Ethical Challenges in Computer Vision: Ensuring Privacy and Mitigating Bias in Publicly Available Datasets

0
🧠
Sign in to get full access
Overview
- Identifies ethical challenges in computer vision, particularly regarding privacy and bias in publicly available datasets.
- Proposes strategies to address these challenges and ensure responsible development of computer vision systems.
- Emphasizes the importance of mitigating privacy risks and algorithmic biases in publicly available datasets used for training.
Plain English Explanation
Computer vision systems, which allow machines to analyze and interpret visual information, have become increasingly powerful and widely used. However, the datasets used to train these systems can raise important ethical concerns. This paper explores two key challenges: ensuring the privacy of individuals represented in these datasets and mitigating biases that can be present in the data.
Protecting Privacy: Many publicly available datasets used for computer vision research contain personal information, such as images of people's faces or other identifying details. This raises privacy risks, as the data could be misused or leaked. The paper discusses strategies to address this, such as employing techniques to anonymize or obfuscate sensitive information while preserving the dataset's utility for research.
Mitigating Bias: Datasets used to train computer vision models may not accurately represent the diversity of the real world, leading to algorithmic biases. For example, a dataset primarily composed of images of white individuals could result in a facial recognition system that performs poorly on people of color. The paper explores methods to assess and reduce these biases, ensuring more inclusive and equitable computer vision systems.
By addressing these ethical challenges, the research aims to guide the development of computer vision technologies that respect individual privacy and promote fairness and inclusion. This is crucial as these systems become increasingly prevalent in applications like surveillance, healthcare, and consumer services.
Technical Explanation
The paper first outlines the rapid progress and widespread adoption of computer vision, which has enabled a wide range of applications. However, the authors note that the datasets used to train these systems can raise significant ethical concerns, particularly around privacy and bias.
Regarding privacy, the paper discusses how many publicly available computer vision datasets contain sensitive personal information, such as images of individuals' faces or other identifying details. This creates risks of data misuse or unintended exposure, which could harm the privacy and well-being of the people represented in the datasets. To address this, the authors propose several techniques, including:
- Data anonymization: Modifying or removing personal identifiers while preserving the dataset's utility for research.
- Differential privacy: Adding noise to the dataset to make it more difficult to re-identify individuals.
- Synthetic data generation: Creating realistic but artificial data that captures the statistical properties of the original dataset without using real personal information.
The paper also explores the challenge of mitigating biases in computer vision datasets. Datasets used to train these systems may not accurately reflect the diversity of the real world, leading to algorithmic biases that can disadvantage certain demographics. To address this, the authors discuss methods for:
- Dataset bias assessment: Developing techniques to measure and quantify the biases present in a given dataset.
- Dataset augmentation: Expanding and diversifying datasets to better represent underrepresented groups.
- Debiasing model training: Incorporating fairness constraints and other techniques into the machine learning model training process to mitigate biases.
Through these approaches, the paper aims to guide the development of computer vision systems that respect individual privacy and promote fairness and inclusion, ensuring these powerful technologies are deployed responsibly.
Critical Analysis
The paper identifies important ethical challenges in the field of computer vision that must be addressed as these technologies become more ubiquitous. The authors provide a comprehensive overview of the key issues and propose a range of technical strategies to mitigate privacy risks and algorithmic biases.
One potential limitation of the paper is that it focuses primarily on addressing these challenges at the dataset level, without extensively discussing the broader societal and regulatory implications. While the proposed techniques are valuable, there may also be a need for stronger data governance frameworks, user consent protocols, and accountability measures to ensure the responsible use of computer vision technologies.
Additionally, the paper could benefit from a more in-depth discussion of the trade-offs and challenges involved in implementing some of the proposed solutions. For example, while techniques like differential privacy and synthetic data generation can help protect privacy, they may also introduce uncertainties or reduce the dataset's utility for certain research tasks.
Overall, this paper makes a valuable contribution to the ongoing dialogue around the ethical development of computer vision systems. By highlighting these crucial issues and proposing technical approaches to address them, the authors encourage the research community and policymakers to work towards more responsible and inclusive computer vision technologies.
Conclusion
This paper identifies two critical ethical challenges in the field of computer vision: ensuring the privacy of individuals represented in publicly available datasets and mitigating biases in these datasets that can lead to unfair and exclusionary algorithmic outcomes. The authors propose a range of technical strategies to address these issues, including data anonymization, differential privacy, synthetic data generation, dataset bias assessment, and debiasing model training.
By addressing these ethical concerns, the research aims to guide the development of computer vision systems that respect individual privacy and promote fairness and inclusion. As these powerful technologies become increasingly prevalent in various applications, it is crucial that they are deployed responsibly and in a manner that benefits all members of society. This paper provides a valuable framework for researchers, policymakers, and industry stakeholders to work towards this goal.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
New!Ethical Challenges in Computer Vision: Ensuring Privacy and Mitigating Bias in Publicly Available Datasets
Ghalib Ahmed Tahir
This paper aims to shed light on the ethical problems of creating and deploying computer vision tech, particularly in using publicly available datasets. Due to the rapid growth of machine learning and artificial intelligence, computer vision has become a vital tool in many industries, including medical care, security systems, and trade. However, extensive use of visual data that is often collected without consent due to an informed discussion of its ramifications raises significant concerns about privacy and bias. The paper also examines these issues by analyzing popular datasets such as COCO, LFW, ImageNet, CelebA, PASCAL VOC, etc., that are usually used for training computer vision models. We offer a comprehensive ethical framework that addresses these challenges regarding the protection of individual rights, minimization of bias as well as openness and responsibility. We aim to encourage AI development that will take into account societal values as well as ethical standards to avoid any public harm.
Read more9/19/2024

0
Open Challenges on Fairness of Artificial Intelligence in Medical Imaging Applications
Enzo Ferrante, Rodrigo Echeveste
Recently, the research community of computerized medical imaging has started to discuss and address potential fairness issues that may emerge when developing and deploying AI systems for medical image analysis. This chapter covers some of the pressing challenges encountered when doing research in this area, and it is intended to raise questions and provide food for thought for those aiming to enter this research field. The chapter first discusses various sources of bias, including data collection, model training, and clinical deployment, and their impact on the fairness of machine learning algorithms in medical image computing. We then turn to discussing open challenges that we believe require attention from researchers and practitioners, as well as potential pitfalls of naive application of common methods in the field. We cover a variety of topics including the impact of biased metrics when auditing for fairness, the leveling down effect, task difficulty variations among subgroups, discovering biases in unseen populations, and explaining biases beyond standard demographic attributes.
Read more7/25/2024

0
Copycats: the many lives of a publicly available medical imaging dataset
Amelia Jim'enez-S'anchez, Natalia-Rozalia Avlona, Dovile Juodelyte, Th'eo Sourget, Caroline Vang-Larsen, Anna Rogers, Hubert Dariusz Zajk{a}c, Veronika Cheplygina
Medical Imaging (MI) datasets are fundamental to artificial intelligence in healthcare. The accuracy, robustness, and fairness of diagnostic algorithms depend on the data (and its quality) used to train and evaluate the models. MI datasets used to be proprietary, but have become increasingly available to the public, including on community-contributed platforms (CCPs) like Kaggle or HuggingFace. While open data is important to enhance the redistribution of data's public value, we find that the current CCP governance model fails to uphold the quality needed and recommended practices for sharing, documenting, and evaluating datasets. In this paper, we conduct an analysis of publicly available machine learning datasets on CCPs, discussing datasets' context, and identifying limitations and gaps in the current CCP landscape. We highlight differences between MI and computer vision datasets, particularly in the potentially harmful downstream effects from poor adoption of recommended dataset management practices. We compare the analyzed datasets across several dimensions, including data sharing, data documentation, and maintenance. We find vague licenses, lack of persistent identifiers and storage, duplicates, and missing metadata, with differences between the platforms. Our research contributes to efforts in responsible data curation and AI algorithms for healthcare.
Read more6/11/2024
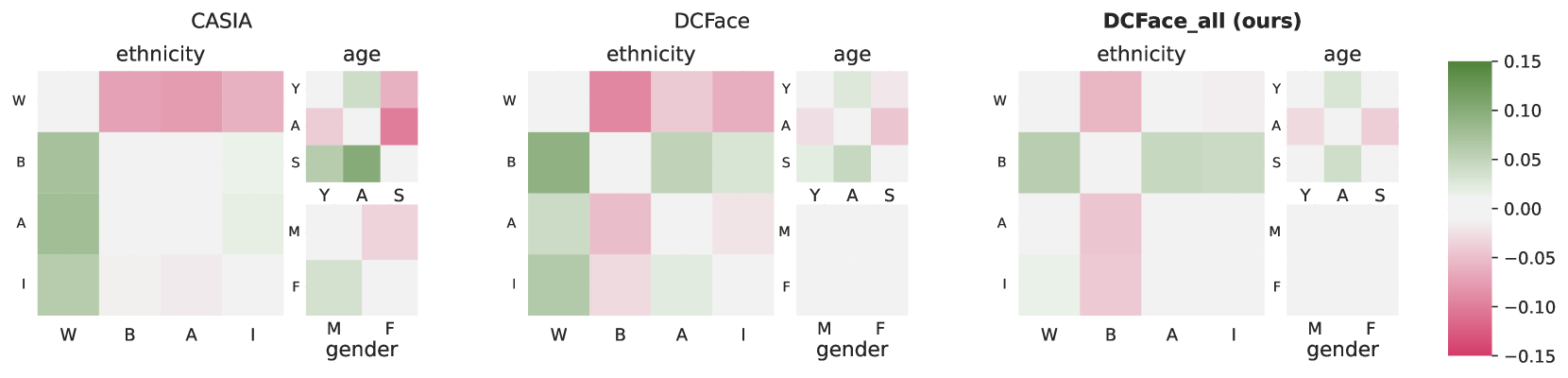
0
Toward Fairer Face Recognition Datasets
Alexandre Fournier-Mongieux, Michael Soumm, Adrian Popescu, Bertrand Luvison, Herv'e Le Borgne
Face recognition and verification are two computer vision tasks whose performance has progressed with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive character of face data and biases in real training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems persist. We promote fairness by introducing a demographic attributes balancing mechanism in generated training datasets. We experiment with an existing real dataset, three generated training datasets, and the balanced versions of a diffusion-based dataset. We propose a comprehensive evaluation that considers accuracy and fairness equally and includes a rigorous regression-based statistical analysis of attributes. The analysis shows that balancing reduces demographic unfairness. Also, a performance gap persists despite generation becoming more accurate with time. The proposed balancing method and comprehensive verification evaluation promote fairer and transparent face recognition and verification.
Read more6/26/2024