CrashEventLLM: Predicting System Crashes with Large Language Models

0
Sign in to get full access
Overview
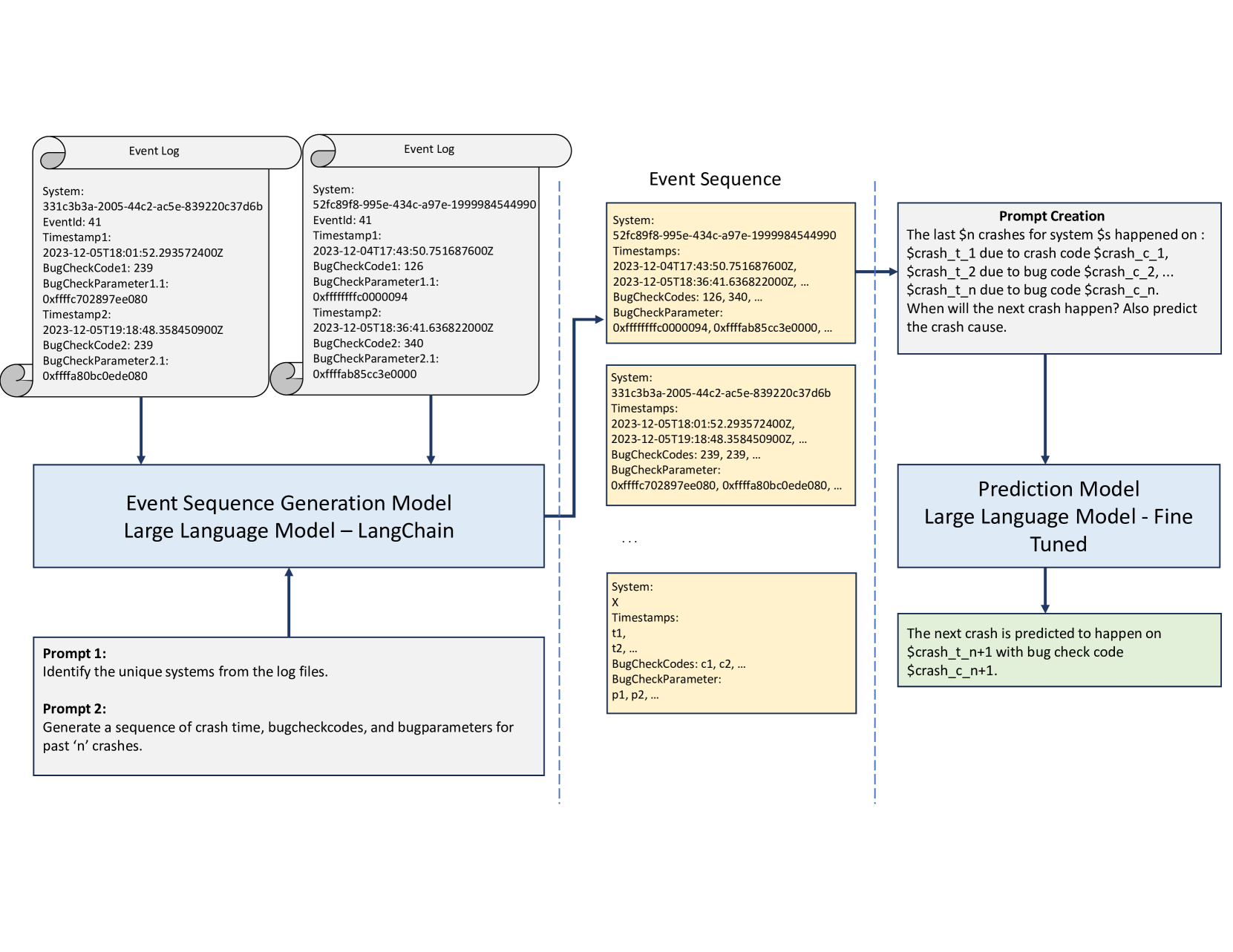
- This paper proposes a novel framework called CrashEventLLM for predicting system crashes using large language models (LLMs).
- The key idea is to leverage the text-based nature of software logs to train LLMs for the task of crash prediction.
- The authors conduct extensive experiments on real-world datasets and demonstrate the effectiveness of their approach compared to traditional machine learning methods.
Plain English Explanation
The paper introduces a new way to predict when computer systems will crash or fail using large language models (LLMs). LLMs are AI models that are trained on huge amounts of text data and can understand and generate natural language.
The main insight is that software logs, which record events and errors that happen in computer systems, are essentially text data. By training an LLM on these software logs, it can learn to recognize patterns that indicate an impending crash or failure. This is more powerful than traditional machine learning approaches, which may struggle to capture the complex relationships in log data.
The researchers developed a framework called CrashEventLLM that leverages LLMs for crash prediction. They tested it on real-world datasets and found it outperformed other machine learning methods. The key advantage is that LLMs can extract more meaningful insights from the unstructured log data, allowing for more accurate predictions of when a system is likely to crash.
Technical Explanation
The CrashEventLLM framework works by first preprocessing the software log data into a format suitable for training an LLM. This involves tasks like tokenization, padding, and creating training/validation/test sets.
The authors then fine-tune a pre-trained LLM (such as GPT-3) on the log data, using a combination of supervised and unsupervised learning techniques. The supervised task is to predict whether a given log entry corresponds to a crash event or not. The unsupervised component allows the model to learn general patterns and representations from the log data.
Once trained, the CrashEventLLM model can be used to make predictions on new log data. It outputs a probability score indicating the likelihood of a crash occurring. The researchers compare this approach to traditional machine learning models like random forests and find that CrashEventLLM achieves significantly higher accuracy.
Critical Analysis
The paper provides a compelling demonstration of how LLMs can be effectively applied to the problem of crash prediction in computer systems. The authors acknowledge that their approach relies on the availability of high-quality log data, which may not always be the case in real-world settings.
Additionally, the paper does not explore the interpretability of the CrashEventLLM model - it is not clear what specific patterns or features the LLM is learning to make its predictions. This lack of interpretability could be a limitation in certain applications where explainability is important.
Further research could investigate ways to improve the transparency of the LLM-based crash prediction system, perhaps by incorporating techniques like constrained-based causal discovery or event-based clustering. Additionally, studying the model's performance on a wider range of datasets and systems would help validate the generalizability of the approach.
Conclusion
This paper presents a novel framework called CrashEventLLM that leverages the power of large language models to predict system crashes from software log data. The authors demonstrate the effectiveness of their approach on real-world datasets, showing significant improvements over traditional machine learning methods.
The work highlights the potential of LLMs to tackle complex problems in the domain of system monitoring and reliability. As computer systems become increasingly complex, tools like CrashEventLLM could play a crucial role in proactively identifying and mitigating system failures, leading to more robust and reliable software infrastructure.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CrashEventLLM: Predicting System Crashes with Large Language Models
Priyanka Mudgal, Bijan Arbab, Swaathi Sampath Kumar
As the dependence on computer systems expands across various domains, focusing on personal, industrial, and large-scale applications, there arises a compelling need to enhance their reliability to sustain business operations seamlessly and ensure optimal user satisfaction. System logs generated by these devices serve as valuable repositories of historical trends and past failures. The use of machine learning techniques for failure prediction has become commonplace, enabling the extraction of insights from past data to anticipate future behavior patterns. Recently, large language models have demonstrated remarkable capabilities in tasks including summarization, reasoning, and event prediction. Therefore, in this paper, we endeavor to investigate the potential of large language models in predicting system failures, leveraging insights learned from past failure behavior to inform reasoning and decision-making processes effectively. Our approach involves leveraging data from the Intel Computing Improvement Program (ICIP) system crash logs to identify significant events and develop CrashEventLLM. This model, built upon a large language model framework, serves as our foundation for crash event prediction. Specifically, our model utilizes historical data to forecast future crash events, informed by expert annotations. Additionally, it goes beyond mere prediction, offering insights into potential causes for each crash event. This work provides the preliminary insights into prompt-based large language models for the log-based event prediction task.
Read more7/30/2024

0
Learning Traffic Crashes as Language: Datasets, Benchmarks, and What-if Causal Analyses
Zhiwen Fan, Pu Wang, Yang Zhao, Yibo Zhao, Boris Ivanovic, Zhangyang Wang, Marco Pavone, Hao Frank Yang
The increasing rate of road accidents worldwide results not only in significant loss of life but also imposes billions financial burdens on societies. Current research in traffic crash frequency modeling and analysis has predominantly approached the problem as classification tasks, focusing mainly on learning-based classification or ensemble learning methods. These approaches often overlook the intricate relationships among the complex infrastructure, environmental, human and contextual factors related to traffic crashes and risky situations. In contrast, we initially propose a large-scale traffic crash language dataset, named CrashEvent, summarizing 19,340 real-world crash reports and incorporating infrastructure data, environmental and traffic textual and visual information in Washington State. Leveraging this rich dataset, we further formulate the crash event feature learning as a novel text reasoning problem and further fine-tune various large language models (LLMs) to predict detailed accident outcomes, such as crash types, severity and number of injuries, based on contextual and environmental factors. The proposed model, CrashLLM, distinguishes itself from existing solutions by leveraging the inherent text reasoning capabilities of LLMs to parse and learn from complex, unstructured data, thereby enabling a more nuanced analysis of contributing factors. Our experiments results shows that our LLM-based approach not only predicts the severity of accidents but also classifies different types of accidents and predicts injury outcomes, all with averaged F1 score boosted from 34.9% to 53.8%. Furthermore, CrashLLM can provide valuable insights for numerous open-world what-if situational-awareness traffic safety analyses with learned reasoning features, which existing models cannot offer. We make our benchmark, datasets, and model public available for further exploration.
Read more6/18/2024

0
Epidemic Information Extraction for Event-Based Surveillance using Large Language Models
Sergio Consoli, Peter Markov, Nikolaos I. Stilianakis, Lorenzo Bertolini, Antonio Puertas Gallardo, Mario Ceresa
This paper presents a novel approach to epidemic surveillance, leveraging the power of Artificial Intelligence and Large Language Models (LLMs) for effective interpretation of unstructured big data sources, like the popular ProMED and WHO Disease Outbreak News. We explore several LLMs, evaluating their capabilities in extracting valuable epidemic information. We further enhance the capabilities of the LLMs using in-context learning, and test the performance of an ensemble model incorporating multiple open-source LLMs. The findings indicate that LLMs can significantly enhance the accuracy and timeliness of epidemic modelling and forecasting, offering a promising tool for managing future pandemic events.
Read more8/27/2024

0
Exploring the extent of similarities in software failures across industries using LLMs
Martin Detloff
The rapid evolution of software development necessitates enhanced safety measures. Extracting information about software failures from companies is becoming increasingly more available through news articles. This research utilizes the Failure Analysis Investigation with LLMs (FAIL) model to extract industry-specific information. Although the FAIL model's database is rich in information, it could benefit from further categorization and industry-specific insights to further assist software engineers. In previous work news articles were collected from reputable sources and categorized by incidents inside a database. Prompt engineering and Large Language Models (LLMs) were then applied to extract relevant information regarding the software failure. This research extends these methods by categorizing articles into specific domains and types of software failures. The results are visually represented through graphs. The analysis shows that throughout the database some software failures occur significantly more often in specific industries. This categorization provides a valuable resource for software engineers and companies to identify and address common failures. This research highlights the synergy between software engineering and Large Language Models (LLMs) to automate and enhance the analysis of software failures. By transforming data from the database into an industry specific model, we provide a valuable resource that can be used to identify common vulnerabilities, predict potential risks, and implement proactive measures for preventing software failures. Leveraging the power of the current FAIL database and data visualization, we aim to provide an avenue for safer and more secure software in the future.
Read more8/9/2024