Knowledge-Based Domain-Oriented Data Augmentation for Enhancing Unsupervised Sentence Embedding

0

Sign in to get full access
Overview
- The research paper explores a technique called "Knowledge-Based Domain-Oriented Data Augmentation" to enhance unsupervised sentence embedding.
- It aims to improve the performance of sentence embedding models by incorporating domain-specific knowledge into the training data.
- The proposed approach involves generating synthetic sentences that are semantically and syntactically similar to the original data, but with subtle variations that capture domain-specific nuances.
Plain English Explanation
Sentence embedding is a way of converting sentences into numerical representations that can be used for various natural language processing tasks. However, the performance of sentence embedding models can be limited by the available training data.
The researchers in this paper developed a method to address this issue. They used domain-specific knowledge to generate additional training data that closely resembles the original sentences, but with slight variations. For example, if the original data was about finance, the generated sentences might discuss similar financial concepts using different wording.
By incorporating this domain-oriented synthetic data into the training process, the researchers were able to enhance the performance of the sentence embedding model. The model was then better able to capture the nuances and subtleties of the target domain, leading to improved results on tasks like text classification or information retrieval.
The key idea is to leverage domain expertise and knowledge to create more diverse and representative training data, rather than relying solely on the original dataset. This can be particularly useful when working with specialized domains or when the available data is limited.
Technical Explanation
The researchers proposed a Knowledge-Based Domain-Oriented Data Augmentation approach to enhance unsupervised sentence embedding. The method involves the following steps:
-
Domain Knowledge Extraction: The researchers first extract domain-specific knowledge from external sources, such as ontologies, dictionaries, or expert-curated resources. This knowledge is used to identify important concepts, entities, and relationships within the target domain.
-
Sentence Generation: Using the extracted domain knowledge, the researchers generate new synthetic sentences that are semantically and syntactically similar to the original data, but with subtle variations. This is done by replacing words or phrases with alternative expressions that capture the same meaning within the domain.
-
Sentence Embedding Training: The original dataset and the generated synthetic sentences are then used to train the sentence embedding model. This allows the model to learn more robust and domain-specific representations of the text.
The researchers evaluated their approach on several sentence embedding tasks, including text classification and semantic similarity. Their results showed that the Knowledge-Based Domain-Oriented Data Augmentation method outperformed traditional data augmentation techniques and led to significant improvements in the performance of the sentence embedding model.
Critical Analysis
The researchers acknowledge several limitations and areas for further research:
- The effectiveness of the approach may depend on the quality and coverage of the domain knowledge used for sentence generation. Obtaining comprehensive and accurate domain knowledge can be challenging in some cases.
- The researchers only evaluated their method on a limited number of domains and tasks. Broader testing across a wider range of domains and applications would be necessary to fully assess the generalizability of the approach.
- The sentence generation process relies on heuristics and rules, which may not capture all the nuances and complexities of natural language. More advanced language generation techniques could potentially improve the quality of the synthetic data.
- The paper does not provide a detailed analysis of the types of errors or biases that may be introduced by the synthetic data. Understanding and mitigating such issues would be an important area for future research.
Overall, the Knowledge-Based Domain-Oriented Data Augmentation approach presents a promising direction for enhancing unsupervised sentence embedding, but further research and validation would be needed to fully assess its capabilities and limitations.
Conclusion
The research paper proposes a novel Knowledge-Based Domain-Oriented Data Augmentation technique to improve the performance of unsupervised sentence embedding models. By generating synthetic sentences that capture domain-specific knowledge and nuances, the researchers were able to enhance the model's ability to learn more robust and specialized representations of text.
This approach has the potential to be particularly useful in specialized domains or when the available training data is limited. However, the effectiveness of the method depends on the quality and coverage of the domain knowledge used, and further research is needed to fully understand its capabilities and limitations.
Overall, this research represents an important contribution to the field of natural language processing, as it explores innovative ways to leverage domain expertise and knowledge to enhance the performance of fundamental language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Knowledge-Based Domain-Oriented Data Augmentation for Enhancing Unsupervised Sentence Embedding
Peichao Lai, Zhengfeng Zhang, Wentao Zhang, Fangcheng Fu, Bin Cui
Recently, using large language models (LLMs) for data augmentation has led to considerable improvements in unsupervised sentence embedding models. However, existing methods encounter two primary challenges: limited data diversity and high data noise. Current approaches often neglect fine-grained knowledge, such as entities and quantities, leading to insufficient diversity. Additionally, unsupervised data frequently lacks discriminative information, and the generated synthetic samples may introduce noise. In this paper, we propose a pipeline-based data augmentation method via LLMs and introduce the Gaussian-decayed gradient-assisted Contrastive Sentence Embedding (GCSE) model to enhance unsupervised sentence embeddings. To tackle the issue of low data diversity, our pipeline utilizes knowledge graphs (KGs) to extract entities and quantities, enabling LLMs to generate more diverse, knowledge-enriched samples. To address high data noise, the GCSE model uses a Gaussian-decayed function to limit the impact of false hard negative samples, enhancing the model's discriminative capability. Experimental results show that our approach achieves state-of-the-art performance in semantic textual similarity (STS) tasks, using fewer data samples and smaller LLMs, demonstrating its efficiency and robustness across various models.
Read more10/3/2024
0
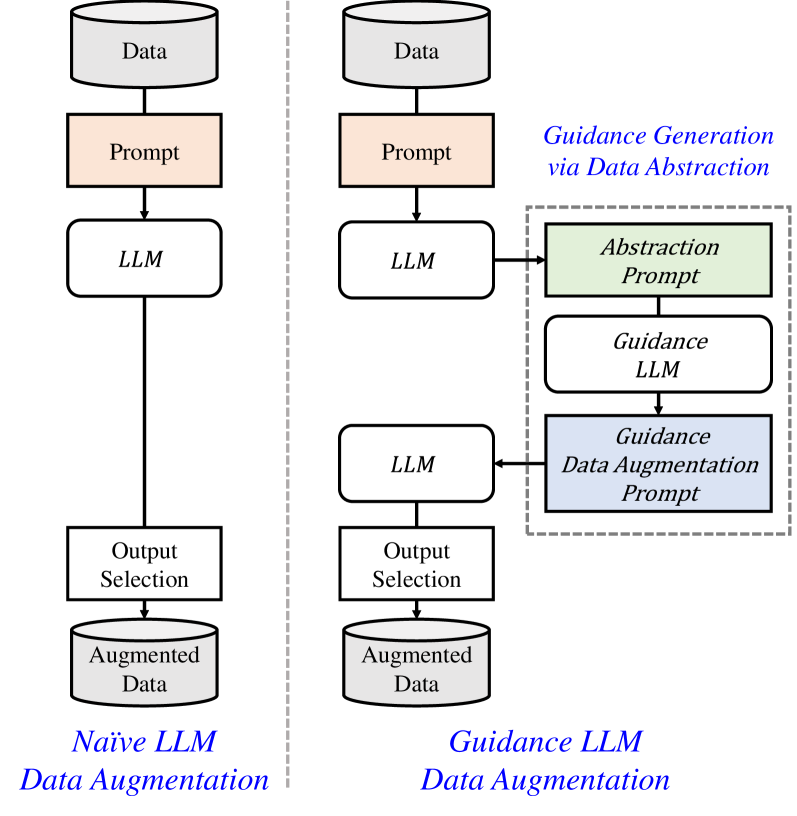
Guidance-Based Prompt Data Augmentation in Specialized Domains for Named Entity Recognition
Hyeonseok Kang, Hyein Seo, Jeesu Jung, Sangkeun Jung, Du-Seong Chang, Riwoo Chung
While the abundance of rich and vast datasets across numerous fields has facilitated the advancement of natural language processing, sectors in need of specialized data types continue to struggle with the challenge of finding quality data. Our study introduces a novel guidance data augmentation technique utilizing abstracted context and sentence structures to produce varied sentences while maintaining context-entity relationships, addressing data scarcity challenges. By fostering a closer relationship between context, sentence structure, and role of entities, our method enhances data augmentation's effectiveness. Consequently, by showcasing diversification in both entity-related vocabulary and overall sentence structure, and simultaneously improving the training performance of named entity recognition task.
Read more7/29/2024
0
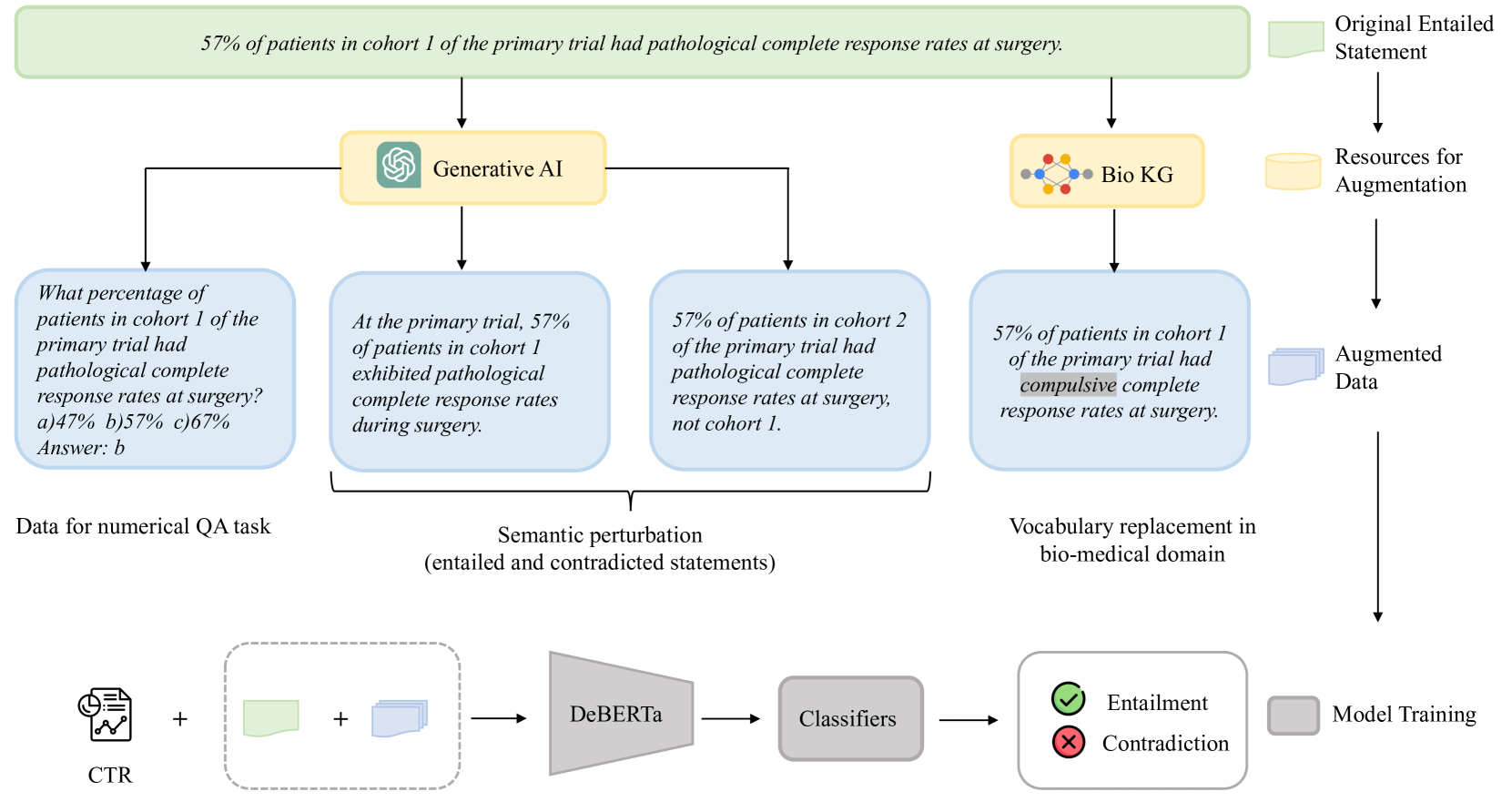
DKE-Research at SemEval-2024 Task 2: Incorporating Data Augmentation with Generative Models and Biomedical Knowledge to Enhance Inference Robustness
Yuqi Wang, Zeqiang Wang, Wei Wang, Qi Chen, Kaizhu Huang, Anh Nguyen, Suparna De
Safe and reliable natural language inference is critical for extracting insights from clinical trial reports but poses challenges due to biases in large pre-trained language models. This paper presents a novel data augmentation technique to improve model robustness for biomedical natural language inference in clinical trials. By generating synthetic examples through semantic perturbations and domain-specific vocabulary replacement and adding a new task for numerical and quantitative reasoning, we introduce greater diversity and reduce shortcut learning. Our approach, combined with multi-task learning and the DeBERTa architecture, achieved significant performance gains on the NLI4CT 2024 benchmark compared to the original language models. Ablation studies validate the contribution of each augmentation method in improving robustness. Our best-performing model ranked 12th in terms of faithfulness and 8th in terms of consistency, respectively, out of the 32 participants.
Read more4/16/2024

2
Synthetic continued pretraining
Zitong Yang, Neil Band, Shuangping Li, Emmanuel Cand`es, Tatsunori Hashimoto
Pretraining on large-scale, unstructured internet text enables language models to acquire a significant amount of world knowledge. However, this knowledge acquisition is data-inefficient--to learn a given fact, models must be trained on hundreds to thousands of diverse representations of it. This poses a challenge when adapting a pretrained model to a small corpus of domain-specific documents, where each fact may appear rarely or only once. We propose to bridge this gap with synthetic continued pretraining: using the small domain-specific corpus to synthesize a large corpus more amenable to learning, and then performing continued pretraining on the synthesized corpus. We instantiate this proposal with EntiGraph, a synthetic data augmentation algorithm that extracts salient entities from the source documents and then generates diverse text by drawing connections between the sampled entities. Synthetic continued pretraining with EntiGraph enables a language model to answer questions and follow generic instructions related to the source documents without access to them. If, instead, the source documents are available at inference time, we show that the knowledge acquired through our approach compounds with retrieval-augmented generation. To better understand these results, we build a simple mathematical model of EntiGraph, and show how synthetic data augmentation can rearrange knowledge to enable more data-efficient learning.
Read more10/4/2024