Equation Discovery with Bayesian Spike-and-Slab Priors and Efficient Kernels

0

Sign in to get full access
Overview
- This research paper presents a Bayesian approach for discovering equations from data using spike-and-slab priors and efficient kernel methods.
- The key ideas include using a Bayesian framework to automatically identify the relevant terms in an equation, and leveraging kernel techniques to efficiently handle complex, nonlinear relationships.
- The proposed method is demonstrated on several benchmark problems and showcases improved performance compared to existing techniques.
Plain English Explanation
The researchers developed a new way to uncover mathematical equations that describe patterns in data. Often, scientists and engineers need to find the equations that best capture the relationships between different measurements or observations. This can be a challenging task, especially when the relationships are complex and nonlinear.
The researchers' approach uses Bayesian statistics, which is a powerful mathematical framework for making inferences from data. Specifically, they employ a "spike-and-slab" prior, which helps the algorithm automatically identify the important terms that should be included in the final equation. This is like being able to zoom in on the key factors driving the patterns in the data, while ignoring less relevant details.
Additionally, the researchers leverage efficient kernel methods, which are a way of handling complex, nonlinear relationships in the data. Kernels allow the algorithm to capture intricate patterns without getting bogged down in the mathematical complexity.
By combining these Bayesian and kernel techniques, the researchers demonstrate that their approach can uncover accurate equations from data more effectively than previous methods. This could be useful in a wide range of applications, from scientific discovery to engineering design.
Technical Explanation
The paper presents a Bayesian framework for equation discovery that utilizes a spike-and-slab prior and efficient kernel methods. The spike-and-slab prior helps the model identify the relevant terms to include in the final equation, while the kernel approach allows the model to capture complex, nonlinear relationships in the data.
The proposed model is formulated as a Bayesian regression problem, where the goal is to discover an equation that best fits the observed data. The spike-and-slab prior places a mixture of a narrow "spike" and a wide "slab" distribution on each regression coefficient, allowing the model to automatically determine which terms should be included in the final equation.
To efficiently handle the potentially high-dimensional feature space, the researchers employ kernel-based learning methods. This allows the model to capture nonlinear relationships without explicitly computing the feature representations, which can be computationally expensive.
The authors demonstrate the effectiveness of their approach on several benchmark problems, showing that it outperforms existing equation discovery methods in terms of predictive accuracy and the ability to uncover the true underlying equations.
Critical Analysis
The paper presents a promising approach for equation discovery, but there are a few potential limitations and areas for further research:
-
The authors focus on polynomial equations, but many real-world systems may exhibit more complex functional forms. Extending the method to handle a wider range of equation types could broaden its applicability.
-
The paper does not discuss the computational scalability of the proposed approach, which is an important consideration for large-scale problems. Investigating efficient optimization techniques could help improve the algorithm's performance on very high-dimensional data.
-
The authors mention that their method assumes the underlying equation is sparse, with only a few relevant terms. In practice, this assumption may not always hold, and the algorithm's performance may degrade in the presence of dense, complex equations.
-
While the paper demonstrates the method's effectiveness on benchmark problems, testing it on real-world datasets from diverse domains would help further validate its practical utility and identify any potential limitations.
Conclusion
This research paper presents a novel Bayesian approach for equation discovery that combines spike-and-slab priors and efficient kernel methods. The key advantages of this approach are its ability to automatically identify the relevant terms in an equation and its capacity to handle complex, nonlinear relationships in the data.
The demonstrated performance improvements over existing techniques suggest that this method could be a valuable tool for scientific and engineering applications where the goal is to uncover the underlying mathematical relationships governing a system. Further research on scalability, handling of dense equations, and real-world validation could help expand the method's reach and impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Equation Discovery with Bayesian Spike-and-Slab Priors and Efficient Kernels
Da Long, Wei W. Xing, Aditi S. Krishnapriyan, Robert M. Kirby, Shandian Zhe, Michael W. Mahoney
Discovering governing equations from data is important to many scientific and engineering applications. Despite promising successes, existing methods are still challenged by data sparsity and noise issues, both of which are ubiquitous in practice. Moreover, state-of-the-art methods lack uncertainty quantification and/or are costly in training. To overcome these limitations, we propose a novel equation discovery method based on Kernel learning and BAyesian Spike-and-Slab priors (KBASS). We use kernel regression to estimate the target function, which is flexible, expressive, and more robust to data sparsity and noises. We combine it with a Bayesian spike-and-slab prior -- an ideal Bayesian sparse distribution -- for effective operator selection and uncertainty quantification. We develop an expectation-propagation expectation-maximization (EP-EM) algorithm for efficient posterior inference and function estimation. To overcome the computational challenge of kernel regression, we place the function values on a mesh and induce a Kronecker product construction, and we use tensor algebra to enable efficient computation and optimization. We show the advantages of KBASS on a list of benchmark ODE and PDE discovery tasks.
Read more4/23/2024
0
Data-Driven Optimal Feedback Laws via Kernel Mean Embeddings
Petar Bevanda, Nicolas Hoischen, Stefan Sosnowski, Sandra Hirche, Boris Houska
This paper proposes a fully data-driven approach for optimal control of nonlinear control-affine systems represented by a stochastic diffusion. The focus is on the scenario where both the nonlinear dynamics and stage cost functions are unknown, while only control penalty function and constraints are provided. Leveraging the theory of reproducing kernel Hilbert spaces, we introduce novel kernel mean embeddings (KMEs) to identify the Markov transition operators associated with controlled diffusion processes. The KME learning approach seamlessly integrates with modern convex operator-theoretic Hamilton-Jacobi-Bellman recursions. Thus, unlike traditional dynamic programming methods, our approach exploits the ``kernel trick'' to break the curse of dimensionality. We demonstrate the effectiveness of our method through numerical examples, highlighting its ability to solve a large class of nonlinear optimal control problems.
Read more7/24/2024
0
Physics-informed machine learning as a kernel method
Nathan Doum`eche (LPSM), Francis Bach (DI-ENS, SIERRA), G'erard Biau (LPSM), Claire Boyer (IUF, LPSM)
Physics-informed machine learning combines the expressiveness of data-based approaches with the interpretability of physical models. In this context, we consider a general regression problem where the empirical risk is regularized by a partial differential equation that quantifies the physical inconsistency. We prove that for linear differential priors, the problem can be formulated as a kernel regression task. Taking advantage of kernel theory, we derive convergence rates for the minimizer of the regularized risk and show that it converges at least at the Sobolev minimax rate. However, faster rates can be achieved, depending on the physical error. This principle is illustrated with a one-dimensional example, supporting the claim that regularizing the empirical risk with physical information can be beneficial to the statistical performance of estimators.
Read more6/21/2024
0
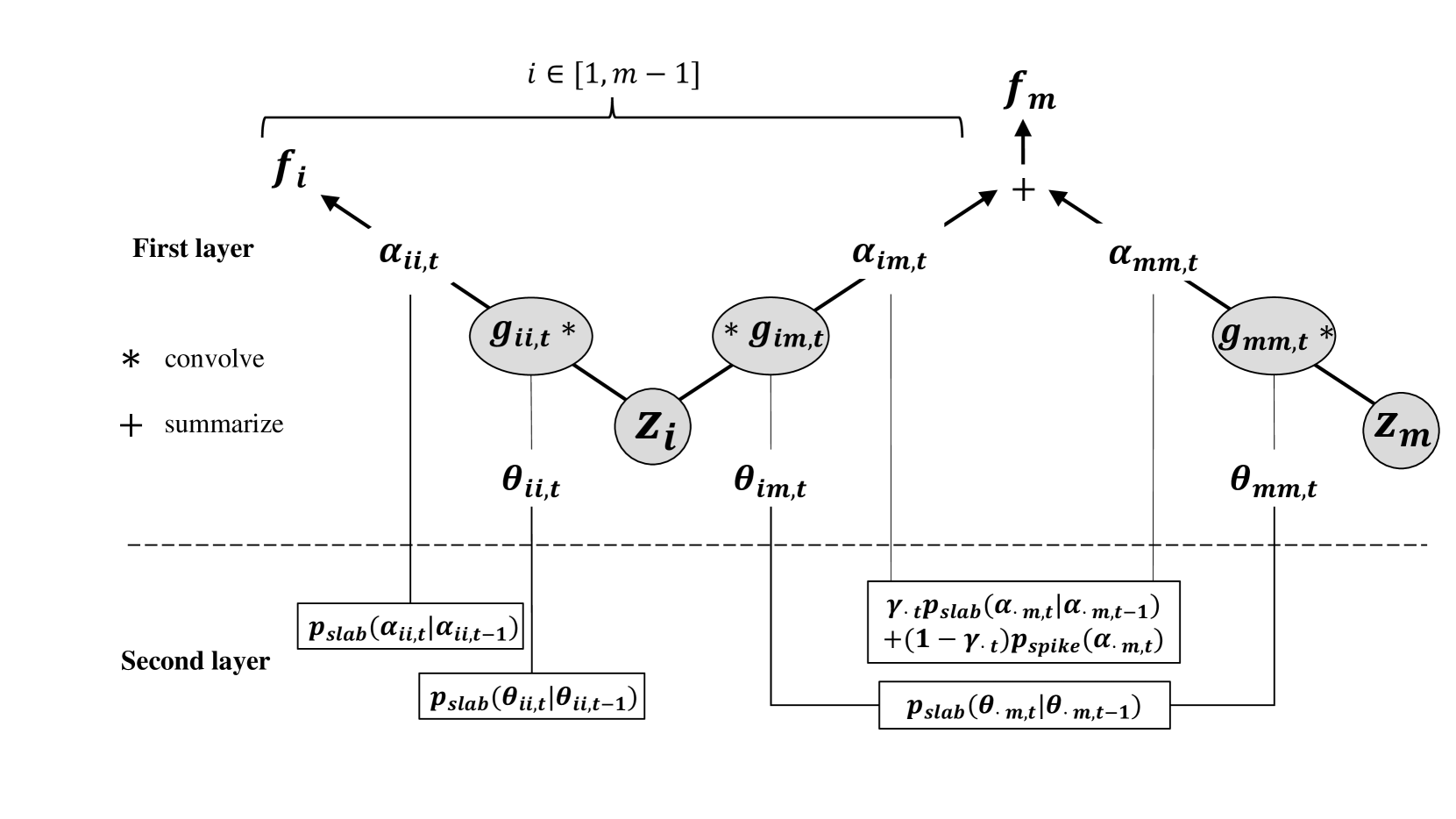
Non-stationary and Sparsely-correlated Multi-output Gaussian Process with Spike-and-Slab Prior
Wang Xinming, Li Yongxiang, Yue Xiaowei, Wu Jianguo
Multi-output Gaussian process (MGP) is commonly used as a transfer learning method to leverage information among multiple outputs. A key advantage of MGP is providing uncertainty quantification for prediction, which is highly important for subsequent decision-making tasks. However, traditional MGP may not be sufficiently flexible to handle multivariate data with dynamic characteristics, particularly when dealing with complex temporal correlations. Additionally, since some outputs may lack correlation, transferring information among them may lead to negative transfer. To address these issues, this study proposes a non-stationary MGP model that can capture both the dynamic and sparse correlation among outputs. Specifically, the covariance functions of MGP are constructed using convolutions of time-varying kernel functions. Then a dynamic spike-and-slab prior is placed on correlation parameters to automatically decide which sources are informative to the target output in the training process. An expectation-maximization (EM) algorithm is proposed for efficient model fitting. Both numerical studies and a real case demonstrate its efficacy in capturing dynamic and sparse correlation structure and mitigating negative transfer for high-dimensional time-series data. Finally, a mountain-car reinforcement learning case highlights its potential application in decision making problems.
Read more9/6/2024