Learning in Convolutional Neural Networks Accelerated by Transfer Entropy

0

Sign in to get full access
Overview
- This paper explores how transfer entropy can be used to accelerate learning in convolutional neural networks (CNNs).
- Transfer entropy is a measure of information flow between different parts of a system, which the researchers apply to the layers of a CNN.
- By using transfer entropy to guide the training process, the authors claim they can improve the performance of CNNs compared to standard training techniques.
Plain English Explanation
Convolutional neural networks (CNNs) are a type of machine learning model that excel at tasks like image recognition. They work by breaking down an image into smaller pieces and processing each piece through a series of computational layers.
The key insight in this paper is that the flow of information between these layers, measured using a concept called transfer entropy, can provide valuable guidance during the training process. Transfer entropy quantifies how much information is being exchanged between different parts of a system.
The researchers argue that by monitoring the transfer entropy within a CNN during training, they can identify which layers are most important for a given task. This allows them to focus the model's training on the critical parts, rather than treating all layers equally.
The analogy would be a student preparing for an exam - by identifying the most important topics to study, they can optimize their learning process and improve their performance on the test. Similarly, the transfer entropy approach helps the CNN focus its limited training resources on the aspects that matter most.
Overall, this work suggests that incorporating transfer entropy analysis can accelerate the training of high-performing CNNs, making them more efficient and effective for real-world applications.
Technical Explanation
The core of the paper is a method for computing the transfer entropy between the layers of a convolutional neural network during the training process. Transfer entropy quantifies the amount of information flowing from one part of the system (a lower CNN layer) to another (a higher layer).
The authors derive a formula for calculating the transfer entropy based on the activations and gradients within the CNN. This allows them to monitor how information is propagating through the network as it learns a given task, such as image classification.
By analyzing the transfer entropy, the researchers can identify the most informative connections between layers. They then use this information to guide the training, for example by increasing the learning rate for the most important layers or introducing additional skip connections.
The authors evaluate their transfer entropy-based training approach on several standard CNN architectures and image recognition benchmarks. They demonstrate consistent improvements in classification accuracy compared to standard training, with the gains being most pronounced for smaller, more parameter-efficient models.
Critical Analysis
The paper provides a well-motivated and technically sound approach for leveraging transfer entropy to accelerate CNN training. The authors carefully derive the necessary computations and validate the benefits across multiple datasets and model types.
One potential limitation is the computational overhead of calculating the transfer entropy at each training step, which could slow down the overall training process. The authors claim their method is efficient, but this may be an important consideration for real-world deployment.
Additionally, the paper does not explore the broader implications of the transfer entropy analysis. It would be valuable to understand how the identified critical connections relate to the underlying task and network architecture. This could yield insights into the inductive biases and generalization properties of CNNs.
Further research could also investigate whether the transfer entropy approach generalizes beyond image recognition, to other domains where CNNs are applied, such as natural language processing or reinforcement learning. Exploring the synergies between transfer entropy and other training techniques, like knowledge distillation or meta-learning, could also be fruitful avenues for future work.
Conclusion
This paper presents a novel way to accelerate the training of convolutional neural networks by leveraging transfer entropy, a measure of information flow between layers. The authors demonstrate consistent improvements in classification accuracy across multiple benchmark tasks, suggesting that the transfer entropy approach can make CNNs more efficient and effective.
While there are some computational considerations, the transfer entropy analysis provides valuable insights into the inner workings of CNNs and how to focus the training process on the most critical connections. As the field of deep learning continues to advance, techniques like this that can improve the sample efficiency and performance of neural networks will become increasingly important for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning in Convolutional Neural Networks Accelerated by Transfer Entropy
Adrian Moldovan, Angel Cac{t}aron, Ru{a}zvan Andonie
Recently, there is a growing interest in applying Transfer Entropy (TE) in quantifying the effective connectivity between artificial neurons. In a feedforward network, the TE can be used to quantify the relationships between neuron output pairs located in different layers. Our focus is on how to include the TE in the learning mechanisms of a Convolutional Neural Network (CNN) architecture. We introduce a novel training mechanism for CNN architectures which integrates the TE feedback connections. Adding the TE feedback parameter accelerates the training process, as fewer epochs are needed. On the flip side, it adds computational overhead to each epoch. According to our experiments on CNN classifiers, to achieve a reasonable computational overhead--accuracy trade-off, it is efficient to consider only the inter-neural information transfer of a random subset of the neuron pairs from the last two fully connected layers. The TE acts as a smoothing factor, generating stability and becoming active only periodically, not after processing each input sample. Therefore, we can consider the TE is in our model a slowly changing meta-parameter.
Read more4/5/2024
🤿
0
Entropy-based Guidance of Deep Neural Networks for Accelerated Convergence and Improved Performance
Mackenzie J. Meni, Ryan T. White, Michael Mayo, Kevin Pilkiewicz
Neural networks have dramatically increased our capacity to learn from large, high-dimensional datasets across innumerable disciplines. However, their decisions are not easily interpretable, their computational costs are high, and building and training them are not straightforward processes. To add structure to these efforts, we derive new mathematical results to efficiently measure the changes in entropy as fully-connected and convolutional neural networks process data. By measuring the change in entropy as networks process data effectively, patterns critical to a well-performing network can be visualized and identified. Entropy-based loss terms are developed to improve dense and convolutional model accuracy and efficiency by promoting the ideal entropy patterns. Experiments in image compression, image classification, and image segmentation on benchmark datasets demonstrate these losses guide neural networks to learn rich latent data representations in fewer dimensions, converge in fewer training epochs, and achieve higher accuracy.
Read more7/8/2024

0
Information Plane Analysis Visualization in Deep Learning via Transfer Entropy
Adrian Moldovan, Angel Cataron, Razvan Andonie
In a feedforward network, Transfer Entropy (TE) can be used to measure the influence that one layer has on another by quantifying the information transfer between them during training. According to the Information Bottleneck principle, a neural model's internal representation should compress the input data as much as possible while still retaining sufficient information about the output. Information Plane analysis is a visualization technique used to understand the trade-off between compression and information preservation in the context of the Information Bottleneck method by plotting the amount of information in the input data against the compressed representation. The claim that there is a causal link between information-theoretic compression and generalization, measured by mutual information, is plausible, but results from different studies are conflicting. In contrast to mutual information, TE can capture temporal relationships between variables. To explore such links, in our novel approach we use TE to quantify information transfer between neural layers and perform Information Plane analysis. We obtained encouraging experimental results, opening the possibility for further investigations.
Read more4/3/2024
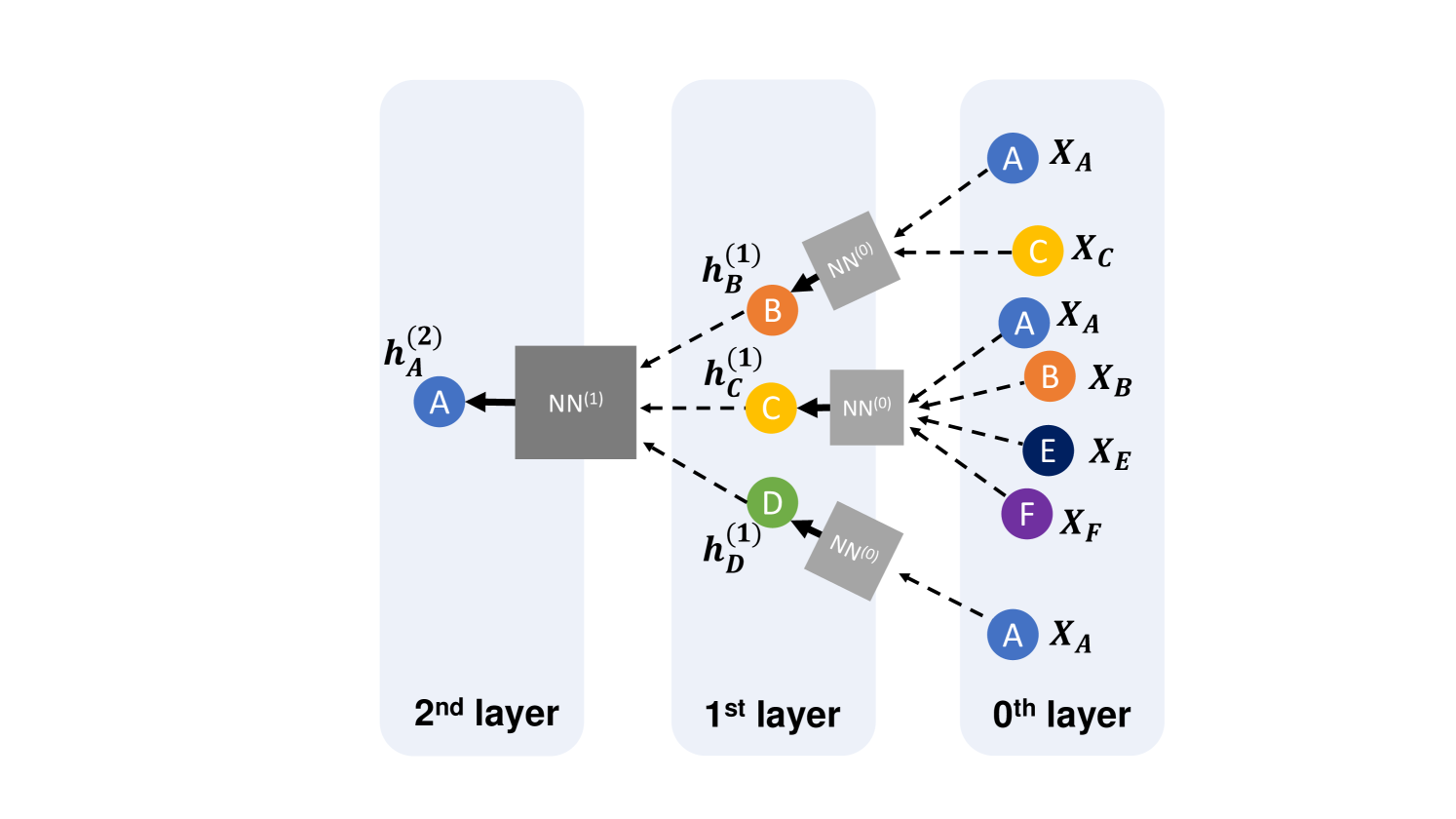
0
Transfer Entropy in Graph Convolutional Neural Networks
Adrian Moldovan, Angel Cac{t}aron, Ru{a}zvan Andonie
Graph Convolutional Networks (GCN) are Graph Neural Networks where the convolutions are applied over a graph. In contrast to Convolutional Neural Networks, GCN's are designed to perform inference on graphs, where the number of nodes can vary, and the nodes are unordered. In this study, we address two important challenges related to GCNs: i) oversmoothing; and ii) the utilization of node relational properties (i.e., heterophily and homophily). Oversmoothing is the degradation of the discriminative capacity of nodes as a result of repeated aggregations. Heterophily is the tendency for nodes of different classes to connect, whereas homophily is the tendency of similar nodes to connect. We propose a new strategy for addressing these challenges in GCNs based on Transfer Entropy (TE), which measures of the amount of directed transfer of information between two time varying nodes. Our findings indicate that using node heterophily and degree information as a node selection mechanism, along with feature-based TE calculations, enhances accuracy across various GCN models. Our model can be easily modified to improve classification accuracy of a GCN model. As a trade off, this performance boost comes with a significant computational overhead when the TE is computed for many graph nodes.
Read more6/12/2024