Information Retrieval with Entity Linking
2404.08678
2
0
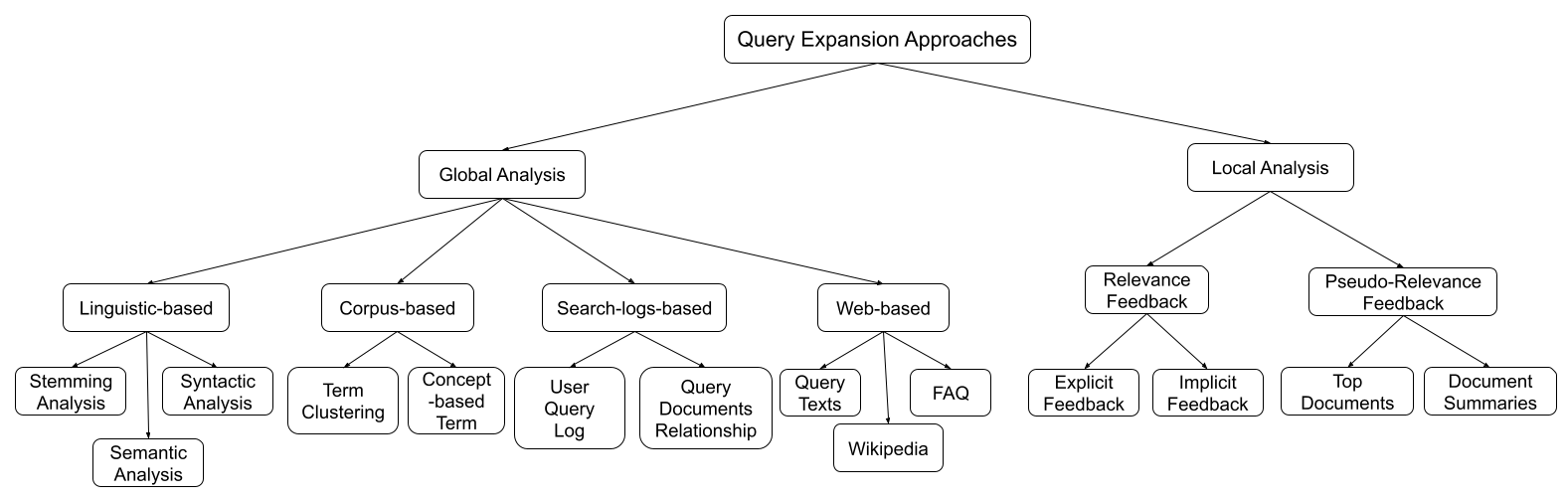
Abstract
Despite the advantages of their low-resource settings, traditional sparse retrievers depend on exact matching approaches between high-dimensional bag-of-words (BoW) representations of both the queries and the collection. As a result, retrieval performance is restricted by semantic discrepancies and vocabulary gaps. On the other hand, transformer-based dense retrievers introduce significant improvements in information retrieval tasks by exploiting low-dimensional contextualized representations of the corpus. While dense retrievers are known for their relative effectiveness, they suffer from lower efficiency and lack of generalization issues, when compared to sparse retrievers. For a lightweight retrieval task, high computational resources and time consumption are major barriers encouraging the renunciation of dense models despite potential gains. In this work, I propose boosting the performance of sparse retrievers by expanding both the queries and the documents with linked entities in two formats for the entity names: 1) explicit and 2) hashed. A zero-shot end-to-end dense entity linking system is employed for entity recognition and disambiguation to augment the corpus. By leveraging the advanced entity linking methods, I believe that the effectiveness gap between sparse and dense retrievers can be narrowed. Experiments are conducted on the MS MARCO passage dataset using the original qrel set, the re-ranked qrels favoured by MonoT5 and the latter set further re-ranked by DuoT5. Since I am concerned with the early stage retrieval in cascaded ranking architectures of large information retrieval systems, the results are evaluated using recall@1000. The suggested approach is also capable of retrieving documents for query subsets judged to be particularly difficult in prior work.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper proposes several novel techniques for enhancing retrieval models, including LLM-Augmented Retrieval, CFIR: Fast and Effective Long Text to Image, Entity Disambiguation via Fusion Entity Decoding, and Leveraging Contextual Information for Effective Entity Salience Detection.
- The paper presents technical details and evaluates the performance of these approaches on various benchmark datasets.
Plain English Explanation
The researchers have developed several new techniques to improve how search engines and other information retrieval systems work. One method is called "LLM-Augmented Retrieval," which combines large language models (like GPT-3) with traditional retrieval algorithms to get better search results. Another approach, "CFIR," speeds up the process of generating images from long text descriptions.
The paper also introduces ways to better identify and disambiguate entities (like people, places, or organizations) mentioned in text, which is important for understanding the meaning of documents. And it presents a technique for detecting which entities are most relevant or important in a given context.
Overall, these innovations aim to make information retrieval systems more accurate, efficient, and contextually aware - helping users find the most relevant and useful information more easily.
Technical Explanation
The paper first introduces LLM-Augmented Retrieval, which combines the strengths of large language models (LLMs) and traditional retrieval models. The authors show how LLMs can be used to expand and refine queries, rerank retrieval results, and even generate synthetic training data to enhance retrieval performance.
Next, the paper describes CFIR: Fast and Effective Long Text to Image, a novel approach for generating images from lengthy text descriptions. CFIR uses a two-stage process to first extract key entities and concepts, then generates the final image in a fast and efficient manner.
The paper also introduces Entity Disambiguation via Fusion Entity Decoding, which tackles the challenge of identifying unique entities in text. By fusing multiple disambiguation signals, this method achieves state-of-the-art performance on standard benchmarks.
Finally, the paper presents Leveraging Contextual Information for Effective Entity Salience Detection, a technique for determining which entities are most important or salient within a given context. This can improve downstream tasks like summarization and knowledge extraction.
Critical Analysis
The paper offers several promising directions for enhancing information retrieval systems. The authors thoughtfully address key challenges and demonstrate the effectiveness of their proposed techniques through extensive experimentation.
However, some potential limitations are worth noting. For example, the performance of LLM-Augmented Retrieval may be dependent on the specific LLM used and how it is fine-tuned. And the two-stage CFIR approach, while fast, could potentially introduce errors or inconsistencies between the extracted concepts and the final generated image.
Additionally, the entity disambiguation and salience detection methods, while state-of-the-art, may struggle with more complex or ambiguous cases. Further research could explore ways to improve robustness in these areas.
Overall, this paper makes valuable contributions to the field of information retrieval. The innovations presented here have the potential to significantly improve the accuracy, efficiency, and contextual awareness of search and content understanding systems. As with any research, ongoing work will be needed to address remaining challenges and continue advancing the state of the art.
Conclusion
This research paper introduces several novel techniques for enhancing retrieval models, including LLM-Augmented Retrieval, CFIR for fast long text to image generation, Entity Disambiguation via Fusion Entity Decoding, and Leveraging Contextual Information for Entity Salience Detection.
These approaches aim to make information retrieval systems more accurate, efficient, and contextually aware, helping users find the most relevant and useful information more easily. The technical details and experimental evaluations presented in the paper demonstrate the effectiveness of these innovations.
While the paper highlights some potential limitations, the overall contributions have significant implications for improving search, content understanding, and other information-centric applications. As the field of information retrieval continues to evolve, this work represents an important step forward in developing more powerful and user-friendly retrieval technologies.
Related Papers

Recall, Retrieve and Reason: Towards Better In-Context Relation Extraction
Guozheng Li, Peng Wang, Wenjun Ke, Yikai Guo, Ke Ji, Ziyu Shang, Jiajun Liu, Zijie Xu
0
0
Relation extraction (RE) aims to identify relations between entities mentioned in texts. Although large language models (LLMs) have demonstrated impressive in-context learning (ICL) abilities in various tasks, they still suffer from poor performances compared to most supervised fine-tuned RE methods. Utilizing ICL for RE with LLMs encounters two challenges: (1) retrieving good demonstrations from training examples, and (2) enabling LLMs exhibit strong ICL abilities in RE. On the one hand, retrieving good demonstrations is a non-trivial process in RE, which easily results in low relevance regarding entities and relations. On the other hand, ICL with an LLM achieves poor performance in RE while RE is different from language modeling in nature or the LLM is not large enough. In this work, we propose a novel recall-retrieve-reason RE framework that synergizes LLMs with retrieval corpora (training examples) to enable relevant retrieving and reliable in-context reasoning. Specifically, we distill the consistently ontological knowledge from training datasets to let LLMs generate relevant entity pairs grounded by retrieval corpora as valid queries. These entity pairs are then used to retrieve relevant training examples from the retrieval corpora as demonstrations for LLMs to conduct better ICL via instruction tuning. Extensive experiments on different LLMs and RE datasets demonstrate that our method generates relevant and valid entity pairs and boosts ICL abilities of LLMs, achieving competitive or new state-of-the-art performance on sentence-level RE compared to previous supervised fine-tuning methods and ICL-based methods.
4/30/2024
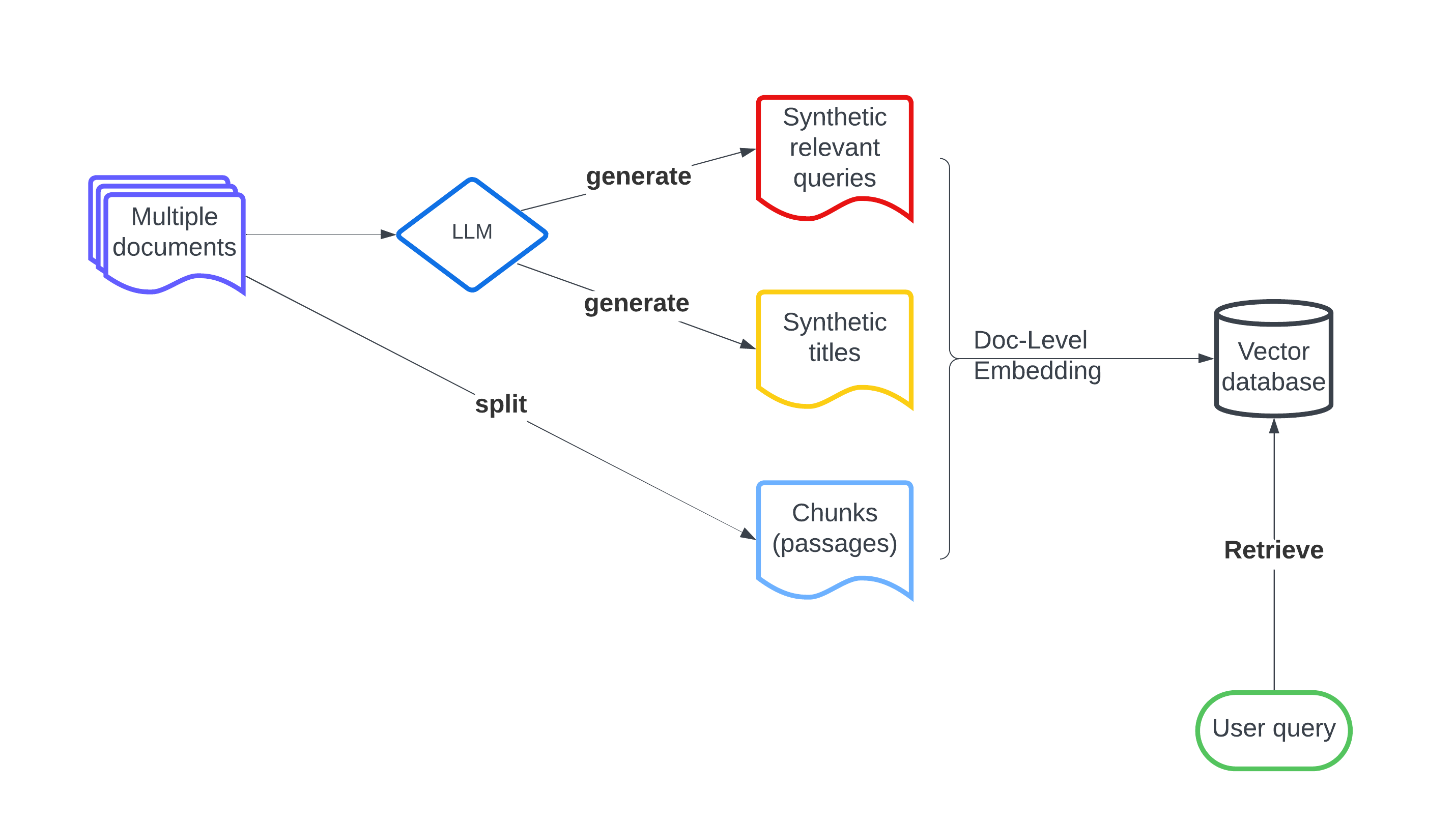
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
0
0
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
4/10/2024
🚀
Efficient Inverted Indexes for Approximate Retrieval over Learned Sparse Representations
Sebastian Bruch, Franco Maria Nardini, Cosimo Rulli, Rossano Venturini
0
0
Learned sparse representations form an attractive class of contextual embeddings for text retrieval. That is so because they are effective models of relevance and are interpretable by design. Despite their apparent compatibility with inverted indexes, however, retrieval over sparse embeddings remains challenging. That is due to the distributional differences between learned embeddings and term frequency-based lexical models of relevance such as BM25. Recognizing this challenge, a great deal of research has gone into, among other things, designing retrieval algorithms tailored to the properties of learned sparse representations, including approximate retrieval systems. In fact, this task featured prominently in the latest BigANN Challenge at NeurIPS 2023, where approximate algorithms were evaluated on a large benchmark dataset by throughput and recall. In this work, we propose a novel organization of the inverted index that enables fast yet effective approximate retrieval over learned sparse embeddings. Our approach organizes inverted lists into geometrically-cohesive blocks, each equipped with a summary vector. During query processing, we quickly determine if a block must be evaluated using the summaries. As we show experimentally, single-threaded query processing using our method, Seismic, reaches sub-millisecond per-query latency on various sparse embeddings of the MS MARCO dataset while maintaining high recall. Our results indicate that Seismic is one to two orders of magnitude faster than state-of-the-art inverted index-based solutions and further outperforms the winning (graph-based) submissions to the BigANN Challenge by a significant margin.
4/30/2024
CFIR: Fast and Effective Long-Text To Image Retrieval for Large Corpora
Zijun Long, Xuri Ge, Richard Mccreadie, Joemon Jose
0
0
Text-to-image retrieval aims to find the relevant images based on a text query, which is important in various use-cases, such as digital libraries, e-commerce, and multimedia databases. Although Multimodal Large Language Models (MLLMs) demonstrate state-of-the-art performance, they exhibit limitations in handling large-scale, diverse, and ambiguous real-world needs of retrieval, due to the computation cost and the injective embeddings they produce. This paper presents a two-stage Coarse-to-Fine Index-shared Retrieval (CFIR) framework, designed for fast and effective large-scale long-text to image retrieval. The first stage, Entity-based Ranking (ER), adapts to long-text query ambiguity by employing a multiple-queries-to-multiple-targets paradigm, facilitating candidate filtering for the next stage. The second stage, Summary-based Re-ranking (SR), refines these rankings using summarized queries. We also propose a specialized Decoupling-BEiT-3 encoder, optimized for handling ambiguous user needs and both stages, which also enhances computational efficiency through vector-based similarity inference. Evaluation on the AToMiC dataset reveals that CFIR surpasses existing MLLMs by up to 11.06% in Recall@1000, while reducing training and retrieval times by 68.75% and 99.79%, respectively. We will release our code to facilitate future research at https://github.com/longkukuhi/CFIR.
4/4/2024