The Simpler The Better: An Entropy-Based Importance Metric To Reduce Neural Networks' Depth

0

Sign in to get full access
Overview
- This paper proposes a novel entropy-based importance metric to reduce the depth of neural networks without significantly compromising their performance.
- The key idea is to identify and remove less important neurons from the network, effectively reducing its complexity while maintaining high accuracy.
- The authors demonstrate the effectiveness of their approach on various deep learning tasks and model architectures, showing that simpler models can often achieve comparable or even better results than their deeper counterparts.
Plain English Explanation
The researchers have developed a new way to make neural networks simpler and more efficient. Neural networks are a type of machine learning model that can be used for a variety of tasks, like image recognition or language processing. However, these models can become very complex, with many layers and neurons, which can make them slow, inefficient, and difficult to understand.
The researchers' approach focuses on identifying the less important parts of the neural network and removing them. This is done by calculating an "importance score" for each neuron, based on the amount of information it carries. Neurons with a low importance score are then removed, effectively simplifying the network without significantly affecting its performance.
By making the neural networks simpler, the researchers hope to make them faster, more efficient, and easier to understand. This could be particularly useful in applications where computational resources are limited, such as on mobile devices or in embedded systems.
The researchers have tested their approach on a range of deep learning tasks and model architectures, and have found that the simpler models they create can often match or even outperform the original, more complex models. This suggests that, in many cases, the extra complexity of deep neural networks may not be necessary, and that simpler is often better.
Technical Explanation
The paper introduces an entropy-based importance metric to identify and remove less important neurons from deep neural networks. The key idea is to compute the Shannon entropy of each neuron's activations, which serves as a proxy for the amount of information the neuron carries.
Neurons with low entropy, i.e., those that exhibit little variation in their outputs, are considered less important and can be safely removed without significantly impacting the model's performance. The authors refer to this process as "entropic pruning" and demonstrate its effectiveness on various deep learning tasks, including image classification, object detection, and language modeling.
The proposed importance metric is compared to other commonly used pruning techniques, such as weighted loss transfer learning and OccamNets, and is shown to outperform these methods in terms of both model compression and final task performance.
The authors also explore the relationship between network depth and the entropy-based importance of neurons, finding that deeper layers tend to have neurons with lower entropy, suggesting that simpler models may often be sufficient for many tasks.
Critical Analysis
The paper presents a compelling approach to reducing the complexity of neural networks while maintaining their performance. The entropy-based importance metric is a well-grounded and intuitive way to identify and remove less critical neurons, and the authors demonstrate its effectiveness across a range of deep learning tasks.
One potential limitation of the approach is that it may not capture all aspects of a neuron's importance, as entropy alone may not fully capture the complex interactions and dependencies within a neural network. Additionally, the authors do not explore the impact of their pruning method on the generalization capabilities of the models, which could be an important consideration for real-world applications.
Further research could investigate the integration of the entropy-based pruning method with other network compression techniques, such as lightweight measures of classification difficulty or generalized entropic sparsification, to achieve even greater model simplification without sacrificing performance.
Overall, the paper presents a valuable contribution to the ongoing efforts to make deep learning models more efficient and easier to deploy, particularly in resource-constrained environments.
Conclusion
This paper introduces an entropy-based importance metric that can effectively reduce the depth and complexity of neural networks without significantly compromising their performance. By identifying and removing less important neurons, the authors demonstrate that simpler models can often achieve comparable or even better results than their deeper counterparts.
The proposed approach has the potential to make deep learning models more efficient, faster, and easier to understand, which could be particularly useful in applications where computational resources are limited, such as on mobile devices or in embedded systems. The results suggest that, in many cases, the extra complexity of deep neural networks may not be necessary, and that simpler is often better.
Overall, this research represents an important step towards developing more efficient and interpretable deep learning models, with broader implications for the field of artificial intelligence and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Simpler The Better: An Entropy-Based Importance Metric To Reduce Neural Networks' Depth
Victor Qu'etu, Zhu Liao, Enzo Tartaglione
While deep neural networks are highly effective at solving complex tasks, large pre-trained models are commonly employed even to solve consistently simpler downstream tasks, which do not necessarily require a large model's complexity. Motivated by the awareness of the ever-growing AI environmental impact, we propose an efficiency strategy that leverages prior knowledge transferred by large models. Simple but effective, we propose a method relying on an Entropy-bASed Importance mEtRic (EASIER) to reduce the depth of over-parametrized deep neural networks, which alleviates their computational burden. We assess the effectiveness of our method on traditional image classification setups. Our code is available at https://github.com/VGCQ/EASIER.
Read more6/6/2024
🤿
0
Entropy-based Guidance of Deep Neural Networks for Accelerated Convergence and Improved Performance
Mackenzie J. Meni, Ryan T. White, Michael Mayo, Kevin Pilkiewicz
Neural networks have dramatically increased our capacity to learn from large, high-dimensional datasets across innumerable disciplines. However, their decisions are not easily interpretable, their computational costs are high, and building and training them are not straightforward processes. To add structure to these efforts, we derive new mathematical results to efficiently measure the changes in entropy as fully-connected and convolutional neural networks process data. By measuring the change in entropy as networks process data effectively, patterns critical to a well-performing network can be visualized and identified. Entropy-based loss terms are developed to improve dense and convolutional model accuracy and efficiency by promoting the ideal entropy patterns. Experiments in image compression, image classification, and image segmentation on benchmark datasets demonstrate these losses guide neural networks to learn rich latent data representations in fewer dimensions, converge in fewer training epochs, and achieve higher accuracy.
Read more7/8/2024
🧠
0
NEPENTHE: Entropy-Based Pruning as a Neural Network Depth's Reducer
Zhu Liao, Victor Qu'etu, Van-Tam Nguyen, Enzo Tartaglione
While deep neural networks are highly effective at solving complex tasks, their computational demands can hinder their usefulness in real-time applications and with limited-resources systems. Besides, for many tasks it is known that these models are over-parametrized: neoteric works have broadly focused on reducing the width of these networks, rather than their depth. In this paper, we aim to reduce the depth of over-parametrized deep neural networks: we propose an eNtropy-basEd Pruning as a nEural Network depTH's rEducer (NEPENTHE) to alleviate deep neural networks' computational burden. Based on our theoretical finding, NEPENTHE focuses on un-structurally pruning connections in layers with low entropy to remove them entirely. We validate our approach on popular architectures such as MobileNet and Swin-T, showing that when encountering an over-parametrization regime, it can effectively linearize some layers (hence reducing the model's depth) with little to no performance loss. The code will be publicly available upon acceptance of the article.
Read more4/29/2024
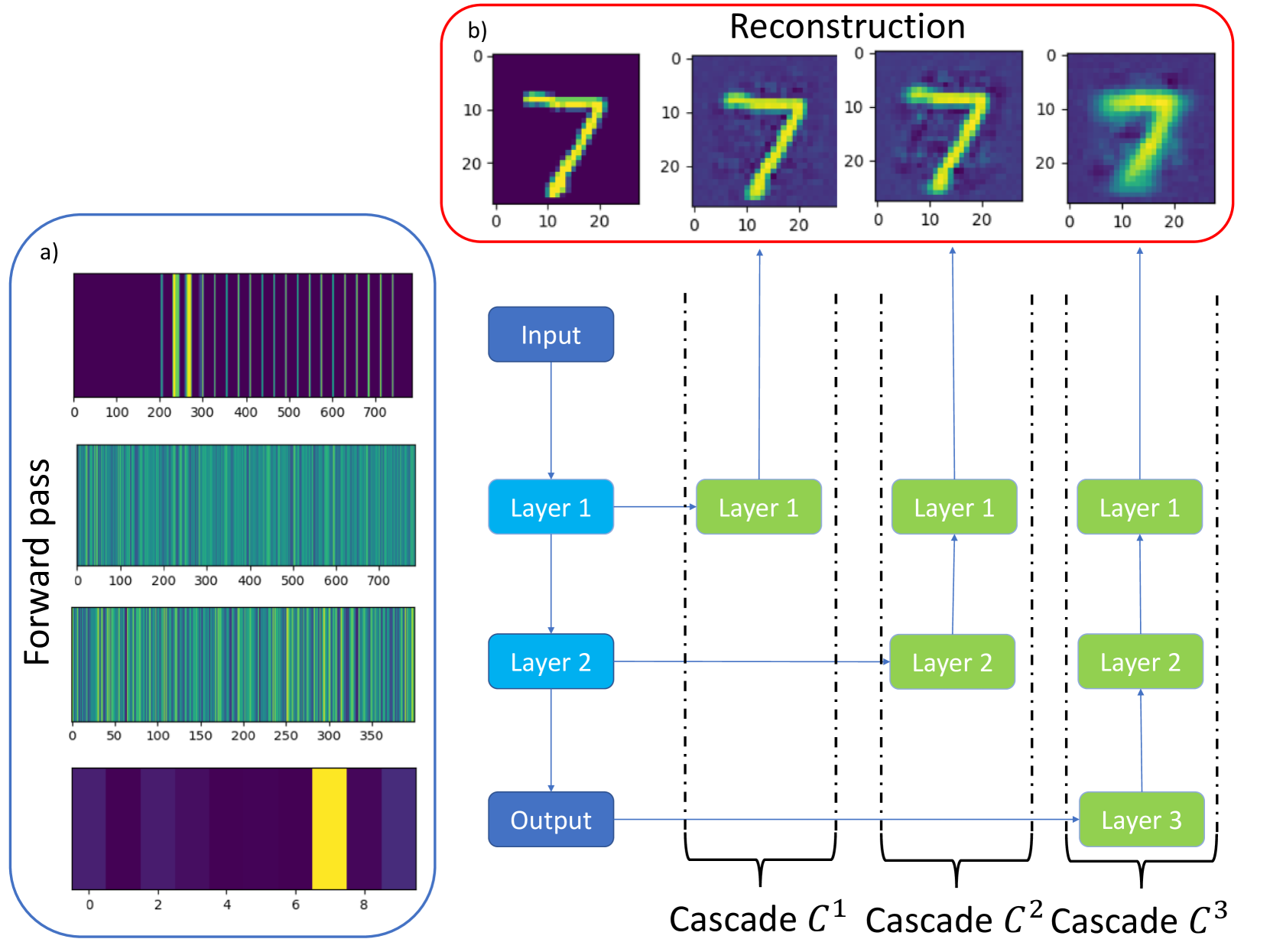
0
Opening the Black Box: predicting the trainability of deep neural networks with reconstruction entropy
Yanick Thurn, Ro Jefferson, Johanna Erdmenger
An important challenge in machine learning is to predict the initial conditions under which a given neural network will be trainable. We present a method for predicting the trainable regime in parameter space for deep feedforward neural networks, based on reconstructing the input from subsequent activation layers via a cascade of single-layer auxiliary networks. For both the MNIST and CIFAR10 datasets, we show that a single epoch of training of the shallow cascade networks is sufficient to predict the trainability of the deep feedforward network, thereby providing a significant reduction in overall training time. We achieve this by computing the relative entropy between reconstructed images and the original inputs, and show that this probe of information loss is sensitive to the phase behaviour of the network. Moreover, our approach illustrates the network's decision making process by displaying the changes performed on the input data at each layer. Our results provide a concrete link between the flow of information and the trainability of deep neural networks, further explaining the role of criticality in these systems.
Read more8/12/2024