Kernel-based learning with guarantees for multi-agent applications
2404.09708
0
0

Abstract
This paper addresses a kernel-based learning problem for a network of agents locally observing a latent multidimensional, nonlinear phenomenon in a noisy environment. We propose a learning algorithm that requires only mild a priori knowledge about the phenomenon under investigation and delivers a model with corresponding non-asymptotic high probability error bounds. Both non-asymptotic analysis of the method and numerical simulation results are presented and discussed in the paper.
Create account to get full access
Overview
- Presents a kernel-based learning framework for multi-agent applications with guaranteed performance
- Focuses on the challenge of learning in a multi-agent setting where agents have limited communication and information
- Proposes algorithms with theoretical guarantees on convergence, feasibility, and optimality
Plain English Explanation
This research paper introduces a kernel-based learning framework for multi-agent applications. In many real-world scenarios, such as multi-agent reinforcement learning or group decision-making, multiple agents need to work together to achieve a common goal. However, the agents may have limited communication and information, making it challenging to coordinate their actions.
The proposed framework addresses this challenge by using kernel methods, a type of machine learning technique that can learn patterns from data without making strong assumptions about the underlying relationships. The key idea is to enable the agents to learn a shared representation of the problem, even with limited communication, and then use this representation to make decisions that benefit the group as a whole.
The paper provides theoretical guarantees on the performance of the proposed algorithms, ensuring that they will converge to a feasible and optimal solution under certain conditions. This is an important aspect, as it gives users confidence in the reliability and predictability of the system, especially in critical multi-agent applications.
Technical Explanation
The paper first introduces the network setup, where multiple agents are connected through a communication graph and must work together to optimize a shared objective function. The agents have access to local information, but their communication is limited to their neighbors in the graph.
The authors then propose a kernel-based learning framework to address this problem. The key steps are:
- Each agent learns a local kernel function that captures the relevant features of the problem from its limited observations.
- The agents then share their local kernel functions with their neighbors and aggregate them to obtain a shared kernel representation.
- Using this shared representation, the agents can coordinate their actions to optimize the overall objective.
The paper provides theoretical analysis to show that the proposed algorithms converge to a feasible and optimal solution under certain assumptions on the communication graph and the individual agents' objectives.
Critical Analysis
The paper presents a well-designed framework that addresses an important challenge in multi-agent systems. The theoretical guarantees on the performance of the proposed algorithms are a particular strength, as they provide users with confidence in the reliability of the system.
However, the paper also acknowledges several limitations and areas for future research. For example, the analysis assumes that the agents have access to accurate local information, which may not always be the case in real-world applications. Additionally, the paper does not consider scenarios where the agents' objectives may be adversarial or where some agents may be malicious.
Further research could explore relaxing these assumptions and developing more robust algorithms that can handle more complex and realistic multi-agent scenarios. Additionally, it would be valuable to see empirical evaluations of the proposed framework on real-world multi-agent applications to assess its practical performance and identify any additional challenges that may arise.
Conclusion
This research paper presents a promising kernel-based learning framework for multi-agent applications, with theoretical guarantees on convergence, feasibility, and optimality. By enabling agents to learn a shared representation of the problem despite limited communication, the framework addresses an important challenge in coordinating the actions of multiple autonomous agents.
While the paper acknowledges some limitations and areas for future work, the core ideas and the proven performance guarantees make this a significant contribution to the field of multi-agent systems. As the use of autonomous agents becomes more prevalent in various domains, this type of principled approach to multi-agent coordination will be increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Open Problem: Order Optimal Regret Bounds for Kernel-Based Reinforcement Learning
Sattar Vakili
0
0
Reinforcement Learning (RL) has shown great empirical success in various application domains. The theoretical aspects of the problem have been extensively studied over past decades, particularly under tabular and linear Markov Decision Process structures. Recently, non-linear function approximation using kernel-based prediction has gained traction. This approach is particularly interesting as it naturally extends the linear structure, and helps explain the behavior of neural-network-based models at their infinite width limit. The analytical results however do not adequately address the performance guarantees for this case. We will highlight this open problem, overview existing partial results, and discuss related challenges.
6/24/2024
🔗
Robust Online Learning over Networks
Nicola Bastianello, Diego Deplano, Mauro Franceschelli, Karl H. Johansson
0
0
The recent deployment of multi-agent networks has enabled the distributed solution of learning problems, where agents cooperate to train a global model without sharing their local, private data. This work specifically targets some prevalent challenges inherent to distributed learning: (i) online training, i.e., the local data change over time; (ii) asynchronous agent computations; (iii) unreliable and limited communications; and (iv) inexact local computations. To tackle these challenges, we apply the Distributed Operator Theoretical (DOT) version of the Alternating Direction Method of Multipliers (ADMM), which we call DOT-ADMM. We prove that if the DOT-ADMM operator is metric subregular, then it converges with a linear rate for a large class of (not necessarily strongly) convex learning problems toward a bounded neighborhood of the optimal time-varying solution, and characterize how such neighborhood depends on (i)-(iv). We first derive an easy-to-verify condition for ensuring the metric subregularity of an operator, followed by tutorial examples on linear and logistic regression problems. We corroborate the theoretical analysis with numerical simulations comparing DOT-ADMM with other state-of-the-art algorithms, showing that only the proposed algorithm exhibits robustness to (i)-(iv).
5/20/2024
🚀
Learning-Based Optimal Control with Performance Guarantees for Unknown Systems with Latent States
Robert Lefringhausen, Supitsana Srithasan, Armin Lederer, Sandra Hirche
0
0
As control engineering methods are applied to increasingly complex systems, data-driven approaches for system identification appear as a promising alternative to physics-based modeling. While the Bayesian approaches prevalent for safety-critical applications usually rely on the availability of state measurements, the states of a complex system are often not directly measurable. It may then be necessary to jointly estimate the dynamics and the latent state, making the quantification of uncertainties and the design of controllers with formal performance guarantees considerably more challenging. This paper proposes a novel method for the computation of an optimal input trajectory for unknown nonlinear systems with latent states based on a combination of particle Markov chain Monte Carlo methods and scenario theory. Probabilistic performance guarantees are derived for the resulting input trajectory, and an approach to validate the performance of arbitrary control laws is presented. The effectiveness of the proposed method is demonstrated in a numerical simulation.
4/17/2024
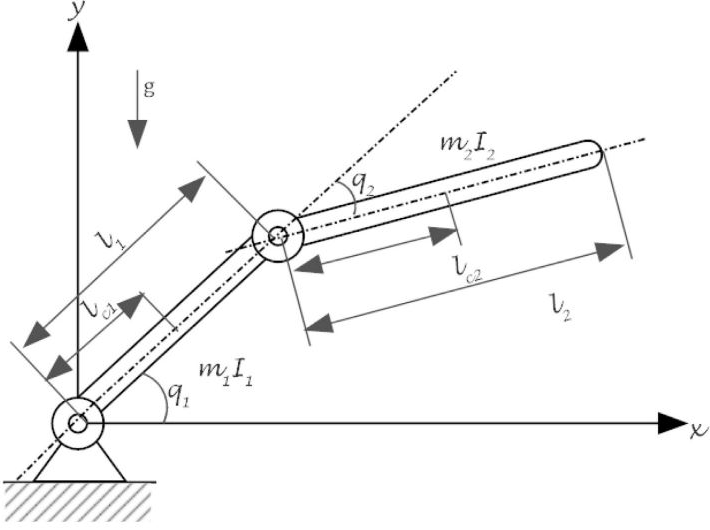
Composite Distributed Learning and Synchronization of Nonlinear Multi-Agent Systems with Complete Uncertain Dynamics
Emadodin Jandaghi, Dalton L. Stein, Adam Hoburg, Paolo Stegagno, Mingxi Zhou, Chengzhi Yuan
0
0
This paper addresses the problem of composite synchronization and learning control in a network of multi-agent robotic manipulator systems with heterogeneous nonlinear uncertainties under a leader-follower framework. A novel two-layer distributed adaptive learning control strategy is introduced, comprising a first-layer distributed cooperative estimator and a second-layer decentralized deterministic learning controller. The first layer is to facilitate each robotic agent's estimation of the leader's information. The second layer is responsible for both controlling individual robot agents to track desired reference trajectories and accurately identifying/learning their nonlinear uncertain dynamics. The proposed distributed learning control scheme represents an advancement in the existing literature due to its ability to manage robotic agents with completely uncertain dynamics including uncertain mass matrices. This allows the robotic control to be environment-independent which can be used in various settings, from underwater to space where identifying system dynamics parameters is challenging. The stability and parameter convergence of the closed-loop system are rigorously analyzed using the Lyapunov method. Numerical simulations validate the effectiveness of the proposed scheme.
5/10/2024