Enhancing Visual Dialog State Tracking through Iterative Object-Entity Alignment in Multi-Round Conversations

0

Sign in to get full access
Overview
- This paper focuses on improving visual dialog state tracking by aligning objects and entities across multiple rounds of conversation.
- The key idea is to iteratively update the understanding of the dialog state by matching objects mentioned in the conversation to corresponding entities in the visual scene.
- This approach aims to enhance performance on visual dialog tasks that require tracking the evolving state of the conversation over multiple turns.
Plain English Explanation
When we have a conversation about something we can see, like an image, the meaning of the words we use can change over time as the discussion progresses. The paper's approach tries to better capture this by continuously aligning the objects mentioned in the chat with the corresponding elements in the visual scene.
This iterative object-entity alignment allows the system to gradually build up a more accurate understanding of the dialog state - what the conversation is about and how it evolves. The goal is to improve performance on tasks that require tracking the changing context of a multi-round visual dialog.
Technical Explanation
The paper presents a novel approach for visual dialog state tracking that involves iteratively aligning the objects mentioned in the dialog with the corresponding entities in the visual scene.
The key technical components are:
- Object Detection: The visual scene is processed to detect and localize the various objects present.
- Entity Representation: The identified objects are encoded into a compact representation that captures their visual and semantic properties.
- Alignment Module: An alignment module is used to match the object mentions in the dialog to the entities in the visual scene, updating the dialog state accordingly.
- Iterative Refinement: The alignment is performed iteratively, allowing the system to gradually refine its understanding of the dialog state over multiple rounds of conversation.
The authors demonstrate the effectiveness of this approach through experiments on standard visual dialog datasets, showing improvements over prior state-of-the-art methods.
Critical Analysis
The paper presents a well-designed and thoughtful approach to enhancing visual dialog state tracking. The core idea of iteratively aligning object mentions to visual entities is a compelling one, as it aligns with the intuitive way humans track the evolving context of a conversation.
That said, the paper does not delve deeply into potential limitations or caveats of the proposed method. For example, it would be interesting to understand how the approach handles ambiguous or abstract language, or how it scales to more complex visual scenes with a large number of objects.
Additionally, the authors could have explored ways to further leverage the iterative alignment process, such as using the evolving dialog state to guide the object detection or entity representation modules.
Overall, this is a promising piece of research that makes a meaningful contribution to the field of visual dialog, but there are likely opportunities for further refinement and expansion.
Conclusion
This paper introduces an innovative approach to visual dialog state tracking that centers on the iterative alignment of object mentions in the conversation to corresponding entities in the visual scene. By continuously updating the dialog state based on this alignment, the system is able to better capture the evolving context of the multi-round interaction.
The technical implementation and experimental results demonstrate the effectiveness of this method, suggesting that object-entity alignment is a fruitful direction for enhancing performance on visual dialog tasks. While the paper does not fully explore the limitations of the approach, it represents an important step forward in advancing the state-of-the-art in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Visual Dialog State Tracking through Iterative Object-Entity Alignment in Multi-Round Conversations
Wei Pang, Ruixue Duan, Jinfu Yang, Ning Li
Visual Dialog (VD) is a task where an agent answers a series of image-related questions based on a multi-round dialog history. However, previous VD methods often treat the entire dialog history as a simple text input, disregarding the inherent conversational information flows at the round level. In this paper, we introduce Multi-round Dialogue State Tracking model (MDST), a framework that addresses this limitation by leveraging the dialogue state learned from dialog history to answer questions. MDST captures each round of dialog history, constructing internal dialogue state representations defined as 2-tuples of vision-language representations. These representations effectively ground the current question, enabling the generation of accurate answers. Experimental results on the VisDial v1.0 dataset demonstrate that MDST achieves a new state-of-the-art performance in generative setting. Furthermore, through a series of human studies, we validate the effectiveness of MDST in generating long, consistent, and human-like answers while consistently answering a series of questions correctly.
Read more8/14/2024
0
Multi-Modal Video Dialog State Tracking in the Wild
Adnen Abdessaied, Lei Shi, Andreas Bulling
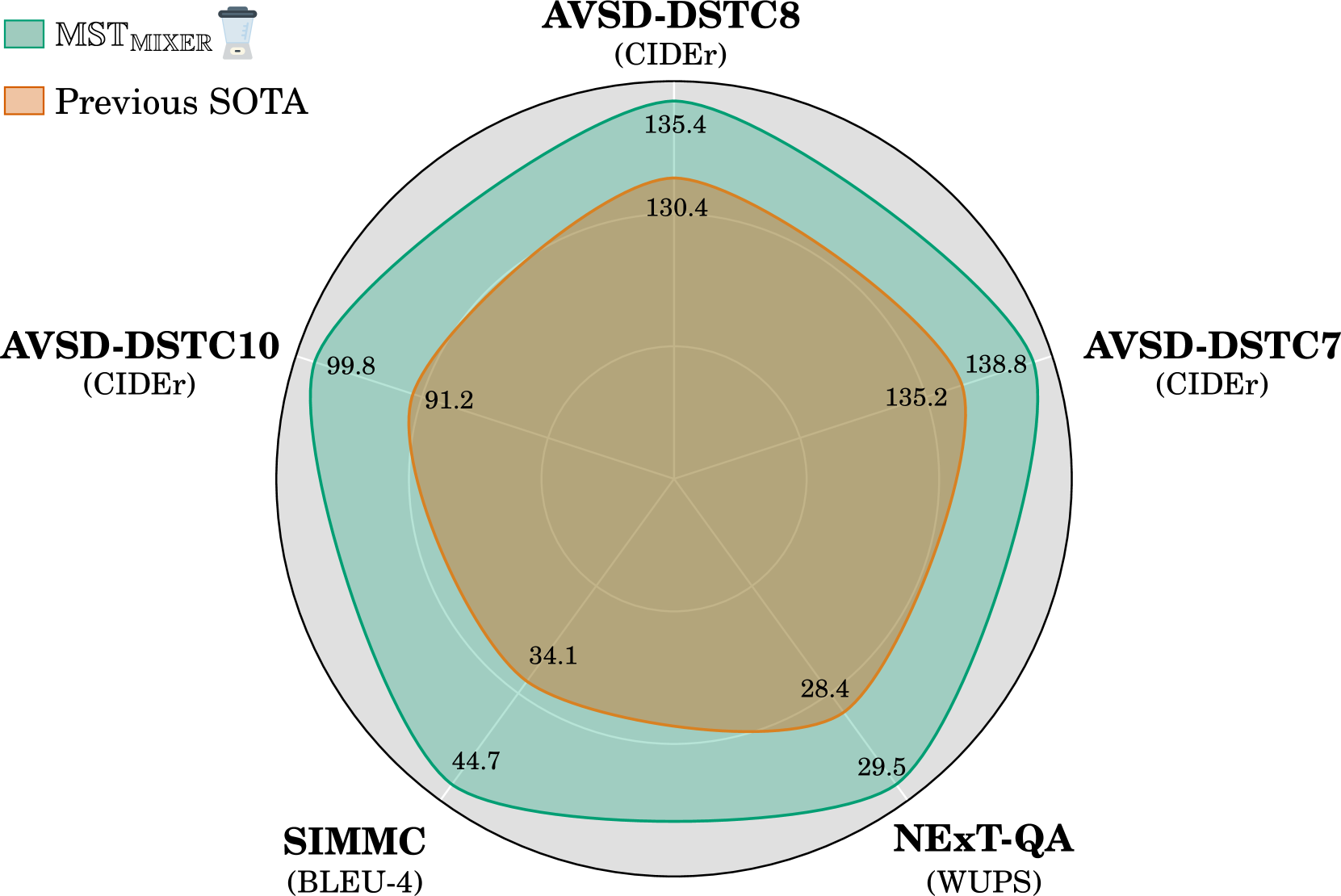
We present MST-MIXER - a novel video dialog model operating over a generic multi-modal state tracking scheme. Current models that claim to perform multi-modal state tracking fall short of two major aspects: (1) They either track only one modality (mostly the visual input) or (2) they target synthetic datasets that do not reflect the complexity of real-world in the wild scenarios. Our model addresses these two limitations in an attempt to close this crucial research gap. Specifically, MST-MIXER first tracks the most important constituents of each input modality. Then, it predicts the missing underlying structure of the selected constituents of each modality by learning local latent graphs using a novel multi-modal graph structure learning method. Subsequently, the learned local graphs and features are parsed together to form a global graph operating on the mix of all modalities which further refines its structure and node embeddings. Finally, the fine-grained graph node features are used to enhance the hidden states of the backbone Vision-Language Model (VLM). MST-MIXER achieves new state-of-the-art results on five challenging benchmarks.
Read more7/8/2024
🖼️
0
Enhancing Dialogue State Tracking Models through LLM-backed User-Agents Simulation
Cheng Niu, Xingguang Wang, Xuxin Cheng, Juntong Song, Tong Zhang
Dialogue State Tracking (DST) is designed to monitor the evolving dialogue state in the conversations and plays a pivotal role in developing task-oriented dialogue systems. However, obtaining the annotated data for the DST task is usually a costly endeavor. In this paper, we focus on employing LLMs to generate dialogue data to reduce dialogue collection and annotation costs. Specifically, GPT-4 is used to simulate the user and agent interaction, generating thousands of dialogues annotated with DST labels. Then a two-stage fine-tuning on LLaMA 2 is performed on the generated data and the real data for the DST prediction. Experimental results on two public DST benchmarks show that with the generated dialogue data, our model performs better than the baseline trained solely on real data. In addition, our approach is also capable of adapting to the dynamic demands in real-world scenarios, generating dialogues in new domains swiftly. After replacing dialogue segments in any domain with the corresponding generated ones, the model achieves comparable performance to the model trained on real data.
Read more5/24/2024

0
Multi-Modal Dialogue State Tracking for Playing GuessWhich Game
Wei Pang, Ruixue Duan, Jinfu Yang, Ning Li
GuessWhich is an engaging visual dialogue game that involves interaction between a Questioner Bot (QBot) and an Answer Bot (ABot) in the context of image-guessing. In this game, QBot's objective is to locate a concealed image solely through a series of visually related questions posed to ABot. However, effectively modeling visually related reasoning in QBot's decision-making process poses a significant challenge. Current approaches either lack visual information or rely on a single real image sampled at each round as decoding context, both of which are inadequate for visual reasoning. To address this limitation, we propose a novel approach that focuses on visually related reasoning through the use of a mental model of the undisclosed image. Within this framework, QBot learns to represent mental imagery, enabling robust visual reasoning by tracking the dialogue state. The dialogue state comprises a collection of representations of mental imagery, as well as representations of the entities involved in the conversation. At each round, QBot engages in visually related reasoning using the dialogue state to construct an internal representation, generate relevant questions, and update both the dialogue state and internal representation upon receiving an answer. Our experimental results on the VisDial datasets (v0.5, 0.9, and 1.0) demonstrate the effectiveness of our proposed model, as it achieves new state-of-the-art performance across all metrics and datasets, surpassing previous state-of-the-art models. Codes and datasets from our experiments are freely available at href{https://github.com/xubuvd/GuessWhich}.
Read more8/19/2024