Multi-Modal Video Dialog State Tracking in the Wild

0
Sign in to get full access
Overview
- This paper presents a method for multi-modal video dialog state tracking in real-world scenarios.
- The approach uses video, audio, and text data to track the evolving state of a dialog.
- The research aims to advance the field of multi-modal learning for real-world applications.
Plain English Explanation
The paper describes a system that can follow and understand the progression of a conversation by analyzing the video, audio, and text data associated with it. This could be useful for applications like virtual assistants or automated meeting transcription.
Instead of just looking at the words being said, the system also considers nonverbal cues like body language and tone of voice. This multi-modal approach allows the system to better comprehend the context and intent behind the dialog.
For example, if someone says "I'm fine" while looking upset and speaking in a frustrated tone, the system would recognize that they are likely not actually doing well, even though the literal words convey a positive sentiment. Integrating these different modalities enables more nuanced and accurate dialog tracking.
The paper evaluates the system on real-world video dialog datasets, showing that it can effectively follow the ebb and flow of natural conversations. This represents an advancement over previous dialog tracking approaches that were more limited in their scope and capabilities.
Technical Explanation
The core of the system is a multi-modal transformer model that takes in video, audio, and text data associated with a dialog and outputs a representation of the current dialog state. The model leverages cross-attention mechanisms to fuse the information from the different modalities.
The video input is processed using a 3D convolutional neural network to extract visual features, while the audio is processed using a audio transformer to get acoustic features. The text is encoded using a language model. These modality-specific representations are then combined in the multi-modal transformer.
The dialog state is modeled as a set of dialog acts, which represent the intentions and meanings conveyed by the speakers. The model is trained to predict the sequence of dialog acts that best match the observed multi-modal input.
Experiments on benchmark datasets show that the multi-modal approach outperforms text-only dialog state tracking, validating the importance of leveraging visual and acoustic information. The model also demonstrates robustness to noisy or incomplete inputs, a key requirement for real-world applications.
Critical Analysis
The paper makes a compelling case for the value of multi-modal dialog state tracking, but there are a few areas that could benefit from further exploration:
-
The experiments are conducted on pre-recorded video dialogs, so it's unclear how well the system would perform in truly real-time, interactive scenarios. Additional testing in more dynamic settings would help assess its practical viability.
-
The paper does not provide much insight into the failure modes of the system or the types of dialog situations where it struggles. A more in-depth error analysis could help identify areas for future improvement.
-
While the multi-modal approach is shown to outperform text-only baselines, the relative contribution of the different modalities is not well explored. A more granular ablation study could shed light on which signals are most critical for accurate dialog tracking.
Overall, this work represents a meaningful step forward in multi-modal dialog understanding, but further research and real-world deployment would be needed to fully evaluate its strengths and limitations.
Conclusion
This paper presents an innovative approach for tracking the state of multi-party dialogs by integrating visual, acoustic, and textual information. The proposed multi-modal transformer model demonstrates strong performance on benchmark datasets, highlighting the value of considering nonverbal cues alongside the spoken words.
By advancing the state-of-the-art in this area, the research opens up new possibilities for applications like virtual assistants, meeting transcription tools, and other systems that need to deeply comprehend human conversations. While further work is needed to fully validate the approach, this work represents an important contribution to the field of multi-modal learning for real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Modal Video Dialog State Tracking in the Wild
Adnen Abdessaied, Lei Shi, Andreas Bulling
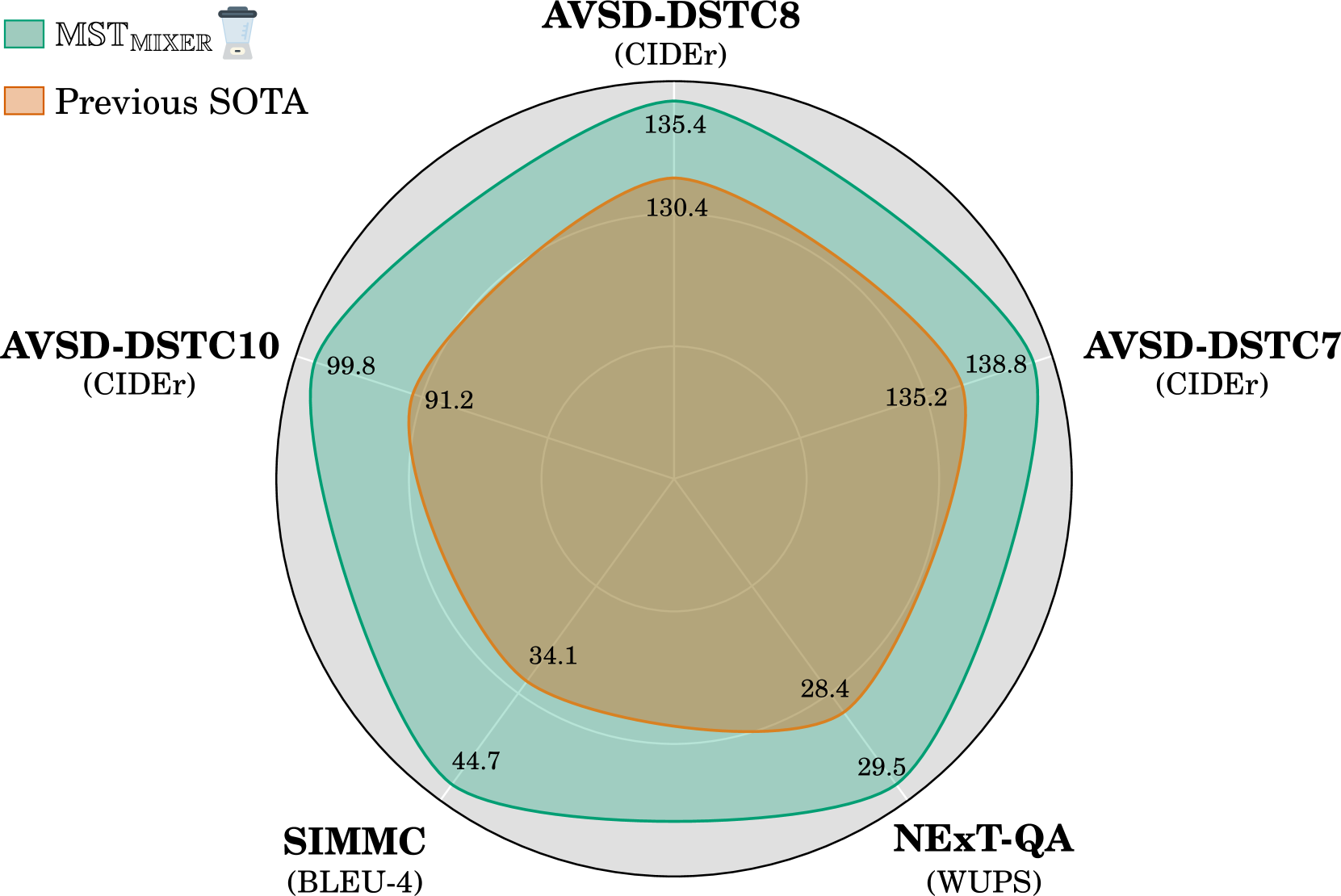
We present MST-MIXER - a novel video dialog model operating over a generic multi-modal state tracking scheme. Current models that claim to perform multi-modal state tracking fall short of two major aspects: (1) They either track only one modality (mostly the visual input) or (2) they target synthetic datasets that do not reflect the complexity of real-world in the wild scenarios. Our model addresses these two limitations in an attempt to close this crucial research gap. Specifically, MST-MIXER first tracks the most important constituents of each input modality. Then, it predicts the missing underlying structure of the selected constituents of each modality by learning local latent graphs using a novel multi-modal graph structure learning method. Subsequently, the learned local graphs and features are parsed together to form a global graph operating on the mix of all modalities which further refines its structure and node embeddings. Finally, the fine-grained graph node features are used to enhance the hidden states of the backbone Vision-Language Model (VLM). MST-MIXER achieves new state-of-the-art results on five challenging benchmarks.
Read more7/8/2024

0
Enhancing Visual Dialog State Tracking through Iterative Object-Entity Alignment in Multi-Round Conversations
Wei Pang, Ruixue Duan, Jinfu Yang, Ning Li
Visual Dialog (VD) is a task where an agent answers a series of image-related questions based on a multi-round dialog history. However, previous VD methods often treat the entire dialog history as a simple text input, disregarding the inherent conversational information flows at the round level. In this paper, we introduce Multi-round Dialogue State Tracking model (MDST), a framework that addresses this limitation by leveraging the dialogue state learned from dialog history to answer questions. MDST captures each round of dialog history, constructing internal dialogue state representations defined as 2-tuples of vision-language representations. These representations effectively ground the current question, enabling the generation of accurate answers. Experimental results on the VisDial v1.0 dataset demonstrate that MDST achieves a new state-of-the-art performance in generative setting. Furthermore, through a series of human studies, we validate the effectiveness of MDST in generating long, consistent, and human-like answers while consistently answering a series of questions correctly.
Read more8/14/2024

0
Global-Local Distillation Network-Based Audio-Visual Speaker Tracking with Incomplete Modalities
Yidi Li, Yihan Li, Yixin Guo, Bin Ren, Zhenhuan Xu, Hao Guo, Hong Liu, Nicu Sebe
In speaker tracking research, integrating and complementing multi-modal data is a crucial strategy for improving the accuracy and robustness of tracking systems. However, tracking with incomplete modalities remains a challenging issue due to noisy observations caused by occlusion, acoustic noise, and sensor failures. Especially when there is missing data in multiple modalities, the performance of existing multi-modal fusion methods tends to decrease. To this end, we propose a Global-Local Distillation-based Tracker (GLDTracker) for robust audio-visual speaker tracking. GLDTracker is driven by a teacher-student distillation model, enabling the flexible fusion of incomplete information from each modality. The teacher network processes global signals captured by camera and microphone arrays, and the student network handles local information subject to visual occlusion and missing audio channels. By transferring knowledge from teacher to student, the student network can better adapt to complex dynamic scenes with incomplete observations. In the student network, a global feature reconstruction module based on the generative adversarial network is constructed to reconstruct global features from feature embedding with missing local information. Furthermore, a multi-modal multi-level fusion attention is introduced to integrate the incomplete feature and the reconstructed feature, leveraging the complementarity and consistency of audio-visual and global-local features. Experimental results on the AV16.3 dataset demonstrate that the proposed GLDTracker outperforms existing state-of-the-art audio-visual trackers and achieves leading performance on both standard and incomplete modalities datasets, highlighting its superiority and robustness in complex conditions. The code and models will be available.
Read more8/28/2024
🌐
0
Towards Multi-Task Multi-Modal Models: A Video Generative Perspective
Lijun Yu
Advancements in language foundation models have primarily fueled the recent surge in artificial intelligence. In contrast, generative learning of non-textual modalities, especially videos, significantly trails behind language modeling. This thesis chronicles our endeavor to build multi-task models for generating videos and other modalities under diverse conditions, as well as for understanding and compression applications. Given the high dimensionality of visual data, we pursue concise and accurate latent representations. Our video-native spatial-temporal tokenizers preserve high fidelity. We unveil a novel approach to mapping bidirectionally between visual observation and interpretable lexical terms. Furthermore, our scalable visual token representation proves beneficial across generation, compression, and understanding tasks. This achievement marks the first instances of language models surpassing diffusion models in visual synthesis and a video tokenizer outperforming industry-standard codecs. Within these multi-modal latent spaces, we study the design of multi-task generative models. Our masked multi-task transformer excels at the quality, efficiency, and flexibility of video generation. We enable a frozen language model, trained solely on text, to generate visual content. Finally, we build a scalable generative multi-modal transformer trained from scratch, enabling the generation of videos containing high-fidelity motion with the corresponding audio given diverse conditions. Throughout the course, we have shown the effectiveness of integrating multiple tasks, crafting high-fidelity latent representation, and generating multiple modalities. This work suggests intriguing potential for future exploration in generating non-textual data and enabling real-time, interactive experiences across various media forms.
Read more5/28/2024