Harnessing the Power of LLMs in Source Code Vulnerability Detection

0
Sign in to get full access
Overview
- Explores the use of large language models (LLMs) for detecting vulnerabilities in source code
- Proposes a framework to leverage the power of LLMs for this task
- Evaluates the performance of LLM-based vulnerability detection on real-world codebases
Plain English Explanation
The paper investigates how large language models (LLMs) can be used to identify vulnerabilities in computer programs. Vulnerabilities are weaknesses in the code that could be exploited by attackers to gain unauthorized access or cause harm.
The researchers develop a framework that allows them to use LLMs, which are powerful AI models trained on vast amounts of text data, to analyze source code and detect potential vulnerabilities. This is an alternative to traditional vulnerability detection methods, which often rely on manually-crafted rules or pattern-matching algorithms.
The key idea is to "fine-tune" the LLM on a dataset of vulnerable and non-vulnerable code, so that it learns to recognize the patterns and characteristics of insecure code. Once trained, the LLM can then be applied to new, unseen code to predict whether it contains vulnerabilities.
The researchers evaluate their approach on real-world codebases and find that the LLM-based method outperforms traditional vulnerability detection tools in terms of accuracy and coverage. This suggests that LLMs have the potential to significantly improve the state of the art in software security and help developers identify and fix vulnerabilities more effectively.
Technical Explanation
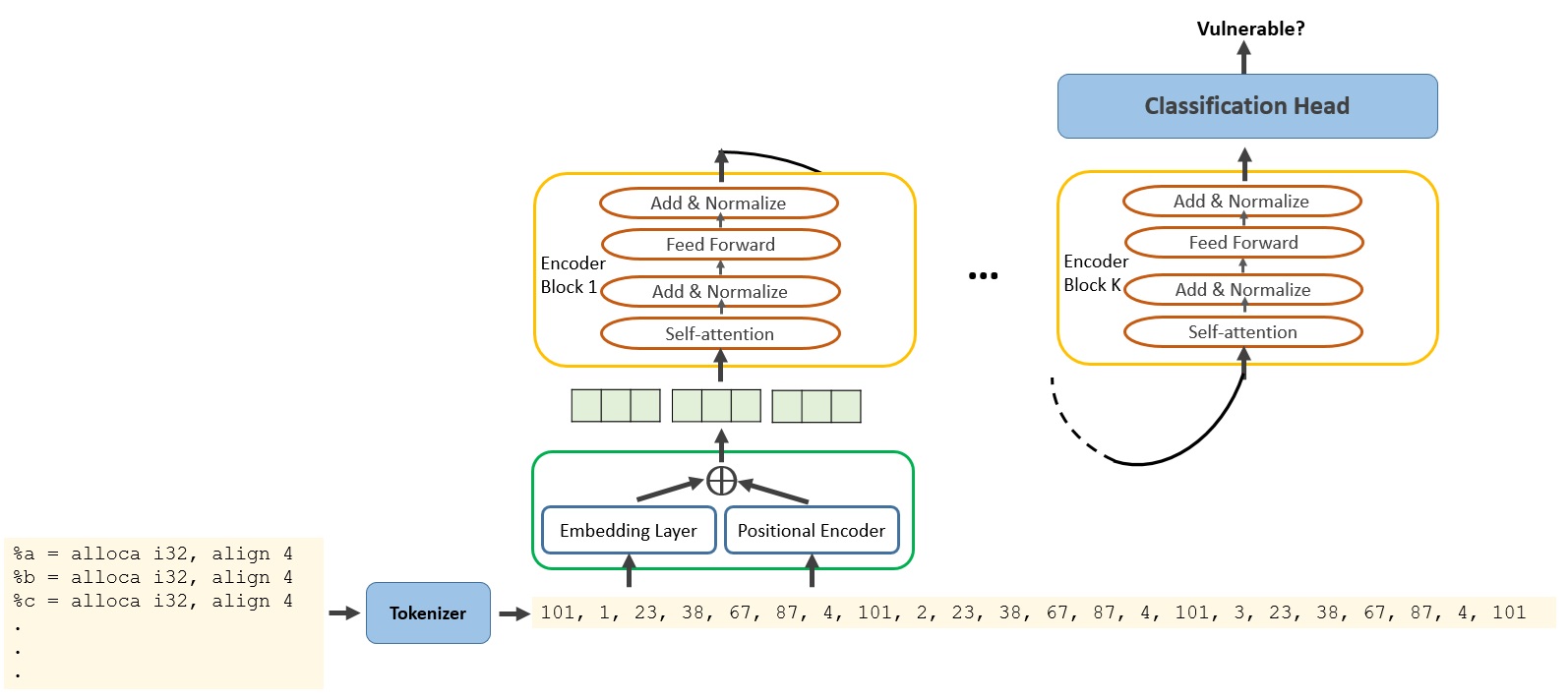
The paper proposes a framework for leveraging large language models (LLMs) for the task of source code vulnerability detection. LLMs are a class of AI models that have been trained on vast amounts of text data, allowing them to understand and generate human-like language.
The researchers hypothesize that the powerful language understanding capabilities of LLMs can be leveraged to identify patterns and characteristics of vulnerable code, which may be difficult to capture using traditional rule-based or pattern-matching approaches. To this end, they fine-tune a pre-trained LLM on a dataset of vulnerable and non-vulnerable code samples, using a binary classification objective to train the model to distinguish between the two.
Once the LLM is trained, the researchers evaluate its performance on a benchmark dataset of real-world codebases. They compare the LLM-based approach to a range of traditional vulnerability detection tools, considering metrics such as precision, recall, and F1-score.
The results show that the fine-tuned LLM outperforms the baseline tools, demonstrating the potential of this approach for improving the state of the art in software security. The researchers also provide insights into the types of vulnerabilities the LLM is able to detect, as well as the limitations and areas for further research.
Critical Analysis
The paper presents a promising approach to leveraging LLMs for source code vulnerability detection, but it also acknowledges several caveats and limitations that warrant further investigation.
One key limitation is the reliance on the availability of a high-quality dataset of vulnerable and non-vulnerable code samples for fine-tuning the LLM. The researchers used a publicly available benchmark dataset, but the quality and representativeness of this data may vary, potentially affecting the model's performance in real-world scenarios.
Additionally, the paper does not explore the interpretability and explainability of the LLM's vulnerability predictions. Understanding the model's reasoning and the specific code features it uses to identify vulnerabilities could be important for building trust and practical adoption in software development workflows.
Another area for further research is the potential for adversarial attacks against the LLM-based vulnerability detection system. As with many machine learning models, LLMs may be vulnerable to carefully crafted inputs designed to fool the model. Investigating the robustness of the approach to such attacks would be a valuable contribution.
Despite these limitations, the paper's findings suggest that LLMs have significant potential to improve the state of the art in source code vulnerability detection, especially when combined with traditional techniques. Further research and development in this area could lead to more effective and automated tools for securing software systems.
Conclusion
The paper presents a novel framework for leveraging the power of large language models (LLMs) to detect vulnerabilities in source code. By fine-tuning an LLM on a dataset of vulnerable and non-vulnerable code, the researchers demonstrate that the model can outperform traditional vulnerability detection tools in terms of accuracy and coverage.
This research suggests that LLMs have the potential to revolutionize the field of software security, providing a more powerful and adaptable approach to identifying and mitigating vulnerabilities. As the use of LLMs continues to expand in the domain of code analysis and security, this work represents an important step forward in harnessing the capabilities of these advanced AI models to improve the overall security and reliability of software systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Harnessing the Power of LLMs in Source Code Vulnerability Detection
Andrew A Mahyari
Software vulnerabilities, caused by unintentional flaws in source code, are a primary root cause of cyberattacks. Static analysis of source code has been widely used to detect these unintentional defects introduced by software developers. Large Language Models (LLMs) have demonstrated human-like conversational abilities due to their capacity to capture complex patterns in sequential data, such as natural languages. In this paper, we harness LLMs' capabilities to analyze source code and detect known vulnerabilities. To ensure the proposed vulnerability detection method is universal across multiple programming languages, we convert source code to LLVM IR and train LLMs on these intermediate representations. We conduct extensive experiments on various LLM architectures and compare their accuracy. Our comprehensive experiments on real-world and synthetic codes from NVD and SARD demonstrate high accuracy in identifying source code vulnerabilities.
Read more8/9/2024
💬
0
Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study
Karl Tamberg, Hayretdin Bahsi
Despite various approaches being employed to detect vulnerabilities, the number of reported vulnerabilities shows an upward trend over the years. This suggests the problems are not caught before the code is released, which could be caused by many factors, like lack of awareness, limited efficacy of the existing vulnerability detection tools or the tools not being user-friendly. To help combat some issues with traditional vulnerability detection tools, we propose using large language models (LLMs) to assist in finding vulnerabilities in source code. LLMs have shown a remarkable ability to understand and generate code, underlining their potential in code-related tasks. The aim is to test multiple state-of-the-art LLMs and identify the best prompting strategies, allowing extraction of the best value from the LLMs. We provide an overview of the strengths and weaknesses of the LLM-based approach and compare the results to those of traditional static analysis tools. We find that LLMs can pinpoint many more issues than traditional static analysis tools, outperforming traditional tools in terms of recall and F1 scores. The results should benefit software developers and security analysts responsible for ensuring that the code is free of vulnerabilities.
Read more5/27/2024

0
Can LLMs be Fooled? Investigating Vulnerabilities in LLMs
Sara Abdali, Jia He, CJ Barberan, Richard Anarfi
The advent of Large Language Models (LLMs) has garnered significant popularity and wielded immense power across various domains within Natural Language Processing (NLP). While their capabilities are undeniably impressive, it is crucial to identify and scrutinize their vulnerabilities especially when those vulnerabilities can have costly consequences. One such LLM, trained to provide a concise summarization from medical documents could unequivocally leak personal patient data when prompted surreptitiously. This is just one of many unfortunate examples that have been unveiled and further research is necessary to comprehend the underlying reasons behind such vulnerabilities. In this study, we delve into multiple sections of vulnerabilities which are model-based, training-time, inference-time vulnerabilities, and discuss mitigation strategies including Model Editing which aims at modifying LLMs behavior, and Chroma Teaming which incorporates synergy of multiple teaming strategies to enhance LLMs' resilience. This paper will synthesize the findings from each vulnerability section and propose new directions of research and development. By understanding the focal points of current vulnerabilities, we can better anticipate and mitigate future risks, paving the road for more robust and secure LLMs.
Read more7/31/2024
0
VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large Language Models
Yu Liu, Lang Gao, Mingxin Yang, Yu Xie, Ping Chen, Xiaojin Zhang, Wei Chen
Large Language Models (LLMs) have training corpora containing large amounts of program code, greatly improving the model's code comprehension and generation capabilities. However, sound comprehensive research on detecting program vulnerabilities, a more specific task related to code, and evaluating the performance of LLMs in this more specialized scenario is still lacking. To address common challenges in vulnerability analysis, our study introduces a new benchmark, VulDetectBench, specifically designed to assess the vulnerability detection capabilities of LLMs. The benchmark comprehensively evaluates LLM's ability to identify, classify, and locate vulnerabilities through five tasks of increasing difficulty. We evaluate the performance of 17 models (both open- and closed-source) and find that while existing models can achieve over 80% accuracy on tasks related to vulnerability identification and classification, they still fall short on specific, more detailed vulnerability analysis tasks, with less than 30% accuracy, making it difficult to provide valuable auxiliary information for professional vulnerability mining. Our benchmark effectively evaluates the capabilities of various LLMs at different levels in the specific task of vulnerability detection, providing a foundation for future research and improvements in this critical area of code security. VulDetectBench is publicly available at https://github.com/Sweetaroo/VulDetectBench.
Read more8/22/2024