Copycats: the many lives of a publicly available medical imaging dataset

0

Sign in to get full access
Overview
- This paper discusses the importance of making open medical imaging datasets more actionable for the research community.
- The authors analyze the lessons learned from community-contributed platforms for data management and stewardship.
- The goal is to improve the usability and impact of open medical imaging datasets.
Plain English Explanation
The paper focuses on how to make open medical imaging datasets more useful and effective for researchers and developers. Open datasets are important for advancing medical imaging research, but they often have challenges that limit their real-world impact. The authors looked at lessons from existing community-driven platforms that help manage and maintain open datasets.
By understanding the common issues and best practices from these platforms, the goal is to provide guidance on how to make open medical imaging datasets more "actionable" - in other words, more accessible, usable, and impactful for the wider research community. This could involve improvements to data curation, documentation, tooling, and overall dataset stewardship.
The core idea is that open datasets are a crucial part of advancing medical imaging AI, but their full potential is often hindered by practical challenges. By taking a close look at successful community efforts to manage open data, the authors aim to identify ways to make these datasets more valuable and usable for researchers working on real-world medical AI applications.
Technical Explanation
The paper examines the challenges and best practices for making open medical imaging datasets more actionable, drawing insights from the experiences of community-contributed data management platforms.
The authors first provide background on the importance of open datasets in advancing medical imaging AI, as well as the common issues that limit their real-world impact, such as incomplete documentation, lack of tooling, and unclear data provenance. They then analyze several prominent community platforms that have tackled these challenges, including RADEDIT, MedMNIST, and MMIST-CCRCC.
Through this analysis, the authors identify key lessons and best practices for improving the actionability of open medical imaging datasets. These include developing standardized metadata schemas, providing user-friendly data access and visualization tools, establishing clear data use policies, and fostering active dataset curation and stewardship by the research community.
The paper also discusses the potential of multi-dataset and multi-task learning approaches to further enhance the utility of open medical imaging datasets by enabling more robust and generalizable AI models.
Critical Analysis
The paper provides a valuable perspective on the practical challenges of making open medical imaging datasets truly impactful for the research community. The authors rightly acknowledge that simply releasing datasets is not enough - careful curation, documentation, and stewardship are essential for ensuring their long-term usability and relevance.
While the paper highlights several successful community-driven platforms, it would be helpful to have a more detailed analysis of the specific trade-offs and design decisions made by these platforms. Additionally, the paper could benefit from a deeper discussion of the potential limitations or unintended consequences of the proposed approaches, such as the risk of increased data silos or the burden of ongoing curation efforts on dataset maintainers.
It would also be interesting to see the authors explore the role of standardization and interoperability across open medical imaging datasets, as well as the potential implications of newer data sharing paradigms, such as federated learning, for addressing some of the actionability challenges.
Conclusion
This paper makes a compelling case for the importance of improving the actionability of open medical imaging datasets. By learning from the experiences of community-contributed data management platforms, the authors identify key best practices and strategies for enhancing the usability, impact, and long-term sustainability of these crucial research resources.
The insights and recommendations presented in this paper have the potential to significantly strengthen the role of open data in driving progress in medical imaging AI, ultimately leading to more robust and impactful solutions for real-world healthcare applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Copycats: the many lives of a publicly available medical imaging dataset
Amelia Jim'enez-S'anchez, Natalia-Rozalia Avlona, Dovile Juodelyte, Th'eo Sourget, Caroline Vang-Larsen, Anna Rogers, Hubert Dariusz Zajk{a}c, Veronika Cheplygina
Medical Imaging (MI) datasets are fundamental to artificial intelligence in healthcare. The accuracy, robustness, and fairness of diagnostic algorithms depend on the data (and its quality) used to train and evaluate the models. MI datasets used to be proprietary, but have become increasingly available to the public, including on community-contributed platforms (CCPs) like Kaggle or HuggingFace. While open data is important to enhance the redistribution of data's public value, we find that the current CCP governance model fails to uphold the quality needed and recommended practices for sharing, documenting, and evaluating datasets. In this paper, we conduct an analysis of publicly available machine learning datasets on CCPs, discussing datasets' context, and identifying limitations and gaps in the current CCP landscape. We highlight differences between MI and computer vision datasets, particularly in the potentially harmful downstream effects from poor adoption of recommended dataset management practices. We compare the analyzed datasets across several dimensions, including data sharing, data documentation, and maintenance. We find vague licenses, lack of persistent identifiers and storage, duplicates, and missing metadata, with differences between the platforms. Our research contributes to efforts in responsible data curation and AI algorithms for healthcare.
Read more6/11/2024
📊
0
[Citation needed] Data usage and citation practices in medical imaging conferences
Th'eo Sourget, Ahmet Akkoc{c}, Stinna Winther, Christine Lyngbye Galsgaard, Amelia Jim'enez-S'anchez, Dovile Juodelyte, Caroline Petitjean, Veronika Cheplygina
Medical imaging papers often focus on methodology, but the quality of the algorithms and the validity of the conclusions are highly dependent on the datasets used. As creating datasets requires a lot of effort, researchers often use publicly available datasets, there is however no adopted standard for citing the datasets used in scientific papers, leading to difficulty in tracking dataset usage. In this work, we present two open-source tools we created that could help with the detection of dataset usage, a pipeline url{https://github.com/TheoSourget/Public_Medical_Datasets_References} using OpenAlex and full-text analysis, and a PDF annotation software url{https://github.com/TheoSourget/pdf_annotator} used in our study to manually label the presence of datasets. We applied both tools on a study of the usage of 20 publicly available medical datasets in papers from MICCAI and MIDL. We compute the proportion and the evolution between 2013 and 2023 of 3 types of presence in a paper: cited, mentioned in the full text, cited and mentioned. Our findings demonstrate the concentration of the usage of a limited set of datasets. We also highlight different citing practices, making the automation of tracking difficult.
Read more9/12/2024
🧠
0
New!Ethical Challenges in Computer Vision: Ensuring Privacy and Mitigating Bias in Publicly Available Datasets
Ghalib Ahmed Tahir
This paper aims to shed light on the ethical problems of creating and deploying computer vision tech, particularly in using publicly available datasets. Due to the rapid growth of machine learning and artificial intelligence, computer vision has become a vital tool in many industries, including medical care, security systems, and trade. However, extensive use of visual data that is often collected without consent due to an informed discussion of its ramifications raises significant concerns about privacy and bias. The paper also examines these issues by analyzing popular datasets such as COCO, LFW, ImageNet, CelebA, PASCAL VOC, etc., that are usually used for training computer vision models. We offer a comprehensive ethical framework that addresses these challenges regarding the protection of individual rights, minimization of bias as well as openness and responsibility. We aim to encourage AI development that will take into account societal values as well as ethical standards to avoid any public harm.
Read more9/19/2024
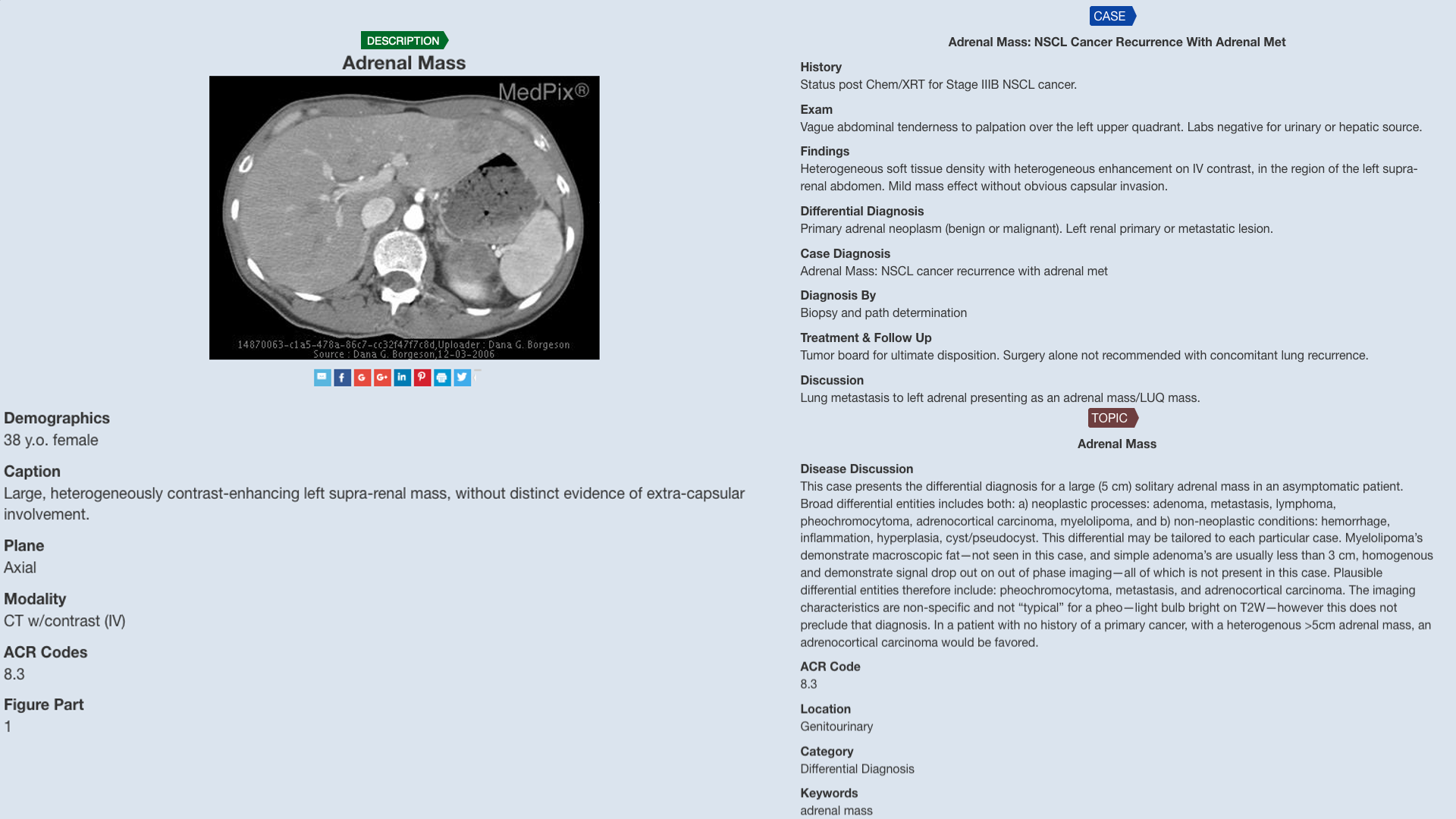
0
MedPix 2.0: A Comprehensive Multimodal Biomedical Dataset for Advanced AI Applications
Irene Siragusa, Salvatore Contino, Massimo La Ciura, Rosario Alicata, Roberto Pirrone
The increasing interest in developing Artificial Intelligence applications in the medical domain, suffers from the lack of high-quality dataset, mainly due to privacy-related issues. Moreover, the recent rising of Multimodal Large Language Models (MLLM) leads to a need for multimodal medical datasets, where clinical reports and findings are attached to the corresponding CT or MR scans. This paper illustrates the entire workflow for building the data set MedPix 2.0. Starting from the well-known multimodal dataset MedPixtextsuperscript{textregistered}, mainly used by physicians, nurses and healthcare students for Continuing Medical Education purposes, a semi-automatic pipeline was developed to extract visual and textual data followed by a manual curing procedure where noisy samples were removed, thus creating a MongoDB database. Along with the dataset, we developed a GUI aimed at navigating efficiently the MongoDB instance, and obtaining the raw data that can be easily used for training and/or fine-tuning MLLMs. To enforce this point, we also propose a CLIP-based model trained on MedPix 2.0 for scan classification tasks.
Read more7/4/2024