How to Evaluate Entity Resolution Systems: An Entity-Centric Framework with Application to Inventor Name Disambiguation
2404.05622
0
0

Abstract
Entity resolution (record linkage, microclustering) systems are notoriously difficult to evaluate. Looking for a needle in a haystack, traditional evaluation methods use sophisticated, application-specific sampling schemes to find matching pairs of records among an immense number of non-matches. We propose an alternative that facilitates the creation of representative, reusable benchmark data sets without necessitating complex sampling schemes. These benchmark data sets can then be used for model training and a variety of evaluation tasks. Specifically, we propose an entity-centric data labeling methodology that integrates with a unified framework for monitoring summary statistics, estimating key performance metrics such as cluster and pairwise precision and recall, and analyzing root causes for errors. We validate the framework in an application to inventor name disambiguation and through simulation studies. Software: https://github.com/OlivierBinette/er-evaluation/
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a framework for evaluating entity resolution systems, with a focus on inventor name disambiguation.
- The framework emphasizes an entity-centric approach, which aims to assess the quality of entity-level outputs rather than just overall system performance.
- The authors apply this framework to evaluate different entity resolution techniques for the task of inventor name disambiguation, providing insights into the strengths and weaknesses of each approach.
Plain English Explanation
Entity resolution is the process of identifying and matching references to the same real-world entity, such as a person, organization, or product, across different data sources. This is a crucial task in many applications, including academic research on inventor name disambiguation.
The authors of this paper argue that existing evaluation methods for entity resolution systems often focus on overall system performance, such as precision and recall, without adequately capturing the quality of the entity-level outputs. To address this, they propose a new framework that takes an "entity-centric" approach, which means it looks at how well the system performs at the individual entity level rather than just the aggregate.
The authors apply this framework to the specific problem of inventor name disambiguation, where the goal is to accurately match patent records to the correct inventor. This is a challenging task due to factors like common names, name variations, and incomplete or inconsistent data.
By using the entity-centric approach, the authors are able to provide more detailed insights into the strengths and weaknesses of different entity resolution techniques for this task. This can help researchers and practitioners choose the right tools and methods for their specific needs, and also identify areas for improvement in the field of information extraction and entity disambiguation.
Technical Explanation
The paper proposes an "entity-centric" framework for evaluating entity resolution systems, which focuses on assessing the quality of entity-level outputs rather than just overall system performance metrics like precision and recall.
The key elements of the framework include:
- Entity-level Metrics: The authors define several entity-level metrics, such as entity-level precision, recall, and F1 score, to capture how accurately the system identifies and matches entities.
- Entity Profiles: The framework also considers the "profiles" of individual entities, including attributes like name, address, and affiliation, to provide a more nuanced evaluation.
- Entity-centric Visualization: The authors introduce visualization techniques to help interpret the entity-level performance of the system, such as scatter plots and heatmaps.
The authors apply this framework to evaluate different entity resolution techniques for the task of inventor name disambiguation, using a dataset of patent records. They compare the performance of various approaches, including rule-based, machine learning, and hybrid methods, and provide insights into the strengths and weaknesses of each.
Critical Analysis
The authors acknowledge several limitations of their proposed framework, including the need for high-quality ground truth data and the challenge of generalizing the findings to other entity resolution tasks.
Additionally, the framework focuses on entity-level metrics, which may not always align with the end-user's priorities or the overall system objectives. In some cases, a higher-level, task-specific evaluation may be more appropriate.
The authors also note that the entity-centric approach can be computationally intensive, especially for large-scale datasets, and may require additional effort to interpret the results.
Despite these limitations, the framework represents a valuable contribution to the field of entity resolution evaluation, as it provides a more nuanced and comprehensive way to assess the performance of these systems. The insights gained from the inventor name disambiguation case study can also inform the development of improved entity resolution techniques and the design of future evaluation methodologies.
Conclusion
This paper presents an entity-centric framework for evaluating entity resolution systems, with a focus on the task of inventor name disambiguation. The proposed approach aims to provide a more comprehensive and nuanced assessment of system performance by considering entity-level metrics and profiles, rather than just overall precision and recall.
The authors' application of this framework to various entity resolution techniques for inventor name disambiguation offers valuable insights for researchers and practitioners in the field. While the framework has some limitations, it represents a significant step forward in the evaluation of entity resolution systems and can help drive further advancements in information extraction and entity disambiguation technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Cost-Efficient Prompt Engineering for Unsupervised Entity Resolution
Navapat Nananukul, Khanin Sisaengsuwanchai, Mayank Kejriwal
0
0
Entity Resolution (ER) is the problem of semi-automatically determining when two entities refer to the same underlying entity, with applications ranging from healthcare to e-commerce. Traditional ER solutions required considerable manual expertise, including domain-specific feature engineering, as well as identification and curation of training data. Recently released large language models (LLMs) provide an opportunity to make ER more seamless and domain-independent. However, it is also well known that LLMs can pose risks, and that the quality of their outputs can depend on how prompts are engineered. Unfortunately, a systematic experimental study on the effects of different prompting methods for addressing unsupervised ER, using LLMs like ChatGPT, has been lacking thus far. This paper aims to address this gap by conducting such a study. We consider some relatively simple and cost-efficient ER prompt engineering methods and apply them to ER on two real-world datasets widely used in the community. We use an extensive set of experimental results to show that an LLM like GPT3.5 is viable for high-performing unsupervised ER, and interestingly, that more complicated and detailed (and hence, expensive) prompting methods do not necessarily outperform simpler approaches. We provide brief discussions on qualitative and error analysis, including a study of the inter-consistency of different prompting methods to determine whether they yield stable outputs. Finally, we consider some limitations of LLMs when applied to ER.
4/9/2024

Entity Disambiguation via Fusion Entity Decoding
Junxiong Wang, Ali Mousavi, Omar Attia, Ronak Pradeep, Saloni Potdar, Alexander M. Rush, Umar Farooq Minhas, Yunyao Li
0
0
Entity disambiguation (ED), which links the mentions of ambiguous entities to their referent entities in a knowledge base, serves as a core component in entity linking (EL). Existing generative approaches demonstrate improved accuracy compared to classification approaches under the standardized ZELDA benchmark. Nevertheless, generative approaches suffer from the need for large-scale pre-training and inefficient generation. Most importantly, entity descriptions, which could contain crucial information to distinguish similar entities from each other, are often overlooked. We propose an encoder-decoder model to disambiguate entities with more detailed entity descriptions. Given text and candidate entities, the encoder learns interactions between the text and each candidate entity, producing representations for each entity candidate. The decoder then fuses the representations of entity candidates together and selects the correct entity. Our experiments, conducted on various entity disambiguation benchmarks, demonstrate the strong and robust performance of this model, particularly +1.5% in the ZELDA benchmark compared with GENRE. Furthermore, we integrate this approach into the retrieval/reader framework and observe +1.5% improvements in end-to-end entity linking in the GERBIL benchmark compared with EntQA.
5/9/2024
⛏️
A Decoupling and Aggregating Framework for Joint Extraction of Entities and Relations
Yao Wang, Xin Liu, Weikun Kong, Hai-Tao Yu, Teeradaj Racharak, Kyoung-Sook Kim, Minh Le Nguyen
0
0
Named Entity Recognition and Relation Extraction are two crucial and challenging subtasks in the field of Information Extraction. Despite the successes achieved by the traditional approaches, fundamental research questions remain open. First, most recent studies use parameter sharing for a single subtask or shared features for both two subtasks, ignoring their semantic differences. Second, information interaction mainly focuses on the two subtasks, leaving the fine-grained informtion interaction among the subtask-specific features of encoding subjects, relations, and objects unexplored. Motivated by the aforementioned limitations, we propose a novel model to jointly extract entities and relations. The main novelties are as follows: (1) We propose to decouple the feature encoding process into three parts, namely encoding subjects, encoding objects, and encoding relations. Thanks to this, we are able to use fine-grained subtask-specific features. (2) We propose novel inter-aggregation and intra-aggregation strategies to enhance the information interaction and construct individual fine-grained subtask-specific features, respectively. The experimental results demonstrate that our model outperforms several previous state-of-the-art models. Extensive additional experiments further confirm the effectiveness of our model.
5/15/2024
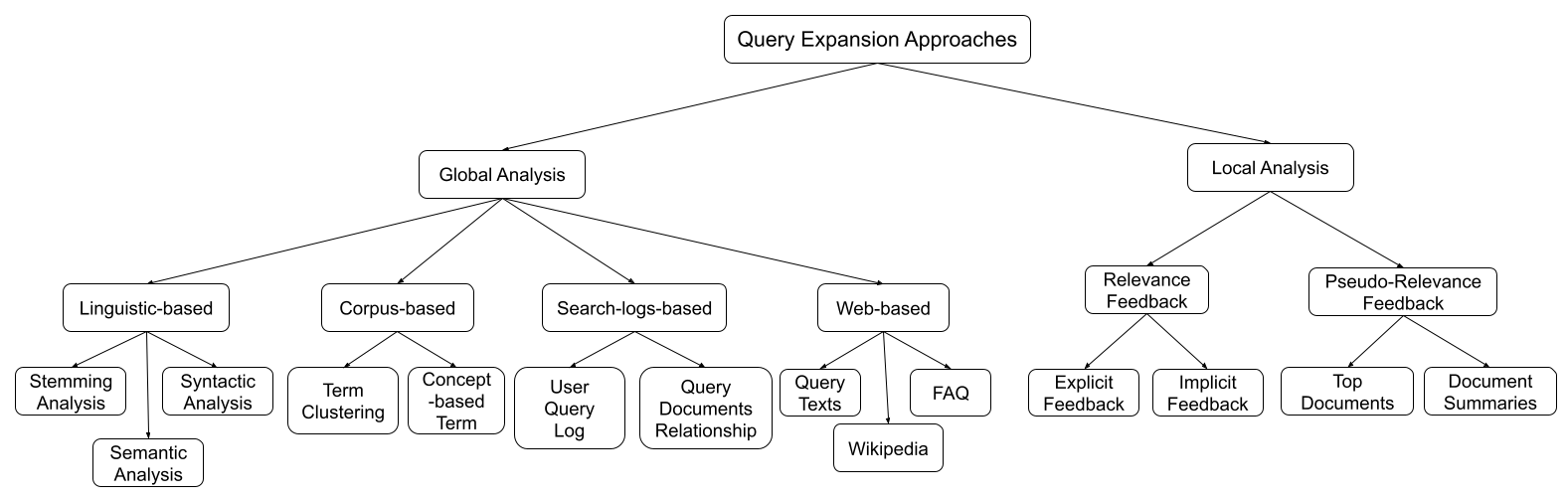
Information Retrieval with Entity Linking
Dahlia Shehata
0
0
Despite the advantages of their low-resource settings, traditional sparse retrievers depend on exact matching approaches between high-dimensional bag-of-words (BoW) representations of both the queries and the collection. As a result, retrieval performance is restricted by semantic discrepancies and vocabulary gaps. On the other hand, transformer-based dense retrievers introduce significant improvements in information retrieval tasks by exploiting low-dimensional contextualized representations of the corpus. While dense retrievers are known for their relative effectiveness, they suffer from lower efficiency and lack of generalization issues, when compared to sparse retrievers. For a lightweight retrieval task, high computational resources and time consumption are major barriers encouraging the renunciation of dense models despite potential gains. In this work, I propose boosting the performance of sparse retrievers by expanding both the queries and the documents with linked entities in two formats for the entity names: 1) explicit and 2) hashed. A zero-shot end-to-end dense entity linking system is employed for entity recognition and disambiguation to augment the corpus. By leveraging the advanced entity linking methods, I believe that the effectiveness gap between sparse and dense retrievers can be narrowed. Experiments are conducted on the MS MARCO passage dataset using the original qrel set, the re-ranked qrels favoured by MonoT5 and the latter set further re-ranked by DuoT5. Since I am concerned with the early stage retrieval in cascaded ranking architectures of large information retrieval systems, the results are evaluated using recall@1000. The suggested approach is also capable of retrieving documents for query subsets judged to be particularly difficult in prior work.
4/16/2024