Enhancing stop location detection for incomplete urban mobility datasets

0

Sign in to get full access
Overview
- This paper addresses the challenge of detecting stop locations in incomplete urban mobility datasets, which are common in real-world scenarios.
- The researchers propose an enhanced stop location detection method that leverages additional contextual information to improve accuracy, especially for datasets with sparse or irregular data points.
- The method is evaluated on both synthetic and real-world datasets, demonstrating its effectiveness in enhancing stop location detection compared to existing approaches.
Plain English Explanation
When analyzing people's movements in a city, it's important to be able to identify where they stop, such as at their home or workplace. However, the data collected about people's movements is often incomplete or irregular, making it difficult to accurately detect these stop locations.
The researchers in this paper developed an improved method for detecting stop locations even when the data is sparse or irregular. Their approach uses additional contextual information, such as the time of day and the surrounding environment, to better identify when and where people are stopping.
The researchers tested their method on both simulated data and real-world data about people's movements in a city. The results showed that their enhanced stop location detection method was more accurate than existing approaches, especially for datasets that were incomplete or had inconsistent data points.
By improving stop location detection, this research can help urban planners, transportation authorities, and others better understand how people move around a city. This could inform decisions about things like where to build new transportation infrastructure or how to design more efficient public transit systems.
Technical Explanation
The paper proposes an enhanced stop location detection method that leverages additional contextual information to improve accuracy, especially for urban mobility datasets with sparse or irregular data points.
The key elements of the approach include:
-
Contextual Feature Extraction: In addition to the typical location and timestamp data, the method extracts contextual features such as time of day, day of week, and nearby points of interest.
-
Probabilistic Stop Location Modeling: The method uses a probabilistic model to estimate the likelihood of a stop location at each data point, considering both the movement trajectory and the extracted contextual features.
-
Iterative Stop Location Refinement: The method iteratively refines the stop location estimates by incorporating feedback from the probabilistic model and the contextual features.
The researchers evaluated the proposed method on both synthetic and real-world urban mobility datasets. The results demonstrate that the enhanced stop location detection approach outperforms existing methods, especially for datasets with incomplete or irregular data points.
Critical Analysis
The paper provides a comprehensive evaluation of the proposed stop location detection method, including comparisons to baseline approaches on both synthetic and real-world datasets. However, the authors acknowledge several limitations and areas for further research:
-
Generalization to Different Contexts: The evaluation is limited to a single city, and the method's performance may vary in different urban environments with different transportation modes and mobility patterns.
-
Sensitivity to Contextual Feature Selection: The effectiveness of the approach relies on the careful selection and processing of the contextual features. Further research is needed to understand the optimal feature set and feature engineering techniques.
-
Computational Complexity: The iterative refinement process may introduce additional computational costs, which could be a concern for large-scale or real-time applications.
-
Privacy and Ethical Considerations: The use of contextual features, such as time of day and nearby points of interest, raises potential privacy concerns that should be addressed, as discussed in related work on privacy risks in mobility data.
Overall, the proposed enhanced stop location detection method represents a valuable contribution to the field of urban mobility analysis. However, the limitations and potential issues highlighted in the critical analysis should be considered and addressed in future research.
Conclusion
This paper presents an enhanced stop location detection method that leverages additional contextual information to improve accuracy, especially for incomplete or irregular urban mobility datasets. The proposed approach demonstrates superior performance compared to existing methods, highlighting its potential to support a wide range of urban planning, transportation, and mobility-related applications.
By improving stop location detection, this research can enable better understanding of how people move around a city, which can inform decisions about transportation infrastructure, public transit, and other urban planning initiatives. The insights gained can also contribute to the development of more effective next-POI prediction systems and enhanced aerial observation and trajectory analysis for various applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing stop location detection for incomplete urban mobility datasets
Margherita Bert`e, Rashid Ibrahimli, Lars Koopmans, Pablo Valga~n'on, Nicola Zomer, Davide Colombi
Stop location detection, within human mobility studies, has an impacts in multiple fields including urban planning, transport network design, epidemiological modeling, and socio-economic segregation analysis. However, it remains a challenging task because classical density clustering algorithms often struggle with noisy or incomplete GPS datasets. This study investigates the application of classification algorithms to enhance density-based methods for stop identification. Our approach incorporates multiple features, including individual routine behavior across various time scales and local characteristics of individual GPS points. The dataset comprises privacy-preserving and anonymized GPS points previously labeled as stops by a sequence-oriented, density-dependent algorithm. We simulated data gaps by removing point density from select stops to assess performance under sparse data conditions. The model classifies individual GPS points within trajectories as potential stops or non-stops. Given the highly imbalanced nature of the dataset, we prioritized recall over precision in performance evaluation. Results indicate that this method detects most stops, even in the presence of spatio-temporal gaps and that points classified as false positives often correspond to recurring locations for devices, typically near previous stops. While this research contributes to mobility analysis techniques, significant challenges persist. The lack of ground truth data limits definitive conclusions about the algorithm's accuracy. Further research is needed to validate the method across diverse datasets and to incorporate collective behavior inputs.
Read more7/17/2024
0
New!Uncertainty-aware Human Mobility Modeling and Anomaly Detection
Haomin Wen, Shurui Cao, Leman Akoglu
Given the GPS coordinates of a large collection of human agents over time, how can we model their mobility behavior toward effective anomaly detection (e.g. for bad-actor or malicious behavior detection) without any labeled data? Human mobility and trajectory modeling have been studied extensively with varying capacity to handle complex input, and performance-efficiency trade-offs. With the arrival of more expressive models in machine learning, we attempt to model GPS data as a sequence of stay-point events, each with a set of characterizing spatiotemporal features, and leverage modern sequence models such as Transformers for un/self-supervised training and inference. Notably, driven by the inherent stochasticity of certain individuals' behavior, we equip our model with aleatoric/data uncertainty estimation. In addition, to handle data sparsity of a large variety of behaviors, we incorporate epistemic/model uncertainty into our model. Together, aleatoric and epistemic uncertainty enable a robust loss and training dynamics, as well as uncertainty-aware decision making in anomaly scoring. Experiments on large expert-simulated datasets with tens of thousands of agents demonstrate the effectiveness of our model against both forecasting and anomaly detection baselines.
Read more10/3/2024
🎲
0
Predicting Traffic Congestion at Urban Intersections Using Data-Driven Modeling
Tara Kelly, Jessica Gupta
Traffic congestion at intersections is a significant issue in urban areas, leading to increased commute times, safety hazards, and operational inefficiencies. This study aims to develop a predictive model for congestion at intersections in major U.S. cities, utilizing a dataset of trip-logging metrics from commercial vehicles across 4,800 intersections. The dataset encompasses 27 features, including intersection coordinates, street names, time of day, and traffic metrics (Kashyap et al., 2019). Additional features, such as rainfall/snowfall percentage, distance from downtown and outskirts, and road types, were incorporated to enhance the model's predictive power. The methodology involves data exploration, feature transformation, and handling missing values through low-rank models and label encoding. The proposed model has the potential to assist city planners and governments in anticipating traffic hot spots, optimizing operations, and identifying infrastructure challenges.
Read more4/24/2024
0
Towards Effective Next POI Prediction: Spatial and Semantic Augmentation with Remote Sensing Data
Nan Jiang, Haitao Yuan, Jianing Si, Minxiao Chen, Shangguang Wang
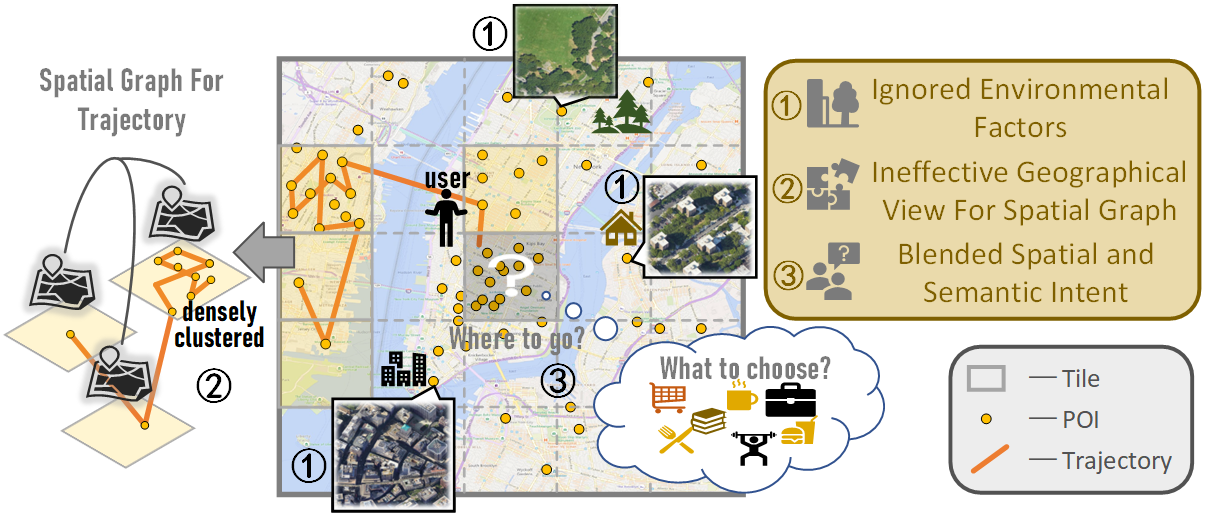
The next point-of-interest (POI) prediction is a significant task in location-based services, yet its complexity arises from the consolidation of spatial and semantic intent. This fusion is subject to the influences of historical preferences, prevailing location, and environmental factors, thereby posing significant challenges. In addition, the uneven POI distribution further complicates the next POI prediction procedure. To address these challenges, we enrich input features and propose an effective deep-learning method within a two-step prediction framework. Our method first incorporates remote sensing data, capturing pivotal environmental context to enhance input features regarding both location and semantics. Subsequently, we employ a region quad-tree structure to integrate urban remote sensing, road network, and POI distribution spaces, aiming to devise a more coherent graph representation method for urban spatial. Leveraging this method, we construct the QR-P graph for the user's historical trajectories to encapsulate historical travel knowledge, thereby augmenting input features with comprehensive spatial and semantic insights. We devise distinct embedding modules to encode these features and employ an attention mechanism to fuse diverse encodings. In the two-step prediction procedure, we initially identify potential spatial zones by predicting user-preferred tiles, followed by pinpointing specific POIs of a designated type within the projected tiles. Empirical findings from four real-world location-based social network datasets underscore the remarkable superiority of our proposed approach over competitive baseline methods.
Read more4/9/2024