FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision

0

Sign in to get full access
Overview
- This paper introduces FlashAttention-3, a fast and accurate attention mechanism that leverages asynchrony and low-precision computations to improve the efficiency of large language models.
- It builds upon previous work on Lean Attention and Efficient Economic Large Language Model Inference, which explored hardware-aware attention mechanisms.
- The authors demonstrate that FlashAttention-3 can achieve significant speedups and memory savings compared to standard attention, while maintaining high accuracy, making it a promising approach for deploying large models on resource-constrained devices.
Plain English Explanation
The paper focuses on improving the efficiency of the attention mechanism, a key component in large language models like GPT. Attention allows the model to focus on the most relevant parts of its input when generating output, but it can be computationally expensive.
The researchers developed a new approach called FlashAttention-3 that makes two key improvements:
-
Asynchrony: Instead of computing attention for all input elements at once, FlashAttention-3 computes attention for each input element asynchronously. This allows the computation to be parallelized more effectively on GPUs.
-
Low-precision: FlashAttention-3 uses lower-precision numerical representations (e.g., 8-bit instead of 32-bit floating-point) for many of the attention computations. This reduces the memory and computational requirements without sacrificing too much accuracy.
By leveraging these two techniques, FlashAttention-3 is able to achieve significant speedups (up to 3x) and memory savings (up to 4x) compared to standard attention, while maintaining high accuracy. This makes it a promising approach for deploying large language models on devices with limited computational resources, like smartphones or edge devices.
Technical Explanation
The paper begins by providing background on multi-head attention, the core attention mechanism used in transformer-based language models. It also discusses key characteristics of GPUs that motivate the design of FlashAttention-3.
The key innovations in FlashAttention-3 are:
-
Asynchronous Attention Computation: Instead of computing attention for all input elements simultaneously, FlashAttention-3 computes attention for each input element asynchronously. This allows the attention computation to be better parallelized on GPUs, leading to significant speedups.
-
Low-precision Attention Computation: FlashAttention-3 uses lower-precision numerical representations (e.g., 8-bit instead of 32-bit floating-point) for many of the attention computations. This reduces the memory and computational requirements without sacrificing too much accuracy.
The paper presents extensive experiments comparing the performance of FlashAttention-3 to standard attention on a variety of language modeling benchmarks. The results demonstrate that FlashAttention-3 can achieve up to 3x speedups and 4x memory savings, while maintaining high accuracy.
Critical Analysis
The paper provides a thorough evaluation of FlashAttention-3 and highlights its strengths, but it also acknowledges some potential limitations and areas for further research:
-
The authors note that the asynchronous nature of FlashAttention-3 may introduce some stability issues, which they address by using gated linear attention and other techniques. However, they suggest that further research is needed to fully understand the stability properties of Flash Attention.
-
While FlashAttention-3 achieves impressive performance gains, the authors acknowledge that the optimal trade-off between speed, memory, and accuracy may vary depending on the specific use case and hardware constraints. More research is needed to understand how to best apply these techniques in different deployment scenarios.
-
The paper focuses on language modeling tasks, but it would be interesting to see how well FlashAttention-3 generalizes to other domains, such as tensor attention for efficient training of large models.
Overall, the FlashAttention-3 approach is a promising step towards more efficient and deployable large language models, but further research is needed to fully understand its strengths, limitations, and broader applicability.
Conclusion
The FlashAttention-3 paper presents a novel attention mechanism that leverages asynchrony and low-precision computations to significantly improve the efficiency of large language models. By achieving up to 3x speedups and 4x memory savings while maintaining high accuracy, FlashAttention-3 represents an important advancement in making powerful language models more practical to deploy on resource-constrained devices.
The key innovations in FlashAttention-3 – asynchronous attention computation and low-precision numerics – demonstrate the potential for hardware-aware attention mechanisms to unlock new levels of efficiency in large-scale AI systems. As the demand for capable yet deployable language models continues to grow, approaches like FlashAttention-3 will likely play a crucial role in bridging the gap between model complexity and real-world applicability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, Tri Dao
Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. FlashAttention elaborated an approach to speed up attention on GPUs through minimizing memory reads/writes. However, it has yet to take advantage of new capabilities present in recent hardware, with FlashAttention-2 achieving only 35% utilization on the H100 GPU. We develop three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) block quantization and incoherent processing that leverages hardware support for FP8 low-precision. We demonstrate that our method, FlashAttention-3, achieves speedup on H100 GPUs by 1.5-2.0$times$ with FP16 reaching up to 740 TFLOPs/s (75% utilization), and with FP8 reaching close to 1.2 PFLOPs/s. We validate that FP8 FlashAttention-3 achieves 2.6$times$ lower numerical error than a baseline FP8 attention.
Read more7/16/2024

0
Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
Read more5/20/2024

0
An Analog and Digital Hybrid Attention Accelerator for Transformers with Charge-based In-memory Computing
Ashkan Moradifirouzabadi, Divya Sri Dodla, Mingu Kang
The attention mechanism is a key computing kernel of Transformers, calculating pairwise correlations across the entire input sequence. The computing complexity and frequent memory access in computing self-attention put a huge burden on the system especially when the sequence length increases. This paper presents an analog and digital hybrid processor to accelerate the attention mechanism for transformers in 65nm CMOS technology. We propose an analog computing-in-memory (CIM) core, which prunes ~75% of low-score tokens on average during runtime at ultra-low power and delay. Additionally, a digital processor performs precise computations only for ~25% unpruned tokens selected by the analog CIM core, preventing accuracy degradation. Measured results show peak energy efficiency of 14.8 and 1.65 TOPS/W, and peak area efficiency of 976.6 and 79.4 GOPS/mm$^mathrm{2}$ in the analog core and the system-on-chip (SoC), respectively.
Read more9/10/2024
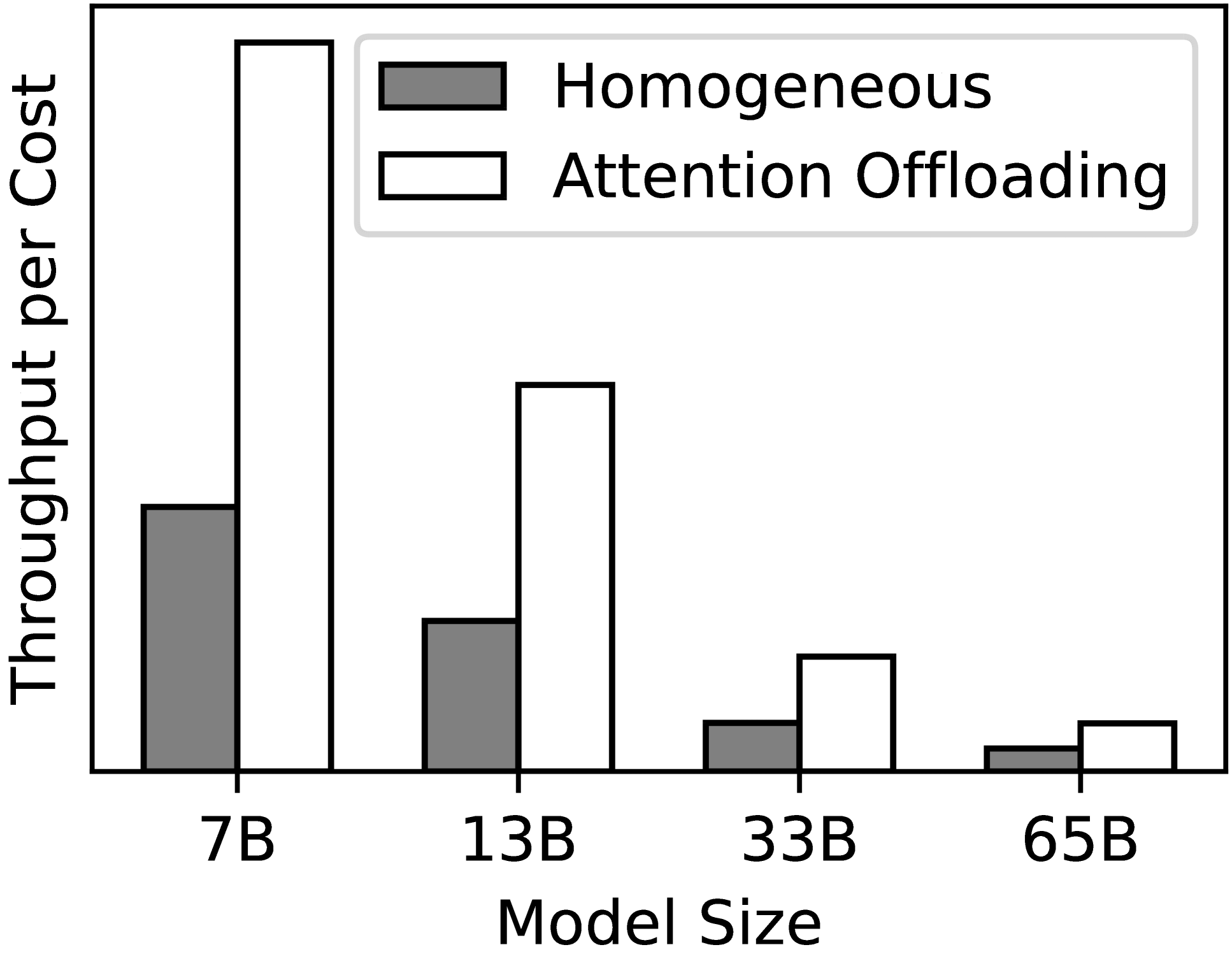
0
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
Read more5/6/2024