Towards Zero-shot Point Cloud Anomaly Detection: A Multi-View Projection Framework

0

Sign in to get full access
Overview
- Zero-shot anomaly detection in point cloud data is a challenging problem.
- This paper proposes a [object Object] for zero-shot point cloud anomaly detection.
- The key idea is to project the point cloud into multiple 2D views and use a [object Object] to detect anomalies.
Plain English Explanation
The paper focuses on the problem of detecting anomalies in 3D [object Object] data without any prior training on the specific types of anomalies. This is known as "zero-shot" anomaly detection.
The key insight is that we can project the 3D point cloud onto multiple 2D views, similar to how we might view a 3D object from different angles. These 2D projections can then be fed into a powerful [object Object], which has been trained on a vast amount of visual and textual data.
The model can then use this broad knowledge to identify anomalies in the 2D projections, without needing any specific training on the types of anomalies that might occur in the 3D point cloud. This "zero-shot" approach allows the system to detect novel anomalies that it hasn't seen before.
The authors demonstrate that this [object Object] outperforms other zero-shot anomaly detection methods on several benchmark datasets, making it a promising technique for real-world applications like autonomous vehicle monitoring or industrial inspection.
Technical Explanation
The paper proposes a [object Object] for zero-shot point cloud anomaly detection. The key components are:
- Multi-view Projection: The 3D point cloud is projected onto multiple 2D views, capturing different perspectives of the data.
- Vision-Language Model: A pre-trained [object Object] is used to process the 2D projections and detect anomalies.
- Visual Prompting: The model is prompted with visual examples of normal and anomalous samples to guide the zero-shot detection process.
The authors evaluate their approach on several point cloud anomaly detection benchmarks, demonstrating superior performance compared to existing zero-shot methods. They also analyze the impact of different projection strategies and the robustness of the approach to various types of anomalies.
Critical Analysis
The paper presents a novel and promising approach to zero-shot point cloud anomaly detection, leveraging the power of [object Object] and multi-view projections. However, some potential limitations and areas for further research include:
- Reliance on Vision-Language Models: The performance of the proposed framework is heavily dependent on the capabilities of the underlying [object Object]. Improvements in these models could further boost the anomaly detection performance.
- Projection Quality: The choice of projection strategies and the quality of the 2D projections could impact the overall performance. Exploring more advanced projection techniques may lead to further improvements.
- Generalization to Real-World Scenarios: The experiments in the paper focus on controlled benchmark datasets, and further testing on more diverse and realistic point cloud data would be valuable to assess the practical applicability of the method.
- Interpretability and Explainability: The paper does not provide much insight into the decision-making process of the [object Object] and the reasons behind its anomaly detection decisions, which could be an important consideration for real-world applications.
Conclusion
The proposed [object Object] for zero-shot point cloud anomaly detection is a promising approach that leverages the power of [object Object] to detect novel anomalies without any prior training. The ability to perform zero-shot anomaly detection has significant practical applications in areas such as autonomous vehicle monitoring, industrial inspection, and infrastructure monitoring. While the paper demonstrates impressive results, further research is needed to address potential limitations and improve the robustness and interpretability of the approach for real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Zero-shot Point Cloud Anomaly Detection: A Multi-View Projection Framework
Yuqi Cheng, Yunkang Cao, Guoyang Xie, Zhichao Lu, Weiming Shen
Detecting anomalies within point clouds is crucial for various industrial applications, but traditional unsupervised methods face challenges due to data acquisition costs, early-stage production constraints, and limited generalization across product categories. To overcome these challenges, we introduce the Multi-View Projection (MVP) framework, leveraging pre-trained Vision-Language Models (VLMs) to detect anomalies. Specifically, MVP projects point cloud data into multi-view depth images, thereby translating point cloud anomaly detection into image anomaly detection. Following zero-shot image anomaly detection methods, pre-trained VLMs are utilized to detect anomalies on these depth images. Given that pre-trained VLMs are not inherently tailored for zero-shot point cloud anomaly detection and may lack specificity, we propose the integration of learnable visual and adaptive text prompting techniques to fine-tune these VLMs, thereby enhancing their detection performance. Extensive experiments on the MVTec 3D-AD and Real3D-AD demonstrate our proposed MVP framework's superior zero-shot anomaly detection performance and the prompting techniques' effectiveness. Real-world evaluations on automotive plastic part inspection further showcase that the proposed method can also be generalized to practical unseen scenarios. The code is available at https://github.com/hustCYQ/MVP-PCLIP.
Read more9/23/2024
0
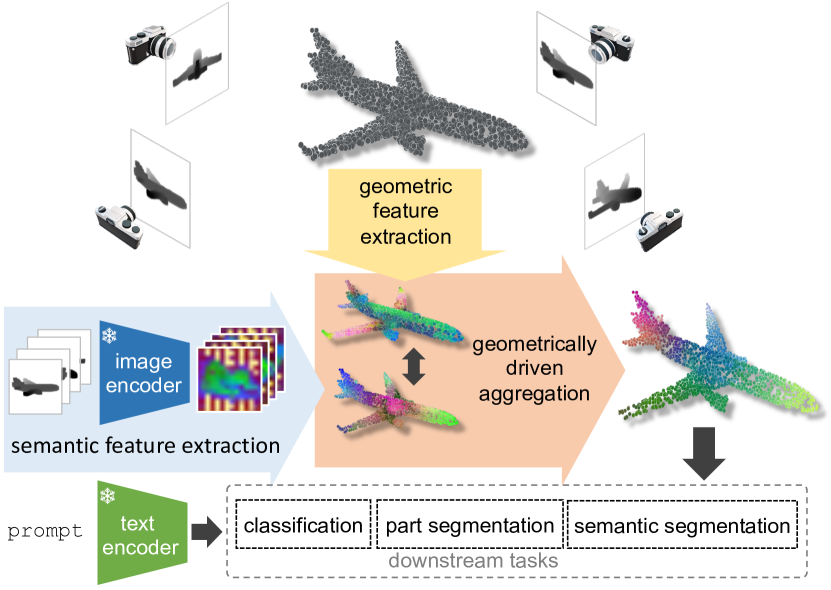
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. Code and dataset are available at https://luigiriz.github.io/geoze-website/
Read more4/16/2024

0
New!PointAD: Comprehending 3D Anomalies from Points and Pixels for Zero-shot 3D Anomaly Detection
Qihang Zhou, Jiangtao Yan, Shibo He, Wenchao Meng, Jiming Chen
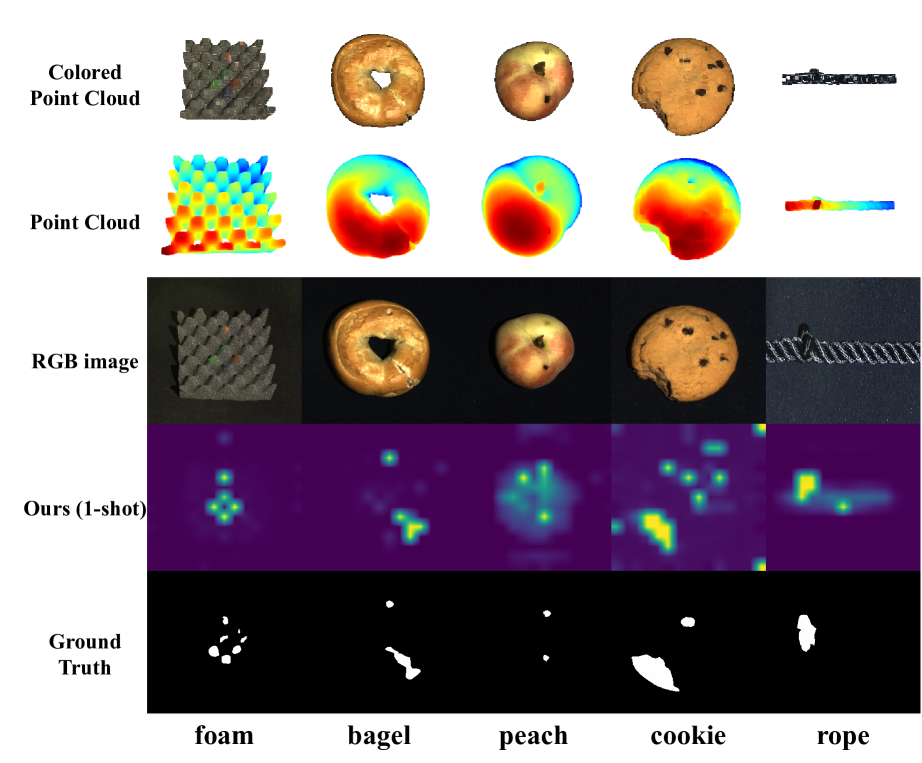
Zero-shot (ZS) 3D anomaly detection is a crucial yet unexplored field that addresses scenarios where target 3D training samples are unavailable due to practical concerns like privacy protection. This paper introduces PointAD, a novel approach that transfers the strong generalization capabilities of CLIP for recognizing 3D anomalies on unseen objects. PointAD provides a unified framework to comprehend 3D anomalies from both points and pixels. In this framework, PointAD renders 3D anomalies into multiple 2D renderings and projects them back into 3D space. To capture the generic anomaly semantics into PointAD, we propose hybrid representation learning that optimizes the learnable text prompts from 3D and 2D through auxiliary point clouds. The collaboration optimization between point and pixel representations jointly facilitates our model to grasp underlying 3D anomaly patterns, contributing to detecting and segmenting anomalies of unseen diverse 3D objects. Through the alignment of 3D and 2D space, our model can directly integrate RGB information, further enhancing the understanding of 3D anomalies in a plug-and-play manner. Extensive experiments show the superiority of PointAD in ZS 3D anomaly detection across diverse unseen objects.
Read more10/2/2024
0
CLIP3D-AD: Extending CLIP for 3D Few-Shot Anomaly Detection with Multi-View Images Generation
Zuo Zuo, Jiahao Dong, Yao Wu, Yanyun Qu, Zongze Wu
Few-shot anomaly detection methods can effectively address data collecting difficulty in industrial scenarios. Compared to 2D few-shot anomaly detection (2D-FSAD), 3D few-shot anomaly detection (3D-FSAD) is still an unexplored but essential task. In this paper, we propose CLIP3D-AD, an efficient 3D-FSAD method extended on CLIP. We successfully transfer strong generalization ability of CLIP into 3D-FSAD. Specifically, we synthesize anomalous images on given normal images as sample pairs to adapt CLIP for 3D anomaly classification and segmentation. For classification, we introduce an image adapter and a text adapter to fine-tune global visual features and text features. Meanwhile, we propose a coarse-to-fine decoder to fuse and facilitate intermediate multi-layer visual representations of CLIP. To benefit from geometry information of point cloud and eliminate modality and data discrepancy when processed by CLIP, we project and render point cloud to multi-view normal and anomalous images. Then we design multi-view fusion module to fuse features of multi-view images extracted by CLIP which are used to facilitate visual representations for further enhancing vision-language correlation. Extensive experiments demonstrate that our method has a competitive performance of 3D few-shot anomaly classification and segmentation on MVTec-3D AD dataset.
Read more6/28/2024