Erasing the Bias: Fine-Tuning Foundation Models for Semi-Supervised Learning
2405.11756
0
0

Abstract
Semi-supervised learning (SSL) has witnessed remarkable progress, resulting in the emergence of numerous method variations. However, practitioners often encounter challenges when attempting to deploy these methods due to their subpar performance. In this paper, we present a novel SSL approach named FineSSL that significantly addresses this limitation by adapting pre-trained foundation models. We identify the aggregated biases and cognitive deviation problems inherent in foundation models, and propose a simple yet effective solution by imposing balanced margin softmax and decoupled label smoothing. Through extensive experiments, we demonstrate that FineSSL sets a new state of the art for SSL on multiple benchmark datasets, reduces the training cost by over six times, and can seamlessly integrate various fine-tuning and modern SSL algorithms. The source code is available at https://github.com/Gank0078/FineSSL.
Create account to get full access
Overview
- This paper explores methods for fine-tuning large foundation models to improve their performance on semi-supervised learning tasks.
- The authors propose a framework called "Erasing the Bias" that aims to reduce the inherent biases in foundation models and enhance their generalization to small datasets.
- The technique involves carefully designed fine-tuning procedures and architectural modifications to better leverage unlabeled data during training.
Plain English Explanation
Large machine learning models, known as "foundation models," have become increasingly powerful at tackling a wide range of tasks. However, these models can sometimes exhibit biases and struggle to generalize well to smaller datasets, which can limit their real-world applicability.
The Erasing the Bias framework presented in this paper aims to address these challenges. The key idea is to fine-tune the foundation model in a way that reduces its inherent biases and allows it to learn more effectively from a combination of labeled and unlabeled data.
By carefully modifying the model architecture and the training process, the researchers show that the fine-tuned model can achieve better performance on semi-supervised learning tasks, where only a small portion of the data is labeled. This is particularly relevant for many real-world applications, where obtaining labeled data can be costly or time-consuming.
The authors draw inspiration from techniques like self-supervised learning and reinforcement learning to design their approach, aiming to leverage the power of large foundation models while overcoming their limitations.
Technical Explanation
The paper introduces a framework called "Erasing the Bias" for fine-tuning large foundation models to improve their performance on semi-supervised learning tasks. The key components of the framework include:
-
Architectural Modifications: The authors propose modifying the model architecture to better align with the semi-supervised learning setting. This includes introducing additional layers or components that can effectively utilize unlabeled data during the fine-tuning process.
-
Fine-Tuning Procedures: The researchers explore different fine-tuning strategies, such as pretraining on a large dataset, freezing specific layers, and gradually unfreezing them during the fine-tuning stage. These techniques aim to strike a balance between preserving the general knowledge learned by the foundation model and adapting it to the target task.
-
Regularization and Consistency Constraints: The authors incorporate regularization techniques and consistency constraints to encourage the model to learn robust features that generalize well to small datasets. This includes employing data augmentation, consistency loss functions, and other regularization methods.
Through extensive experiments on various benchmark datasets, the authors demonstrate that the "Erasing the Bias" framework can significantly improve the performance of fine-tuned foundation models on semi-supervised learning tasks, outperforming traditional fine-tuning approaches.
Critical Analysis
The paper presents a well-designed and thorough investigation of fine-tuning strategies for foundation models in the context of semi-supervised learning. The authors have identified an important challenge in the field and proposed a comprehensive framework to address it.
One potential limitation of the research is the specific set of architectural modifications and fine-tuning procedures explored. While the authors have examined several key techniques, there may be other innovative approaches or combinations of techniques that could further enhance the performance of fine-tuned foundation models. Additional research in this direction could uncover even more effective solutions.
Moreover, the paper focuses primarily on the technical aspects of the framework and its empirical performance. It would be valuable to also consider the broader implications and potential real-world applications of this work, as well as any potential ethical concerns or biases that may still exist in the fine-tuned models.
Overall, the "Erasing the Bias" framework represents a significant contribution to the field of semi-supervised learning and the effective utilization of large foundation models. The paper provides a solid foundation for further research and advancements in this area.
Conclusion
This paper presents a novel framework called "Erasing the Bias" for fine-tuning large foundation models to improve their performance on semi-supervised learning tasks. The key innovations include architectural modifications, carefully designed fine-tuning procedures, and the incorporation of regularization and consistency constraints.
The authors demonstrate the effectiveness of their approach through extensive experiments, showing that the fine-tuned models can significantly outperform traditional fine-tuning methods on a variety of benchmark datasets. This work has important implications for leveraging the power of large foundation models in real-world applications where labeled data is scarce.
Further research building upon this framework, exploring additional fine-tuning techniques, and investigating the broader societal implications of this work could lead to even more impactful advancements in the field of machine learning and its practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
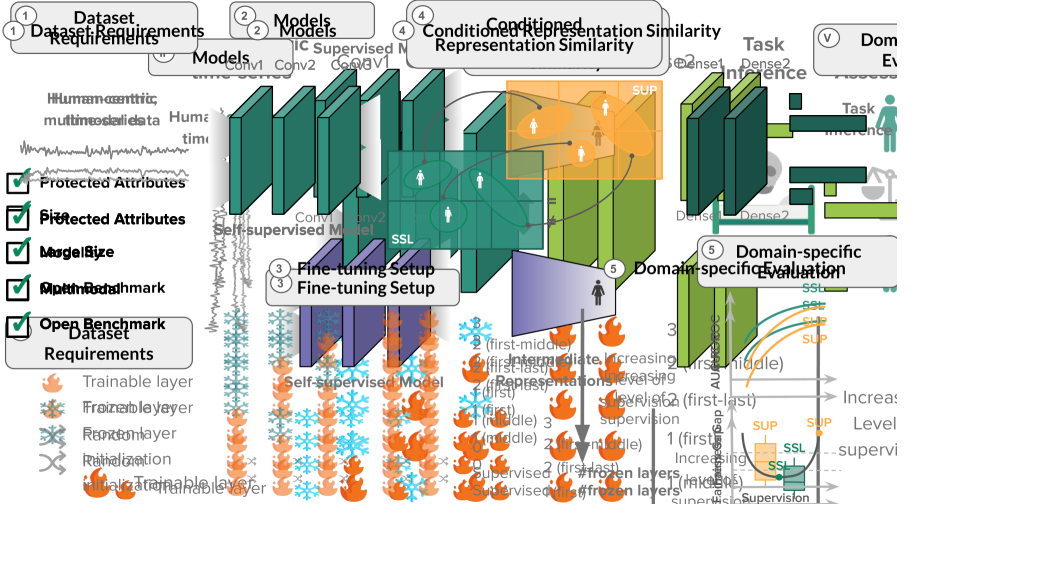
Using Self-supervised Learning Can Improve Model Fairness
Sofia Yfantidou, Dimitris Spathis, Marios Constantinides, Athena Vakali, Daniele Quercia, Fahim Kawsar
0
0
Self-supervised learning (SSL) has become the de facto training paradigm of large models, where pre-training is followed by supervised fine-tuning using domain-specific data and labels. Despite demonstrating comparable performance with supervised methods, comprehensive efforts to assess SSL's impact on machine learning fairness (i.e., performing equally on different demographic breakdowns) are lacking. Hypothesizing that SSL models would learn more generic, hence less biased representations, this study explores the impact of pre-training and fine-tuning strategies on fairness. We introduce a fairness assessment framework for SSL, comprising five stages: defining dataset requirements, pre-training, fine-tuning with gradual unfreezing, assessing representation similarity conditioned on demographics, and establishing domain-specific evaluation processes. We evaluate our method's generalizability on three real-world human-centric datasets (i.e., MIMIC, MESA, and GLOBEM) by systematically comparing hundreds of SSL and fine-tuned models on various dimensions spanning from the intermediate representations to appropriate evaluation metrics. Our findings demonstrate that SSL can significantly improve model fairness, while maintaining performance on par with supervised methods-exhibiting up to a 30% increase in fairness with minimal loss in performance through self-supervision. We posit that such differences can be attributed to representation dissimilarities found between the best- and the worst-performing demographics across models-up to x13 greater for protected attributes with larger performance discrepancies between segments.
6/5/2024
🔮
On Improving the Algorithm-, Model-, and Data- Efficiency of Self-Supervised Learning
Yun-Hao Cao, Jianxin Wu
0
0
Self-supervised learning (SSL) has developed rapidly in recent years. However, most of the mainstream methods are computationally expensive and rely on two (or more) augmentations for each image to construct positive pairs. Moreover, they mainly focus on large models and large-scale datasets, which lack flexibility and feasibility in many practical applications. In this paper, we propose an efficient single-branch SSL method based on non-parametric instance discrimination, aiming to improve the algorithm, model, and data efficiency of SSL. By analyzing the gradient formula, we correct the update rule of the memory bank with improved performance. We further propose a novel self-distillation loss that minimizes the KL divergence between the probability distribution and its square root version. We show that this alleviates the infrequent updating problem in instance discrimination and greatly accelerates convergence. We systematically compare the training overhead and performance of different methods in different scales of data, and under different backbones. Experimental results show that our method outperforms various baselines with significantly less overhead, and is especially effective for limited amounts of data and small models.
5/1/2024
🤿
Exploring Probabilistic Models for Semi-supervised Learning
Jianfeng Wang
0
0
This thesis studies advanced probabilistic models, including both their theoretical foundations and practical applications, for different semi-supervised learning (SSL) tasks. The proposed probabilistic methods are able to improve the safety of AI systems in real applications by providing reliable uncertainty estimates quickly, and at the same time, achieve competitive performance compared to their deterministic counterparts. The experimental results indicate that the methods proposed in the thesis have great value in safety-critical areas, such as the autonomous driving or medical imaging analysis domain, and pave the way for the future discovery of highly effective and efficient probabilistic approaches in the SSL sector.
4/8/2024
🗣️
On the social bias of speech self-supervised models
Yi-Cheng Lin, Tzu-Quan Lin, Hsi-Che Lin, Andy T. Liu, Hung-yi Lee
0
0
Self-supervised learning (SSL) speech models have achieved remarkable performance in various tasks, yet the biased outcomes, especially affecting marginalized groups, raise significant concerns. Social bias refers to the phenomenon where algorithms potentially amplify disparate properties between social groups present in the data used for training. Bias in SSL models can perpetuate injustice by automating discriminatory patterns and reinforcing inequitable systems. This work reveals that prevalent SSL models inadvertently acquire biased associations. We probe how various factors, such as model architecture, size, and training methodologies, influence the propagation of social bias within these models. Finally, we explore the efficacy of debiasing SSL models through regularization techniques, specifically via model compression. Our findings reveal that employing techniques such as row-pruning and training wider, shallower models can effectively mitigate social bias within SSL model.
6/10/2024