Enhancing Source Code Security with LLMs: Demystifying The Challenges and Generating Reliable Repairs

0
🌿
Sign in to get full access
Overview
- Recent advancements in Artificial Intelligence (AI) and Large Language Models (LLMs) have accelerated progress, presenting challenges in establishing clear security guidelines.
- This paper identifies and describes three main technical challenges in the LLM security and software engineering literature: (i) Data Collection and Labeling, (ii) System Design and Learning, and (iii) Performance Evaluation.
- The paper introduces SecRepair, an instruction-based LLM system designed to reliably identify, describe, and automatically repair vulnerable source code.
- SecRepair uses reinforcement learning-based fine-tuning with a semantic reward to cater to the functionality and security aspects of the generated code.
Plain English Explanation
The paper explores the challenges of ensuring the security of large language models (LLMs), which are a type of artificial intelligence system that can generate human-like text. As these models become more advanced, it's becoming increasingly important to establish clear guidelines and best practices for their development and deployment, especially in areas like software security.
The researchers identify three main technical hurdles in this field: [1] collecting and labeling the data used to train these models, [2] designing the systems and learning algorithms to make them effective and reliable, and [3] properly evaluating their performance.
To address these challenges, the paper introduces a new system called SecRepair. This is an LLM-based tool that can automatically identify, describe, and fix vulnerabilities in computer code. SecRepair uses a novel training approach called reinforcement learning, which rewards the model for generating code that is both functionally correct and secure.
The researchers show that SecRepair outperforms other LLMs when it comes to repairing vulnerable code, achieving a 12% improvement in security. They also demonstrate that SecRepair can generate reliable, functional, and compilable security fixes for real-world test cases.
Technical Explanation
The paper focuses on the technical challenges of ensuring the security of large language models (LLMs) across the entire workflow, from data collection and labeling to system design and learning to performance evaluation.
To address these challenges, the authors introduce SecRepair, an instruction-based LLM system designed to reliably identify, describe, and automatically repair vulnerable source code. SecRepair uses a reinforcement learning-based fine-tuning approach with a semantic reward function that caters to both the functionality and security aspects of the generated code.
The researchers' empirical analysis shows that SecRepair achieves a 12% improvement in security code repair compared to other LLMs when trained using reinforcement learning. Furthermore, they demonstrate SecRepair's capabilities in generating reliable, functional, and compilable security code repairs against real-world test cases using automated evaluation metrics.
Critical Analysis
The paper provides a comprehensive overview of the technical challenges in ensuring the security of large language models (LLMs) and presents a novel approach to address these challenges. The authors' focus on the entire LLM workflow, from data preparation to model evaluation, is a strength of the research.
However, the paper does not fully address the potential limitations and caveats of the SecRepair system. For example, the researchers do not discuss the scalability of the system or its performance on a wider range of security vulnerabilities beyond the real-world test cases presented. Additionally, the paper could have explored the potential biases and ethical considerations that may arise from using an LLM-based system for security code repair.
Further research is needed to explore the long-term implications of using large language models for security-critical applications and to ensure that such systems are developed and deployed in a responsible and transparent manner.
Conclusion
This paper presents an important step forward in addressing the security challenges posed by the rapid advancements in large language models (LLMs). The introduction of the SecRepair system, which can reliably identify, describe, and automatically repair vulnerable source code, is a significant contribution to the field of software security.
The researchers' focus on the technical challenges across the entire LLM workflow and their use of reinforcement learning-based fine-tuning with a semantic reward function are particularly noteworthy. The empirical results demonstrating SecRepair's superior performance in security code repair are also promising.
However, the paper also highlights the need for further research to address the potential limitations and ethical considerations of using LLM-based systems for security-critical applications. As AI and language models continue to evolve, it will be crucial to establish clear guidelines and best practices to ensure the safety and reliability of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
Enhancing Source Code Security with LLMs: Demystifying The Challenges and Generating Reliable Repairs
Nafis Tanveer Islam, Joseph Khoury, Andrew Seong, Elias Bou-Harb, Peyman Najafirad
With the recent unprecedented advancements in Artificial Intelligence (AI) computing, progress in Large Language Models (LLMs) is accelerating rapidly, presenting challenges in establishing clear guidelines, particularly in the field of security. That being said, we thoroughly identify and describe three main technical challenges in the security and software engineering literature that spans the entire LLM workflow, namely; textbf{textit{(i)}} Data Collection and Labeling; textbf{textit{(ii)}} System Design and Learning; and textbf{textit{(iii)}} Performance Evaluation. Building upon these challenges, this paper introduces texttt{SecRepair}, an instruction-based LLM system designed to reliably textit{identify}, textit{describe}, and automatically textit{repair} vulnerable source code. Our system is accompanied by a list of actionable guides on textbf{textit{(i)}} Data Preparation and Augmentation Techniques; textbf{textit{(ii)}} Selecting and Adapting state-of-the-art LLM Models; textbf{textit{(iii)}} Evaluation Procedures. texttt{SecRepair} uses a reinforcement learning-based fine-tuning with a semantic reward that caters to the functionality and security aspects of the generated code. Our empirical analysis shows that texttt{SecRepair} achieves a textit{12}% improvement in security code repair compared to other LLMs when trained using reinforcement learning. Furthermore, we demonstrate the capabilities of texttt{SecRepair} in generating reliable, functional, and compilable security code repairs against real-world test cases using automated evaluation metrics.
Read more9/4/2024
💬
0
Security Code Review by Large Language Models
Jiaxin Yu, Peng Liang, Yujia Fu, Amjed Tahir, Mojtaba Shahin, Chong Wang, Yangxiao Cai
Security code review, as a time-consuming and labour-intensive process, typically requires integration with automated security defect detection tools to ensure code security. Despite the emergence of numerous security analysis tools, those tools face challenges in terms of their poor generalization, high false positive rates, and coarse detection granularity. A recent development with Large Language Models (LLMs) has made them a promising candidate to support security code review. To this end, we conducted the first empirical study to understand the capabilities of LLMs in security code review, delving into the performance, quality problems, and influential factors of LLMs to detect security defects in code reviews. Specifically, we compared the performance of 6 LLMs under five different prompts with the state-of-the-art static analysis tools to detect and analyze security defects. For the best-performing LLM, we conducted a linguistic analysis to explore quality problems in its responses, as well as a regression analysis to investigate the factors influencing its performance. The results are that: (1) existing pre-trained LLMs have limited capability in detecting security defects during code review but significantly outperform the state-of-the-art static analysis tools. (2) GPT-4 performs best among all LLMs when provided with a CWE list for reference. (3) GPT-4 makes few factual errors but frequently generates unnecessary content or responses that are not compliant with the task requirements given in the prompts. (4) GPT-4 is more adept at identifying security defects in code files with fewer tokens, containing functional logic and written by developers with less involvement in the project.
Read more6/11/2024

0
Is Your AI-Generated Code Really Safe? Evaluating Large Language Models on Secure Code Generation with CodeSecEval
Jiexin Wang, Xitong Luo, Liuwen Cao, Hongkui He, Hailin Huang, Jiayuan Xie, Adam Jatowt, Yi Cai
Large language models (LLMs) have brought significant advancements to code generation and code repair, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, raises the risk of inadvertently propagating security vulnerabilities. Despite numerous studies investigating the safety of code LLMs, there remains a gap in comprehensively addressing their security features. In this work, we aim to present a comprehensive study aimed at precisely evaluating and enhancing the security aspects of code LLMs. To support our research, we introduce CodeSecEval, a meticulously curated dataset designed to address 44 critical vulnerability types with 180 distinct samples. CodeSecEval serves as the foundation for the automatic evaluation of code models in two crucial tasks: code generation and code repair, with a strong emphasis on security. Our experimental results reveal that current models frequently overlook security issues during both code generation and repair processes, resulting in the creation of vulnerable code. In response, we propose different strategies that leverage vulnerability-aware information and insecure code explanations to mitigate these security vulnerabilities. Furthermore, our findings highlight that certain vulnerability types particularly challenge model performance, influencing their effectiveness in real-world applications. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.
Read more7/8/2024
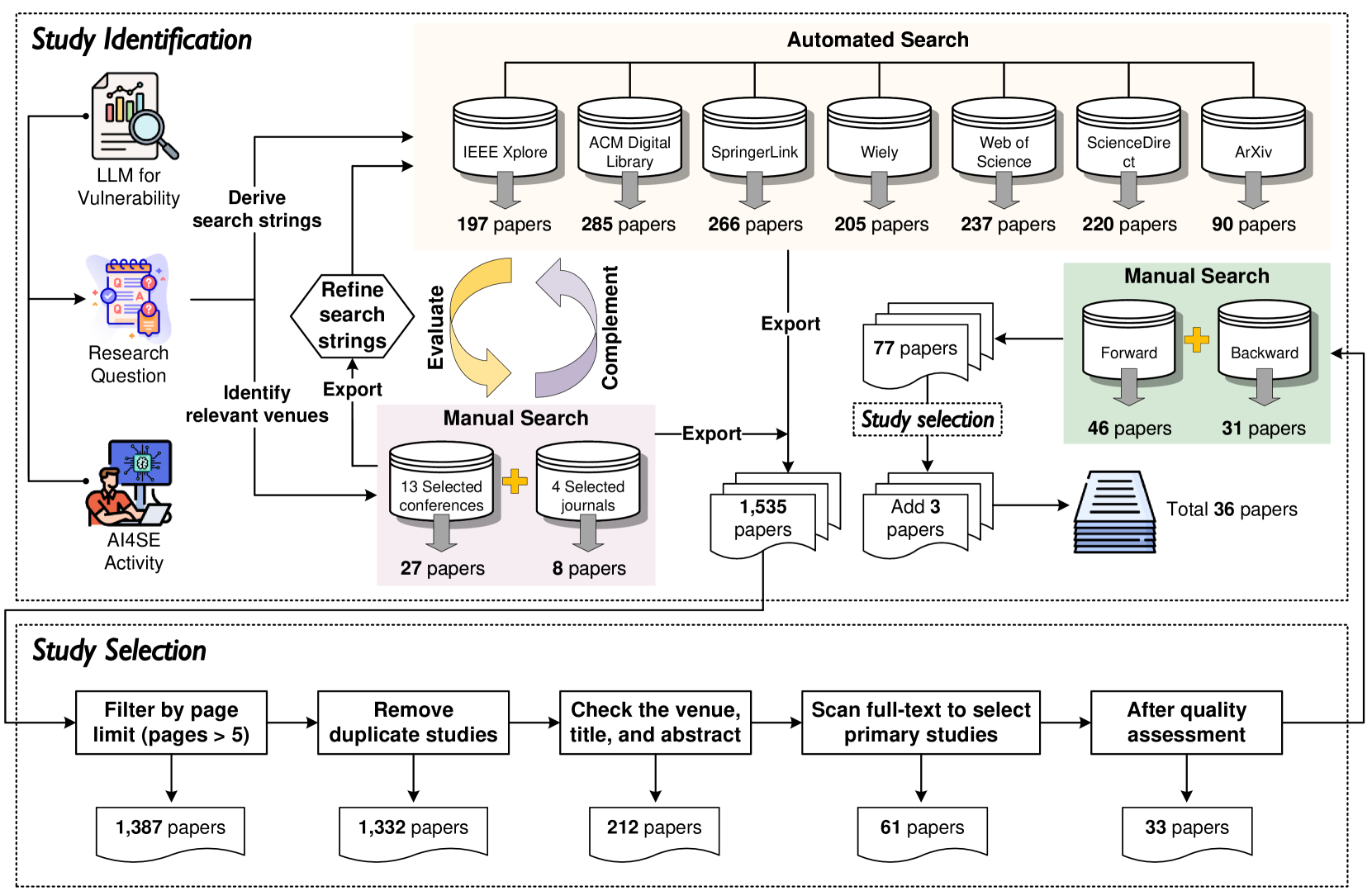
0
Large Language Model for Vulnerability Detection and Repair: Literature Review and Roadmap
Xin Zhou, Sicong Cao, Xiaobing Sun, David Lo
The significant advancements in Large Language Models (LLMs) have resulted in their widespread adoption across various tasks within Software Engineering (SE), including vulnerability detection and repair. Numerous recent studies have investigated the application of LLMs to enhance vulnerability detection and repair tasks. Despite the increasing research interest, there is currently no existing survey that focuses on the utilization of LLMs for vulnerability detection and repair. In this paper, we aim to bridge this gap by offering a systematic literature review of approaches aimed at improving vulnerability detection and repair through the utilization of LLMs. The review encompasses research work from leading SE, AI, and Security conferences and journals, covering 36 papers published at 21 distinct venues. By answering three key research questions, we aim to (1) summarize the LLMs employed in the relevant literature, (2) categorize various LLM adaptation techniques in vulnerability detection, and (3) classify various LLM adaptation techniques in vulnerability repair. Based on our findings, we have identified a series of challenges that still need to be tackled considering existing studies. Additionally, we have outlined a roadmap highlighting potential opportunities that we believe are pertinent and crucial for future research endeavors.
Read more4/4/2024