Multi-Modal Dialogue State Tracking for Playing GuessWhich Game

0

Sign in to get full access
Overview
- This paper proposes a multi-modal dialogue state tracking approach for playing the "GuessWhich" game, which involves identifying an object in an image based on a series of questions and answers.
- The approach combines language and visual information to track the state of the dialogue and make accurate guesses about the target object.
- The authors evaluate their model on the GuessWhich dataset and demonstrate its effectiveness in comparison to other state-of-the-art methods.
Plain English Explanation
The paper describes a system that can play a game called "GuessWhich," where the goal is to identify a specific object in an image by asking questions and receiving answers. To do this, the system uses both the language information in the questions and answers, as well as the visual information from the image.
The key idea is to track the state of the dialogue as it progresses, using both the text and the image, in order to make an accurate guess about the target object. This allows the system to understand the context and relevance of each question and answer, and use that information to narrow down the possibilities.
The authors evaluate their model on a dataset specifically designed for the GuessWhich game, and show that it outperforms other state-of-the-art approaches. This suggests that their multi-modal approach, which combines language and visual information, is an effective way to tackle this type of visual dialogue task.
Technical Explanation
The paper introduces a multi-modal dialogue state tracking approach for playing the GuessWhich game. The key components of their system include:
- A language model that processes the questions and answers to extract relevant information about the target object.
- A visual model that analyzes the image to identify salient visual features and attributes.
- A dialogue state tracker that integrates the language and visual information to maintain a representation of the current state of the dialogue.
The authors evaluate their model on the GuessWhich dataset, which consists of dialogues where one player tries to identify an object in an image by asking questions, and the other player responds. They show that their approach outperforms other state-of-the-art methods, demonstrating the effectiveness of combining language and visual information for this type of visual dialogue task.
Critical Analysis
The paper provides a novel multi-modal approach to dialogue state tracking for the GuessWhich game, which is an important step forward in the field of visual dialogue systems. However, the authors acknowledge some limitations of their work, such as the relatively small size of the GuessWhich dataset and the potential for overfitting.
Additionally, the paper does not address potential biases in the dataset or the model, which could be an important consideration for real-world applications. Further research is needed to explore the generalizability of the approach to other visual dialogue tasks and datasets.
Overall, the paper presents an interesting and promising multi-modal dialogue state tracking solution, but there is still room for improvement and further investigation to fully realize the potential of this approach.
Conclusion
This paper introduces a multi-modal dialogue state tracking approach for playing the GuessWhich game, which combines language and visual information to accurately identify a target object in an image. The authors demonstrate the effectiveness of their model on the GuessWhich dataset, suggesting that this type of visual dialogue system can be a powerful tool for human-computer interaction.
While the paper presents a valuable contribution to the field, there are some limitations that should be addressed in future research. Nonetheless, the multi-modal approach showcased in this work represents an important step forward in the development of more robust and capable visual dialogue systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Modal Dialogue State Tracking for Playing GuessWhich Game
Wei Pang, Ruixue Duan, Jinfu Yang, Ning Li
GuessWhich is an engaging visual dialogue game that involves interaction between a Questioner Bot (QBot) and an Answer Bot (ABot) in the context of image-guessing. In this game, QBot's objective is to locate a concealed image solely through a series of visually related questions posed to ABot. However, effectively modeling visually related reasoning in QBot's decision-making process poses a significant challenge. Current approaches either lack visual information or rely on a single real image sampled at each round as decoding context, both of which are inadequate for visual reasoning. To address this limitation, we propose a novel approach that focuses on visually related reasoning through the use of a mental model of the undisclosed image. Within this framework, QBot learns to represent mental imagery, enabling robust visual reasoning by tracking the dialogue state. The dialogue state comprises a collection of representations of mental imagery, as well as representations of the entities involved in the conversation. At each round, QBot engages in visually related reasoning using the dialogue state to construct an internal representation, generate relevant questions, and update both the dialogue state and internal representation upon receiving an answer. Our experimental results on the VisDial datasets (v0.5, 0.9, and 1.0) demonstrate the effectiveness of our proposed model, as it achieves new state-of-the-art performance across all metrics and datasets, surpassing previous state-of-the-art models. Codes and datasets from our experiments are freely available at href{https://github.com/xubuvd/GuessWhich}.
Read more8/19/2024

0
Enhancing Visual Dialog State Tracking through Iterative Object-Entity Alignment in Multi-Round Conversations
Wei Pang, Ruixue Duan, Jinfu Yang, Ning Li
Visual Dialog (VD) is a task where an agent answers a series of image-related questions based on a multi-round dialog history. However, previous VD methods often treat the entire dialog history as a simple text input, disregarding the inherent conversational information flows at the round level. In this paper, we introduce Multi-round Dialogue State Tracking model (MDST), a framework that addresses this limitation by leveraging the dialogue state learned from dialog history to answer questions. MDST captures each round of dialog history, constructing internal dialogue state representations defined as 2-tuples of vision-language representations. These representations effectively ground the current question, enabling the generation of accurate answers. Experimental results on the VisDial v1.0 dataset demonstrate that MDST achieves a new state-of-the-art performance in generative setting. Furthermore, through a series of human studies, we validate the effectiveness of MDST in generating long, consistent, and human-like answers while consistently answering a series of questions correctly.
Read more8/14/2024
🤿
0
Open-Ended Multi-Modal Relational Reasoning for Video Question Answering
Haozheng Luo, Ruiyang Qin, Chenwei Xu, Guo Ye, Zening Luo
In this paper, we introduce a robotic agent specifically designed to analyze external environments and address participants' questions. The primary focus of this agent is to assist individuals using language-based interactions within video-based scenes. Our proposed method integrates video recognition technology and natural language processing models within the robotic agent. We investigate the crucial factors affecting human-robot interactions by examining pertinent issues arising between participants and robot agents. Methodologically, our experimental findings reveal a positive relationship between trust and interaction efficiency. Furthermore, our model demonstrates a 2% to 3% performance enhancement in comparison to other benchmark methods.
Read more6/12/2024
0
Multi-Modal Video Dialog State Tracking in the Wild
Adnen Abdessaied, Lei Shi, Andreas Bulling
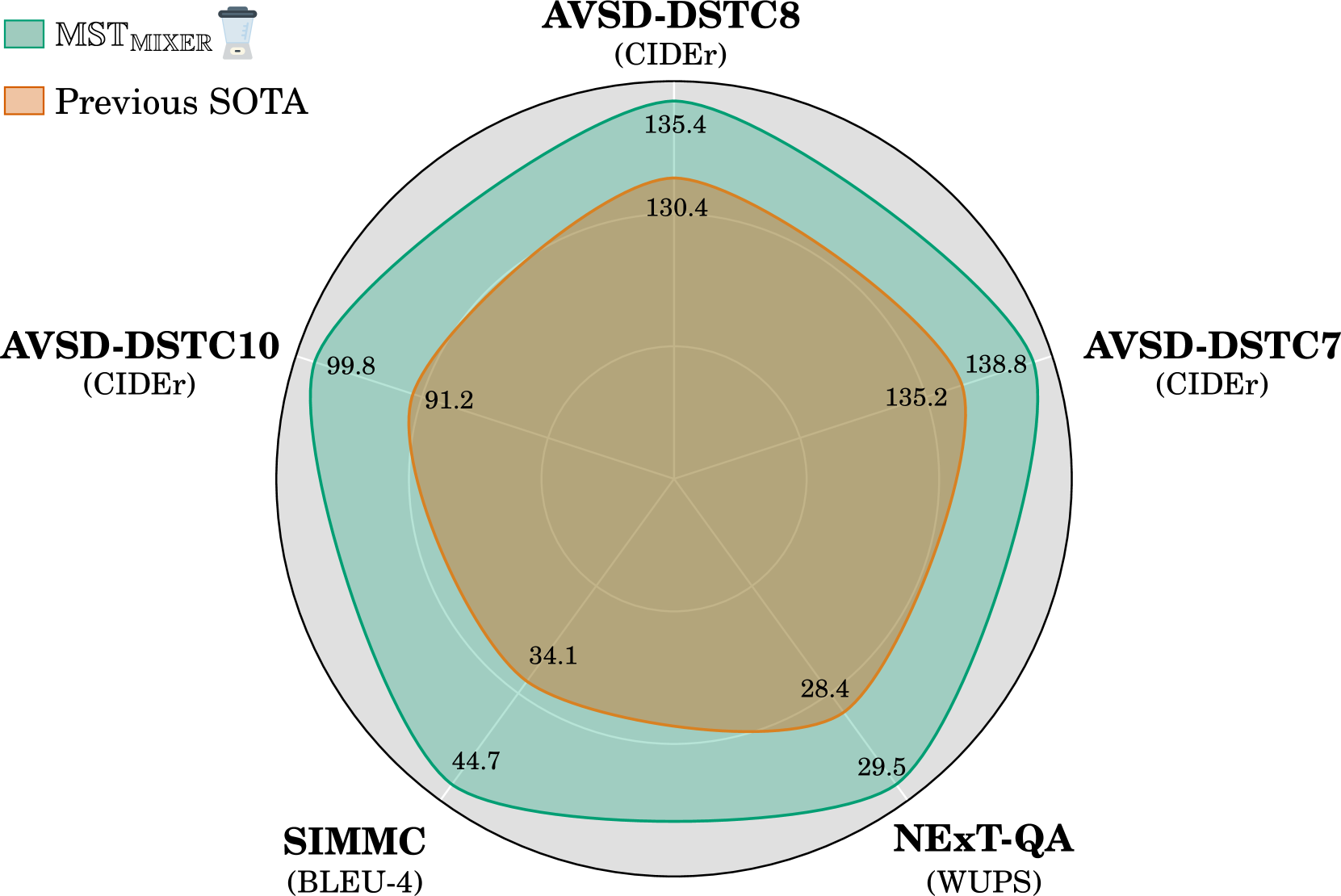
We present MST-MIXER - a novel video dialog model operating over a generic multi-modal state tracking scheme. Current models that claim to perform multi-modal state tracking fall short of two major aspects: (1) They either track only one modality (mostly the visual input) or (2) they target synthetic datasets that do not reflect the complexity of real-world in the wild scenarios. Our model addresses these two limitations in an attempt to close this crucial research gap. Specifically, MST-MIXER first tracks the most important constituents of each input modality. Then, it predicts the missing underlying structure of the selected constituents of each modality by learning local latent graphs using a novel multi-modal graph structure learning method. Subsequently, the learned local graphs and features are parsed together to form a global graph operating on the mix of all modalities which further refines its structure and node embeddings. Finally, the fine-grained graph node features are used to enhance the hidden states of the backbone Vision-Language Model (VLM). MST-MIXER achieves new state-of-the-art results on five challenging benchmarks.
Read more7/8/2024