
- Dataset augmentation using synthetic data generation
- Fine-tuning with rationales
Plain English Explanation
The paper focuses on improving the capabilities of small language models, which are more compact and efficient than massive models like GPT-3 but have more limited abilities. The researchers tested several techniques to enhance the performance of these smaller models:
-
Knowledge Distillation from ChatGPT: They took the knowledge and skills learned by the powerful ChatGPT model and distilled that into the smaller model, essentially teaching it what ChatGPT had learned.
-
Dataset Augmentation: The researchers generated synthetic data, or artificial text, to expand the training dataset for the small model. This helped the model learn from a wider variety of examples.
-
Fine-Tuning with Rationales: When fine-tuning the model on specific tasks, they provided it with "rationales" - explanations for the correct answers. This gave the model more context to learn from.
The goal was to see if these techniques could boost the capabilities of the smaller model, making it more powerful and useful without the huge computational requirements of the largest language models. The paper explores the results of these approaches and their potential benefits.
Technical Explanation
The paper investigates methods to enhance the performance of small language models, which have fewer parameters and are less computationally intensive than large language models like GPT-3. The researchers tested three main techniques:
-
Knowledge Distillation: They used a process called knowledge distillation to transfer knowledge from a large pre-trained model (in this case, ChatGPT) into the smaller model. This allowed the small model to benefit from the learned skills and knowledge of the larger model.
-
Dataset Augmentation: To expand the training data for the small model, the researchers generated synthetic examples using techniques like paraphrasing and data interpolation. This augmented dataset provided the model with more diverse training examples.
-
Fine-Tuning with Rationales: When fine-tuning the small model on specific tasks, the researchers provided "rationales" - explanations of the correct answers. This additional contextual information helped the model learn more effectively during the fine-tuning process.
The paper evaluates the performance of the small model using these techniques on a range of language tasks, comparing it to the baseline small model as well as the larger ChatGPT model. The results indicate that the combination of these methods can indeed enhance the capabilities of the small model, narrowing the gap with the more powerful large language models.
Critical Analysis
The paper presents a thorough and well-designed study, exploring multiple techniques to improve small language models. The researchers acknowledge some limitations, such as the potential for overfitting when using synthetic data and the challenge of scaling rationale generation to large datasets.
One area for further exploration could be the investigation of more efficient or automated methods for generating high-quality synthetic data and rationales, as the current approaches may be labor-intensive. Additionally, the paper does not delve into the potential risks or societal implications of enhancing small language models, such as the potential for misuse or the propagation of biases.
Overall, the paper makes a valuable contribution to the field of language model optimization, demonstrating promising techniques to improve the performance of smaller, more resource-efficient models. As the demand for AI applications grows, this research could have important implications for making advanced natural language processing capabilities more accessible and deployable across a wider range of use cases.
Conclusion
This paper presents a comprehensive study on enhancing the performance of small language models through the use of knowledge distillation, dataset augmentation, and fine-tuning with rationales. The results indicate that these techniques can effectively boost the capabilities of compact, computationally efficient models, narrowing the gap with larger, more powerful language models.
The findings have significant implications for the development of AI systems that can deliver advanced natural language processing capabilities while maintaining a smaller footprint and lower resource requirements. As the demand for AI-powered applications continues to grow, this research offers a path forward for making these technologies more accessible and deployable across a wider range of use cases, from edge computing to mobile devices.
The paper's contribution to the field of language model optimization serves as an important step towards building a more diverse and capable ecosystem of AI models, catering to the varying needs and constraints of different applications and deployment scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Enhancing SLM via ChatGPT and Dataset Augmentation
Tom Pieper, Mohamad Ballout, Ulf Krumnack, Gunther Heidemann, Kai-Uwe Kuhnberger
This paper explores the enhancement of small language models through strategic dataset augmentation via ChatGPT-3.5-Turbo, in the domain of Natural Language Inference (NLI). By employing knowledge distillation-based techniques and synthetic dataset augmentation, we aim to bridge the performance gap between large language models (LLMs) and small language models (SLMs) without the immense cost of human annotation. Our methods involve two forms of rationale generation--information extraction and informed reasoning--to enrich the ANLI dataset. We then fine-tune T5-Small on these augmented datasets, evaluating its performance against an established benchmark. Our findings reveal that the incorporation of synthetic rationales significantly improves the model's ability to comprehend natural language, leading to 1.3% and 2.3% higher classification accuracy, respectively, on the ANLI dataset, demonstrating the potential of leveraging LLMs for dataset augmentation. This approach not only enhances the performance of smaller models on complex tasks but also introduces a cost-effective method for fine-tuning smaller language models. By advancing our understanding of knowledge distillation and fine-tuning strategies, this work contributes to the ongoing effort to create more capable and efficient NLP systems.
Read more9/20/2024
📊
0
ChatGPT Based Data Augmentation for Improved Parameter-Efficient Debiasing of LLMs
Pengrui Han, Rafal Kocielnik, Adhithya Saravanan, Roy Jiang, Or Sharir, Anima Anandkumar
Large Language models (LLMs), while powerful, exhibit harmful social biases. Debiasing is often challenging due to computational costs, data constraints, and potential degradation of multi-task language capabilities. This work introduces a novel approach utilizing ChatGPT to generate synthetic training data, aiming to enhance the debiasing of LLMs. We propose two strategies: Targeted Prompting, which provides effective debiasing for known biases but necessitates prior specification of bias in question; and General Prompting, which, while slightly less effective, offers debiasing across various categories. We leverage resource-efficient LLM debiasing using adapter tuning and compare the effectiveness of our synthetic data to existing debiasing datasets. Our results reveal that: (1) ChatGPT can efficiently produce high-quality training data for debiasing other LLMs; (2) data produced via our approach surpasses existing datasets in debiasing performance while also preserving internal knowledge of a pre-trained LLM; and (3) synthetic data exhibits generalizability across categories, effectively mitigating various biases, including intersectional ones. These findings underscore the potential of synthetic data in advancing the fairness of LLMs with minimal retraining cost.
Read more9/17/2024
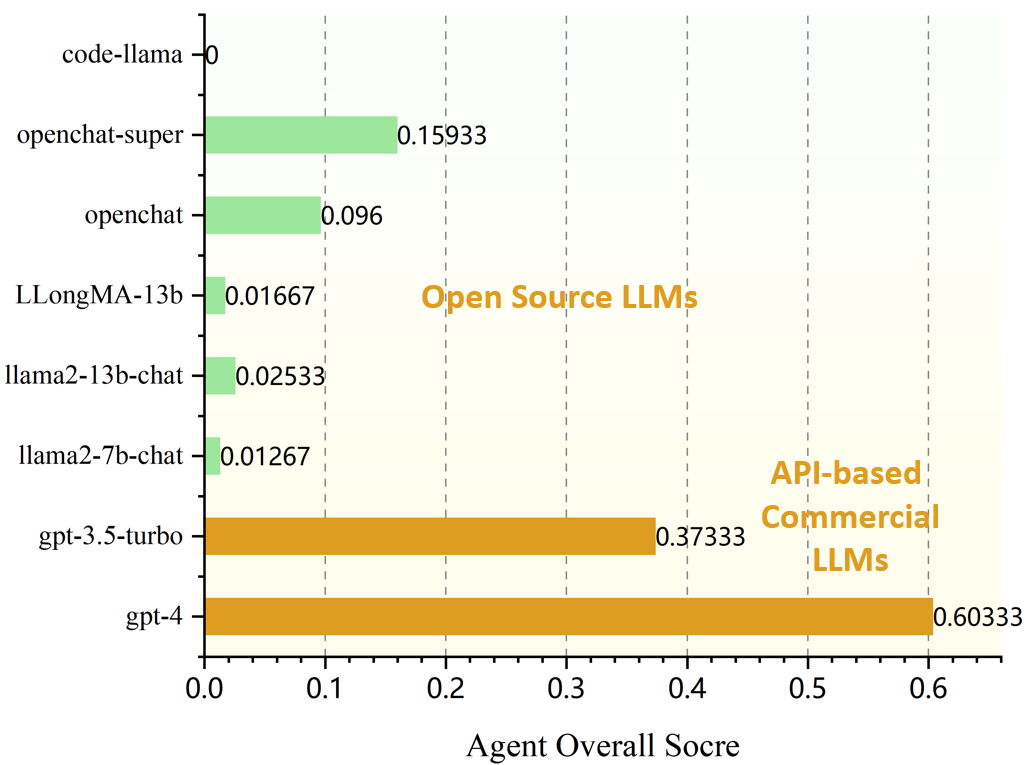
0
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Qinhao Zhou, Zihan Zhang, Xiang Xiang, Ke Wang, Yuchuan Wu, Yongbin Li
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
Read more4/1/2024

0
Can LLMs Augment Low-Resource Reading Comprehension Datasets? Opportunities and Challenges
Vinay Samuel, Houda Aynaou, Arijit Ghosh Chowdhury, Karthik Venkat Ramanan, Aman Chadha
Large Language Models (LLMs) have demonstrated impressive zero shot performance on a wide range of NLP tasks, demonstrating the ability to reason and apply commonsense. A relevant application is to use them for creating high quality synthetic datasets for downstream tasks. In this work, we probe whether GPT-4 can be used to augment existing extractive reading comprehension datasets. Automating data annotation processes has the potential to save large amounts of time, money and effort that goes into manually labelling datasets. In this paper, we evaluate the performance of GPT-4 as a replacement for human annotators for low resource reading comprehension tasks, by comparing performance after fine tuning, and the cost associated with annotation. This work serves to be the first analysis of LLMs as synthetic data augmenters for QA systems, highlighting the unique opportunities and challenges. Additionally, we release augmented versions of low resource datasets, that will allow the research community to create further benchmarks for evaluation of generated datasets.
Read more7/11/2024