Enhancing Training Efficiency Using Packing with Flash Attention

0

Sign in to get full access
Overview
- This paper introduces a technique called "Packing with Flash Attention" that can improve the efficiency of training large language models.
- The key ideas are to use a technique called "packing" to group similar inputs together, and a novel attention mechanism called "Flash Attention" that can process these packed inputs efficiently.
- The authors show that this approach can lead to significant speedups in training time with minimal impact on model performance.
Plain English Explanation
The paper describes a way to make training large language models, like those used for tasks like language translation or text generation, more efficient and faster. The key insight is to group similar inputs together, a technique called "packing", and then use a new attention mechanism called "Flash Attention" to process these packed inputs efficiently.
Attention mechanisms are a core part of many language models, as they allow the model to focus on the most relevant parts of the input when generating the output. However, traditional attention can be computationally expensive, especially for long inputs. The "Flash Attention" technique introduced in this paper is able to compute attention much more quickly, resulting in faster overall training.
By combining packing and Flash Attention, the authors show they can achieve significant speedups in training time - in some cases cutting the training time in half - with little to no loss in model performance. This is an important advance, as training large language models can be extremely computationally intensive and time-consuming, so any techniques that can improve efficiency are very valuable.
Technical Explanation
The paper proposes a technique called "Packing with Flash Attention" to improve the training efficiency of large language models. The core ideas are:
-
Packing: The authors use a "packing" technique to group similar input sequences together, reducing the total number of sequences that need to be processed. This is similar to the prepacking approach used in other work.
-
Flash Attention: The authors introduce a new attention mechanism called "Flash Attention" that can process these packed inputs much more efficiently than traditional attention. Flash Attention uses asynchronous computation and other optimizations to achieve this speedup, building on ideas from prior work on fast attention.
The authors evaluate this approach on a variety of language modeling benchmarks, including the Pile dataset. They show that Packing with Flash Attention can achieve significant speedups in training time, in some cases cutting the time in half, with minimal impact on model performance.
Critical Analysis
The paper provides a compelling approach to improving the training efficiency of large language models, which is an important practical challenge. The authors demonstrate clear empirical benefits of their techniques, and the technical details are well-explained.
One potential limitation is that the packing approach may not work as well for extremely diverse or heterogeneous datasets, where it may be difficult to find good groupings of similar inputs. The authors acknowledge this and suggest the packing strategy could be further improved, for example by using learning-based packing approaches.
Additionally, the paper focuses on improving training efficiency, but does not explore the implications for deployment or inference speed of the final models. It would be interesting to see an analysis of how Packing with Flash Attention impacts the inference latency and throughput of the trained models.
Overall, this is a well-executed piece of research that offers a promising direction for enhancing the training of large language models. The techniques described have the potential for broad applicability, and the authors have made a valuable contribution to the field.
Conclusion
This paper introduces "Packing with Flash Attention", a novel approach to improving the training efficiency of large language models. By combining packing techniques to group similar inputs and a new attention mechanism called "Flash Attention" that can process these packed inputs more efficiently, the authors demonstrate significant speedups in training time with minimal impact on model performance.
This work represents an important advance in the field of language modeling, as training these large and complex models can be extremely computationally intensive and time-consuming. Techniques like those described in this paper that can enhance training efficiency have the potential to accelerate progress in natural language processing and enable the development of more capable language models. While the authors identify some limitations, the core ideas presented here are a valuable contribution and worthy of further exploration and refinement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Training Efficiency Using Packing with Flash Attention
Achintya Kundu, Rhui Dih Lee, Laura Wynter, Raghu Kiran Ganti, Mayank Mishra
Padding is often used in tuning LLM models by adding special tokens to shorter training examples to match the length of the longest sequence in each batch. While this ensures uniformity for batch processing, it introduces inefficiencies by including irrelevant padding tokens in the computation and wastes GPU resources. Hugging Face SFT trainer has always offered the option to use packing to combine multiple training examples, allowing for maximal utilization of GPU resources. However, up till now, it did not offer proper masking of each packed training example. This capability has now been added to Hugging Face Transformers 4.44. We analyse this new feature and show the benefits across different variations of packing.
Read more8/26/2024

0
Threshold Filtering Packing for Supervised Fine-Tuning: Training Related Samples within Packs
Jiancheng Dong, Lei Jiang, Wei Jin, Lu Cheng
Packing for Supervised Fine-Tuning (SFT) in autoregressive models involves concatenating data points of varying lengths until reaching the designed maximum length to facilitate GPU processing. However, randomly concatenating data points and feeding them into an autoregressive transformer can lead to cross-contamination of sequences due to the significant difference in their subject matter. The mainstream approaches in SFT ensure that each token in the attention calculation phase only focuses on tokens within its own short sequence, without providing additional learning signals for the preceding context. To address these challenges, we introduce Threshold Filtering Packing (TFP), a method that selects samples with related context while maintaining sufficient diversity within the same pack. Our experiments show that TFP offers a simple-to-implement and scalable approach that significantly enhances SFT performance, with observed improvements of up to 7% on GSM8K, 4% on HumanEval, and 15% on the adult-census-income dataset.
Read more8/20/2024

0
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, Tri Dao
Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. FlashAttention elaborated an approach to speed up attention on GPUs through minimizing memory reads/writes. However, it has yet to take advantage of new capabilities present in recent hardware, with FlashAttention-2 achieving only 35% utilization on the H100 GPU. We develop three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) block quantization and incoherent processing that leverages hardware support for FP8 low-precision. We demonstrate that our method, FlashAttention-3, achieves speedup on H100 GPUs by 1.5-2.0$times$ with FP16 reaching up to 740 TFLOPs/s (75% utilization), and with FP8 reaching close to 1.2 PFLOPs/s. We validate that FP8 FlashAttention-3 achieves 2.6$times$ lower numerical error than a baseline FP8 attention.
Read more7/16/2024
0
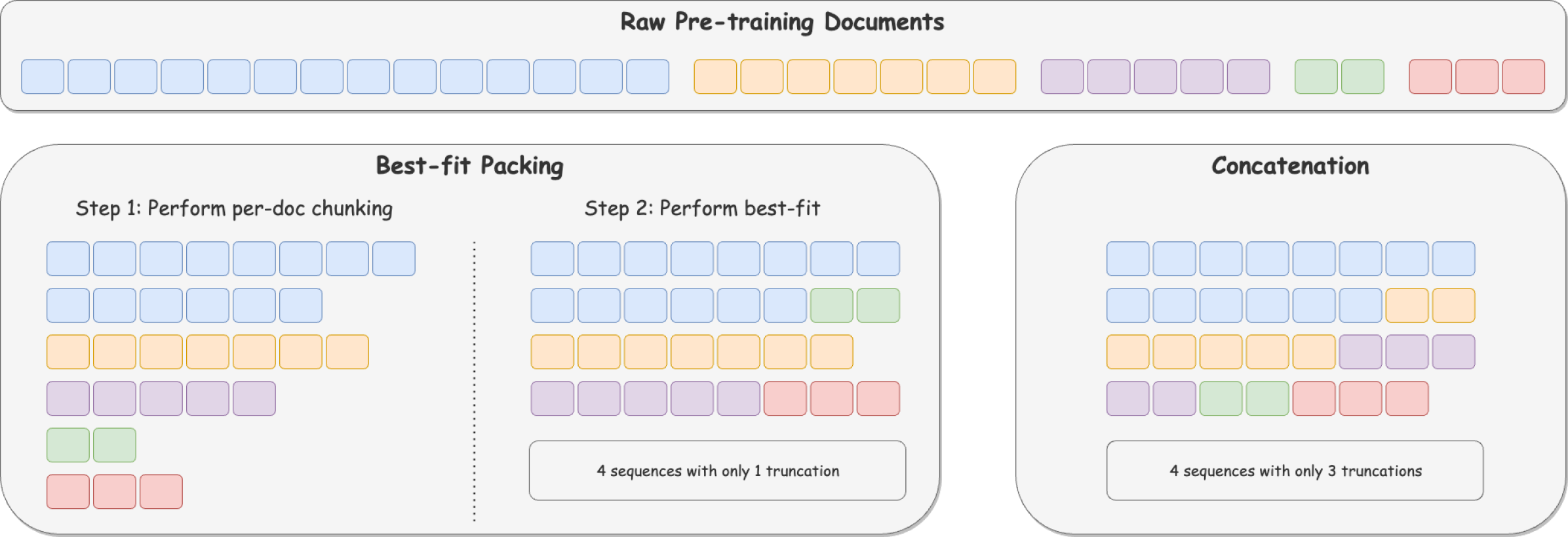
Fewer Truncations Improve Language Modeling
Hantian Ding, Zijian Wang, Giovanni Paolini, Varun Kumar, Anoop Deoras, Dan Roth, Stefano Soatto
In large language model training, input documents are typically concatenated together and then split into sequences of equal length to avoid padding tokens. Despite its efficiency, the concatenation approach compromises data integrity -- it inevitably breaks many documents into incomplete pieces, leading to excessive truncations that hinder the model from learning to compose logically coherent and factually consistent content that is grounded on the complete context. To address the issue, we propose Best-fit Packing, a scalable and efficient method that packs documents into training sequences through length-aware combinatorial optimization. Our method completely eliminates unnecessary truncations while retaining the same training efficiency as concatenation. Empirical results from both text and code pre-training show that our method achieves superior performance (e.g., relatively +4.7% on reading comprehension; +16.8% in context following; and +9.2% on program synthesis), and reduces closed-domain hallucination effectively by up to 58.3%.
Read more5/3/2024