Reinforcement Learning-Guided Semi-Supervised Learning
2405.01760
0
0
Abstract
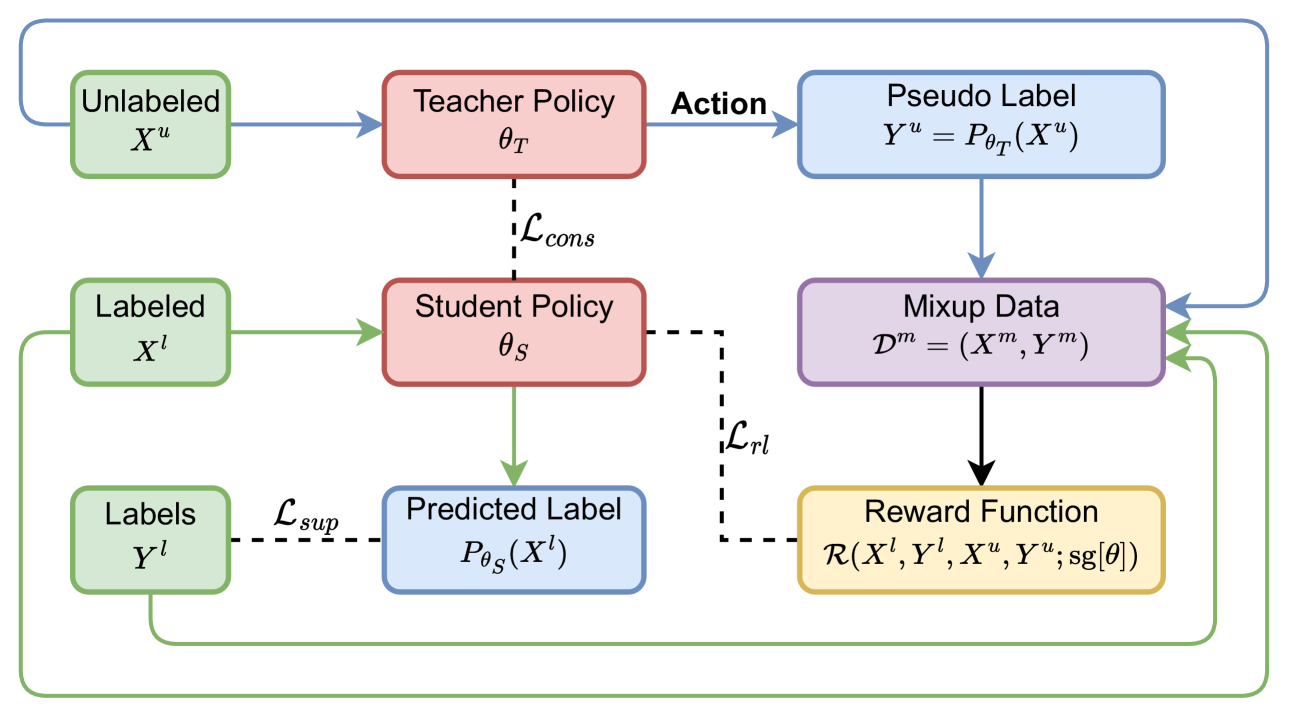
In recent years, semi-supervised learning (SSL) has gained significant attention due to its ability to leverage both labeled and unlabeled data to improve model performance, especially when labeled data is scarce. However, most current SSL methods rely on heuristics or predefined rules for generating pseudo-labels and leveraging unlabeled data. They are limited to exploiting loss functions and regularization methods within the standard norm. In this paper, we propose a novel Reinforcement Learning (RL) Guided SSL method, RLGSSL, that formulates SSL as a one-armed bandit problem and deploys an innovative RL loss based on weighted reward to adaptively guide the learning process of the prediction model. RLGSSL incorporates a carefully designed reward function that balances the use of labeled and unlabeled data to enhance generalization performance. A semi-supervised teacher-student framework is further deployed to increase the learning stability. We demonstrate the effectiveness of RLGSSL through extensive experiments on several benchmark datasets and show that our approach achieves consistent superior performance compared to state-of-the-art SSL methods.
Create account to get full access
Overview
- This paper proposes a novel approach called Reinforcement Learning-Guided Semi-Supervised Learning (RLGSSL) that combines reinforcement learning and semi-supervised learning to improve the sample efficiency and performance of machine learning models.
- The key idea is to use reinforcement learning to guide the semi-supervised learning process, allowing the model to learn from both labeled and unlabeled data more effectively.
- The authors demonstrate the effectiveness of RLGSSL on several benchmark datasets and show that it outperforms existing semi-supervised learning methods in terms of accuracy and sample efficiency.
Plain English Explanation
The paper introduces a new machine learning technique called Reinforcement Learning-Guided Semi-Supervised Learning (RLGSSL) that aims to improve the performance and efficiency of models by combining two existing approaches: reinforcement learning and semi-supervised learning.
In traditional supervised learning, models are trained on labeled data, which can be time-consuming and expensive to obtain. Semi-supervised learning tries to address this by using both labeled and unlabeled data to train models, but it can sometimes struggle to effectively leverage the unlabeled data.
Reinforcement learning is a technique where models learn by interacting with an environment and receiving rewards or penalties based on their actions. The key insight of RLGSSL is to use reinforcement learning to guide the semi-supervised learning process, allowing the model to better understand how to learn from the unlabeled data.
The authors demonstrate that RLGSSL outperforms traditional semi-supervised learning methods on several standard benchmarks, indicating that the combination of these two approaches can lead to more accurate and sample-efficient models. This could be particularly useful in domains where labeled data is scarce, as it allows models to learn more from the available unlabeled data.
Technical Explanation
The paper introduces a new semi-supervised learning algorithm called Reinforcement Learning-Guided Semi-Supervised Learning (RLGSSL) that leverages reinforcement learning to improve the performance and sample efficiency of models.
The core idea behind RLGSSL is to use a reinforcement learning agent to guide the semi-supervised learning process. The agent is trained to learn a policy that determines how the model should utilize the unlabeled data to improve its performance on the labeled data. This is achieved by defining a reward function that encourages the agent to take actions that lead to better model performance on the labeled data.
The authors formulate the semi-supervised learning problem as a Markov Decision Process, where the agent's actions correspond to strategies for incorporating the unlabeled data into the model training. The agent learns an optimal policy using reinforcement learning techniques, such as Q-learning or Policy Gradient.
The authors evaluate RLGSSL on several benchmark datasets and compare its performance to state-of-the-art semi-supervised learning methods, such as LW-FedSSL. The results demonstrate that RLGSSL achieves higher accuracy and requires fewer labeled samples to reach a given performance level, indicating its superior sample efficiency.
Critical Analysis
The paper presents a novel and promising approach to improving the performance and sample efficiency of machine learning models by combining reinforcement learning and semi-supervised learning. The key strength of RLGSSL is its ability to effectively leverage unlabeled data, which can be particularly valuable in domains where labeled data is scarce or expensive to obtain.
One potential limitation of the RLGSSL approach is the complexity of the reinforcement learning component, which may require careful hyperparameter tuning and can be computationally expensive. The authors acknowledge this and suggest further research to improve the algorithm's efficiency.
Additionally, the paper primarily focuses on evaluating RLGSSL on standard benchmark datasets, and it would be valuable to see how the approach performs on real-world, large-scale problems. The authors also do not discuss the potential challenges or limitations of applying RLGSSL in such contexts.
Overall, the paper presents a compelling and innovative approach to semi-supervised learning that has the potential to significantly improve the sample efficiency and performance of machine learning models. The technical details are well-explained, and the experimental results are promising. Further research to address the identified limitations and explore the real-world applicability of RLGSSL would be valuable.
Conclusion
The Reinforcement Learning-Guided Semi-Supervised Learning (RLGSSL) approach presented in this paper offers a novel and promising way to combine reinforcement learning and semi-supervised learning to improve the sample efficiency and performance of machine learning models. By using reinforcement learning to guide the semi-supervised learning process, RLGSSL can effectively leverage unlabeled data to enhance model training, which is particularly valuable in domains with limited labeled data.
The authors demonstrate the effectiveness of RLGSSL on several benchmark datasets, showing that it outperforms existing semi-supervised learning methods. This research has the potential to significantly impact the field of machine learning, as it addresses a fundamental challenge in building accurate and sample-efficient models, especially in real-world applications where labeled data is scarce.
While the paper identifies some potential limitations of the RLGSSL approach, such as the computational complexity of the reinforcement learning component, the overall contribution is highly valuable. Further research to address these challenges and explore the real-world applicability of RLGSSL could lead to even more impactful advancements in machine learning and its widespread adoption.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Prompt-based Pseudo-labeling Strategy for Sample-Efficient Semi-Supervised Extractive Summarization
Gaurav Sahu, Olga Vechtomova, Issam H. Laradji
0
0
Semi-supervised learning (SSL) is a widely used technique in scenarios where labeled data is scarce and unlabeled data is abundant. While SSL is popular for image and text classification, it is relatively underexplored for the task of extractive text summarization. Standard SSL methods follow a teacher-student paradigm to first train a classification model and then use the classifier's confidence values to select pseudo-labels for the subsequent training cycle; however, such classifiers are not suitable to measure the accuracy of pseudo-labels as they lack specific tuning for evaluation, which leads to confidence values that fail to capture the semantics and correctness of the generated summary. To address this problem, we propose a prompt-based pseudo-labeling strategy with LLMs that picks unlabeled examples with more accurate pseudo-labels than using just the classifier's probability outputs. Our approach also includes a relabeling mechanism that improves the quality of pseudo-labels. We evaluate our method on three text summarization datasets: TweetSumm, WikiHow, and ArXiv/PubMed. We empirically show that a prompting-based LLM that scores and generates pseudo-labels outperforms existing SSL methods on ROUGE-1, ROUGE-2, and ROUGE-L scores on all the datasets. Furthermore, our method achieves competitive G-Eval scores (evaluation with GPT-4) as a fully supervised method that uses 100% of the labeled data with only 16.67% of the labeled data.
4/8/2024

A Comprehensive Survey on Self-Supervised Learning for Recommendation
Xubin Ren, Wei Wei, Lianghao Xia, Chao Huang
0
0
Recommender systems play a crucial role in tackling the challenge of information overload by delivering personalized recommendations based on individual user preferences. Deep learning techniques, such as RNNs, GNNs, and Transformer architectures, have significantly propelled the advancement of recommender systems by enhancing their comprehension of user behaviors and preferences. However, supervised learning methods encounter challenges in real-life scenarios due to data sparsity, resulting in limitations in their ability to learn representations effectively. To address this, self-supervised learning (SSL) techniques have emerged as a solution, leveraging inherent data structures to generate supervision signals without relying solely on labeled data. By leveraging unlabeled data and extracting meaningful representations, recommender systems utilizing SSL can make accurate predictions and recommendations even when confronted with data sparsity. In this paper, we provide a comprehensive review of self-supervised learning frameworks designed for recommender systems, encompassing a thorough analysis of over 170 papers. We conduct an exploration of nine distinct scenarios, enabling a comprehensive understanding of SSL-enhanced recommenders in different contexts. For each domain, we elaborate on different self-supervised learning paradigms, namely contrastive learning, generative learning, and adversarial learning, so as to present technical details of how SSL enhances recommender systems in various contexts. We consistently maintain the related open-source materials at https://github.com/HKUDS/Awesome-SSLRec-Papers.
4/9/2024
🏅
Knowledge Graph Reasoning with Self-supervised Reinforcement Learning
Ying Ma, Owen Burns, Mingqiu Wang, Gang Li, Nan Du, Laurent El Shafey, Liqiang Wang, Izhak Shafran, Hagen Soltau
0
0
Reinforcement learning (RL) is an effective method of finding reasoning pathways in incomplete knowledge graphs (KGs). To overcome the challenges of a large action space, a self-supervised pre-training method is proposed to warm up the policy network before the RL training stage. To alleviate the distributional mismatch issue in general self-supervised RL (SSRL), in our supervised learning (SL) stage, the agent selects actions based on the policy network and learns from generated labels; this self-generation of labels is the intuition behind the name self-supervised. With this training framework, the information density of our SL objective is increased and the agent is prevented from getting stuck with the early rewarded paths. Our self-supervised RL (SSRL) method improves the performance of RL by pairing it with the wide coverage achieved by SL during pretraining, since the breadth of the SL objective makes it infeasible to train an agent with that alone. We show that our SSRL model meets or exceeds current state-of-the-art results on all Hits@k and mean reciprocal rank (MRR) metrics on four large benchmark KG datasets. This SSRL method can be used as a plug-in for any RL architecture for a KGR task. We adopt two RL architectures, i.e., MINERVA and MultiHopKG as our baseline RL models and experimentally show that our SSRL model consistently outperforms both baselines on all of these four KG reasoning tasks. Full code for the paper available at https://github.com/owenonline/Knowledge-Graph-Reasoning-with-Self-supervised-Reinforcement-Learning.
5/24/2024

From Obstacle to Opportunity: Enhancing Semi-supervised Learning with Synthetic Data
Zerun Wang, Jiafeng Mao, Liuyu Xiang, Toshihiko Yamasaki
0
0
Semi-supervised learning (SSL) can utilize unlabeled data to enhance model performance. In recent years, with increasingly powerful generative models becoming available, a large number of synthetic images have been uploaded to public image sets. Therefore, when collecting unlabeled data from these sources, the inclusion of synthetic images is inevitable. This prompts us to consider the impact of unlabeled data mixed with real and synthetic images on SSL. In this paper, we set up a new task, Real and Synthetic hybrid SSL (RS-SSL), to investigate this problem. We discover that current SSL methods are unable to fully utilize synthetic data and are sometimes negatively affected. Then, by analyzing the issues caused by synthetic images, we propose a new SSL method, RSMatch, to tackle the RS-SSL problem. Extensive experimental results show that RSMatch can better utilize the synthetic data in unlabeled images to improve the SSL performance. The effectiveness is further verified through ablation studies and visualization.
5/28/2024