Entropy-based Guidance of Deep Neural Networks for Accelerated Convergence and Improved Performance

0
🤿
Sign in to get full access
Overview
- Neural networks have dramatically improved our ability to learn from large, complex datasets across many fields.
- However, neural networks can be difficult to interpret, computationally expensive, and challenging to build and train.
- This paper presents new mathematical techniques to efficiently measure changes in entropy as neural networks process data.
- By analyzing entropy patterns, the researchers identify critical features for well-performing networks.
- They then develop entropy-based loss terms to improve the accuracy and efficiency of dense and convolutional neural networks.
- Experiments on image tasks demonstrate these entropy-based techniques lead to richer data representations, faster convergence, and higher accuracy.
Plain English Explanation
Neural networks have revolutionized how we learn from large, complex datasets across many industries, from image compression to physics modeling. However, neural networks can be challenging to work with. Their inner workings are not always easy to understand, they can be computationally intensive to train, and the process of building and training them is not straightforward.
To add more structure to this process, the researchers in this paper developed new mathematical techniques to efficiently measure changes in entropy as neural networks process data. Entropy is a measure of the uncertainty or disorder in a system. By tracking how the entropy changes as data flows through a neural network, the researchers were able to identify patterns that are critical for a well-performing network.
Using this entropy analysis, the researchers developed new "entropy-based loss terms" that can be incorporated into the training process for dense and convolutional neural networks. These loss terms encourage the networks to learn richer, more compact data representations, converge faster during training, and achieve higher accuracy, as demonstrated in experiments on image compression, classification, and segmentation tasks.
Technical Explanation
The key technical contribution of this paper is the development of new mathematical methods to efficiently measure changes in entropy as data flows through neural network architectures, including fully-connected and convolutional layers.
By tracking entropy patterns, the researchers were able to identify features that are critical for a neural network to perform well on a given task. They then incorporated this insight by developing novel entropy-based loss terms that can be added to the training objective for dense and convolutional neural networks.
Through experiments on benchmark image datasets, the researchers demonstrated that optimizing for these entropy-based losses leads to neural networks that learn richer, more compact data representations in fewer dimensions. Additionally, the networks converge in fewer training epochs and achieve higher accuracy compared to baseline models trained without the entropy-based losses.
The entropy analysis and loss terms provide a principled way to add more structure to the neural network design and training process, helping to address common challenges such as interpretability, computational cost, and the difficulty of building and training effective models.
Critical Analysis
The paper presents a thoughtful and technically rigorous approach to improving neural network performance and interpretability through the lens of information-theoretic entropy. The entropy-based loss terms developed in this work represent a novel contribution that could be valuable for a wide range of neural network applications.
However, one potential limitation is the computational overhead associated with continuously tracking and optimizing for entropy during training. While the researchers demonstrate efficiency improvements, the additional entropy calculations may still add significant time and resource requirements, especially for large-scale models and datasets.
Additionally, the paper focuses primarily on image-related tasks, and further research would be needed to evaluate the generalizability of the entropy-based techniques to other domains, such as natural language processing or reinforcement learning. Exploring the interaction between entropy-based losses and other common regularization techniques could also yield interesting insights.
Overall, this work represents an important step toward making neural networks more transparent and controllable. By incorporating principled information-theoretic measures into the training process, the researchers have provided a promising direction for enhancing the interpretability and efficiency of deep learning models.
Conclusion
This paper presents a novel approach to improving the performance and interpretability of neural networks by leveraging the concept of information-theoretic entropy. The researchers developed efficient techniques to track changes in entropy as data flows through neural network architectures, allowing them to identify critical features for well-performing models.
These insights were then used to formulate entropy-based loss terms that can be incorporated into the training process for dense and convolutional neural networks. Experiments on image tasks demonstrated that optimizing for these entropy-based losses leads to neural networks that learn richer, more compact data representations, converge faster, and achieve higher accuracy.
The ability to inject more structure and interpretability into the neural network design and training process is a significant advancement that could have broad implications across many fields that rely on deep learning. As the use of neural networks continues to expand, techniques like those presented in this paper will be crucial for unlocking the full potential of these powerful machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Entropy-based Guidance of Deep Neural Networks for Accelerated Convergence and Improved Performance
Mackenzie J. Meni, Ryan T. White, Michael Mayo, Kevin Pilkiewicz
Neural networks have dramatically increased our capacity to learn from large, high-dimensional datasets across innumerable disciplines. However, their decisions are not easily interpretable, their computational costs are high, and building and training them are not straightforward processes. To add structure to these efforts, we derive new mathematical results to efficiently measure the changes in entropy as fully-connected and convolutional neural networks process data. By measuring the change in entropy as networks process data effectively, patterns critical to a well-performing network can be visualized and identified. Entropy-based loss terms are developed to improve dense and convolutional model accuracy and efficiency by promoting the ideal entropy patterns. Experiments in image compression, image classification, and image segmentation on benchmark datasets demonstrate these losses guide neural networks to learn rich latent data representations in fewer dimensions, converge in fewer training epochs, and achieve higher accuracy.
Read more7/8/2024

0
Learning in Convolutional Neural Networks Accelerated by Transfer Entropy
Adrian Moldovan, Angel Cac{t}aron, Ru{a}zvan Andonie
Recently, there is a growing interest in applying Transfer Entropy (TE) in quantifying the effective connectivity between artificial neurons. In a feedforward network, the TE can be used to quantify the relationships between neuron output pairs located in different layers. Our focus is on how to include the TE in the learning mechanisms of a Convolutional Neural Network (CNN) architecture. We introduce a novel training mechanism for CNN architectures which integrates the TE feedback connections. Adding the TE feedback parameter accelerates the training process, as fewer epochs are needed. On the flip side, it adds computational overhead to each epoch. According to our experiments on CNN classifiers, to achieve a reasonable computational overhead--accuracy trade-off, it is efficient to consider only the inter-neural information transfer of a random subset of the neuron pairs from the last two fully connected layers. The TE acts as a smoothing factor, generating stability and becoming active only periodically, not after processing each input sample. Therefore, we can consider the TE is in our model a slowly changing meta-parameter.
Read more4/5/2024
🧠
0
Neural Entropy
Akhil Premkumar
We examine the connection between deep learning and information theory through the paradigm of diffusion models. Using well-established principles from non-equilibrium thermodynamics we can characterize the amount of information required to reverse a diffusive process. Neural networks store this information and operate in a manner reminiscent of Maxwell's demon during the generative stage. We illustrate this cycle using a novel diffusion scheme we call the entropy matching model, wherein the information conveyed to the network during training exactly corresponds to the entropy that must be negated during reversal. We demonstrate that this entropy can be used to analyze the encoding efficiency and storage capacity of the network. This conceptual picture blends elements of stochastic optimal control, thermodynamics, information theory, and optimal transport, and raises the prospect of applying diffusion models as a test bench to understand neural networks.
Read more9/9/2024
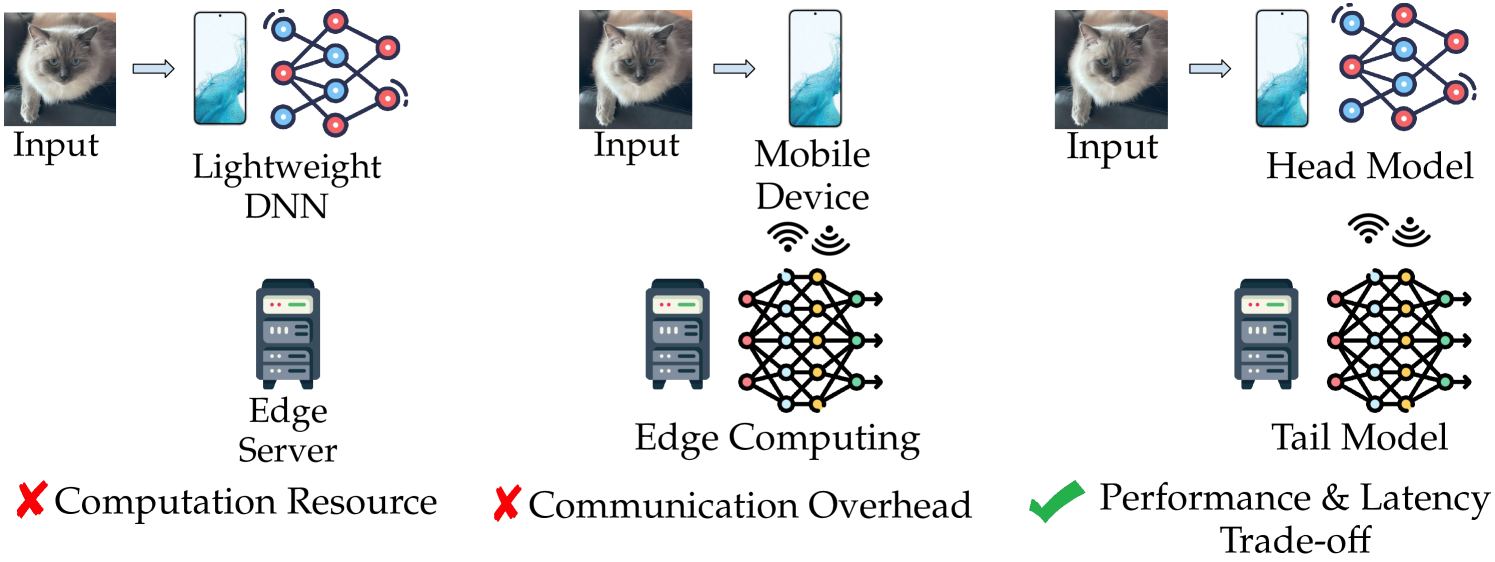
0
Resilience of Entropy Model in Distributed Neural Networks
Milin Zhang, Mohammad Abdi, Shahriar Rifat, Francesco Restuccia
Distributed deep neural networks (DNNs) have emerged as a key technique to reduce communication overhead without sacrificing performance in edge computing systems. Recently, entropy coding has been introduced to further reduce the communication overhead. The key idea is to train the distributed DNN jointly with an entropy model, which is used as side information during inference time to adaptively encode latent representations into bit streams with variable length. To the best of our knowledge, the resilience of entropy models is yet to be investigated. As such, in this paper we formulate and investigate the resilience of entropy models to intentional interference (e.g., adversarial attacks) and unintentional interference (e.g., weather changes and motion blur). Through an extensive experimental campaign with 3 different DNN architectures, 2 entropy models and 4 rate-distortion trade-off factors, we demonstrate that the entropy attacks can increase the communication overhead by up to 95%. By separating compression features in frequency and spatial domain, we propose a new defense mechanism that can reduce the transmission overhead of the attacked input by about 9% compared to unperturbed data, with only about 2% accuracy loss. Importantly, the proposed defense mechanism is a standalone approach which can be applied in conjunction with approaches such as adversarial training to further improve robustness. Code will be shared for reproducibility.
Read more7/12/2024