Ethics of Generating Synthetic MRI Vocal Tract Views from the Face

0

Sign in to get full access
Overview
- This paper discusses the ethical considerations around generating synthetic MRI vocal tract views from facial images using AI models.
- The researchers explore the potential risks and benefits of this technology, and provide recommendations for responsible development and deployment.
- Key concerns include privacy, consent, and the potential for misuse or unintended consequences.
Plain English Explanation
The paper looks at the ethics of using AI to generate 3D images of a person's vocal tract (the part of the throat and mouth involved in speech) based only on a photograph of their face. This technology could have useful applications, like improving speech recognition or language learning. However, it also raises important privacy and consent concerns.
Generating these vocal tract images from facial features alone means the technology could potentially be used to obtain sensitive information about an individual without their knowledge or permission. There are also risks around this data being misused, for example to impersonate someone's voice.
The researchers provide guidance on how to develop and use this technology responsibly, to maximize the benefits while minimizing the risks. For example, they suggest getting explicit consent before generating these vocal tract images, and putting strict controls in place to prevent unauthorized access or misuse of the data.
Technical Explanation
The paper explores the ethical considerations around using multimodal segmentation and vocal tract modeling to generate synthetic MRI views of a person's vocal tract based only on their facial image. This builds on previous research in areas like synthetic brain image generation and speech-driven 3D facial animation.
The researchers identify key ethical concerns, including privacy, consent, and potential misuse. They provide a framework for evaluating the trade-offs and developing responsible guidelines for this technology. This includes considerations around data collection, model transparency, and deployment safeguards.
Critical Analysis
The paper provides a thoughtful and nuanced discussion of the ethical implications. It rightly highlights the importance of obtaining informed consent before generating these vocal tract images, and the need for strict access controls to prevent unauthorized use.
However, the paper could have delved deeper into some of the potential harms and unintended consequences. For example, there are broader societal concerns around the proliferation of synthetic media and the erosion of trust. The researchers could have also explored edge cases or adversarial scenarios in more detail.
Additionally, the paper focuses primarily on the technology itself, without much discussion of the broader ecosystem and stakeholders involved. Engaging with a wider range of perspectives, such as from speech pathologists, privacy advocates, or end-users, could have strengthened the analysis.
Conclusion
This paper makes an important contribution to the growing discourse around the ethical development and deployment of generative AI models, particularly in sensitive domains like healthcare and speech. The researchers provide a solid foundation for thinking through the nuanced trade-offs, and offer guidance that can help ensure this technology is used in a responsible and beneficial manner.
As vision-language models and other multimodal AI capabilities continue to advance, it will be crucial for the research community to maintain this level of diligence and foresight around the ethical implications. Ongoing collaboration between technologists, domain experts, and the public will be key to realizing the full potential of these powerful tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Ethics of Generating Synthetic MRI Vocal Tract Views from the Face
Muhammad Suhaib Shahid, Gleb E. Yakubov, Andrew P. French
Forming oral models capable of understanding the complete dynamics of the oral cavity is vital across research areas such as speech correction, designing foods for the aging population, and dentistry. Magnetic resonance imaging (MRI) technologies, capable of capturing oral data essential for creating such detailed representations, offer a powerful tool for illustrating articulatory dynamics. However, its real-time application is hindered by expense and expertise requirements. Ever advancing generative AI approaches present themselves as a way to address this barrier by leveraging multi-modal approaches for generating pseudo-MRI views. Nonetheless, this immediately sparks ethical concerns regarding the utilisation of a technology with the capability to produce MRIs from facial observations. This paper explores the ethical implications of external-to-internal correlation modeling (E2ICM). E2ICM utilises facial movements to infer internal configurations and provides a cost-effective supporting technology for MRI. In this preliminary work, we employ Pix2PixGAN to generate pseudo-MRI views from external articulatory data, demonstrating the feasibility of this approach. Ethical considerations concerning privacy, consent, and potential misuse, which are fundamental to our examination of this innovative methodology, are discussed as a result of this experimentation.
Read more7/12/2024

0
Speech2rtMRI: Speech-Guided Diffusion Model for Real-time MRI Video of the Vocal Tract during Speech
Hong Nguyen, Sean Foley, Kevin Huang, Xuan Shi, Tiantian Feng, Shrikanth Narayanan
Understanding speech production both visually and kinematically can inform second language learning system designs, as well as the creation of speaking characters in video games and animations. In this work, we introduce a data-driven method to visually represent articulator motion in Magnetic Resonance Imaging (MRI) videos of the human vocal tract during speech based on arbitrary audio or speech input. We leverage large pre-trained speech models, which are embedded with prior knowledge, to generalize the visual domain to unseen data using a speech-to-video diffusion model. Our findings demonstrate that the visual generation significantly benefits from the pre-trained speech representations. We also observed that evaluating phonemes in isolation is challenging but becomes more straightforward when assessed within the context of spoken words. Limitations of the current results include the presence of unsmooth tongue motion and video distortion when the tongue contacts the palate.
Read more9/25/2024
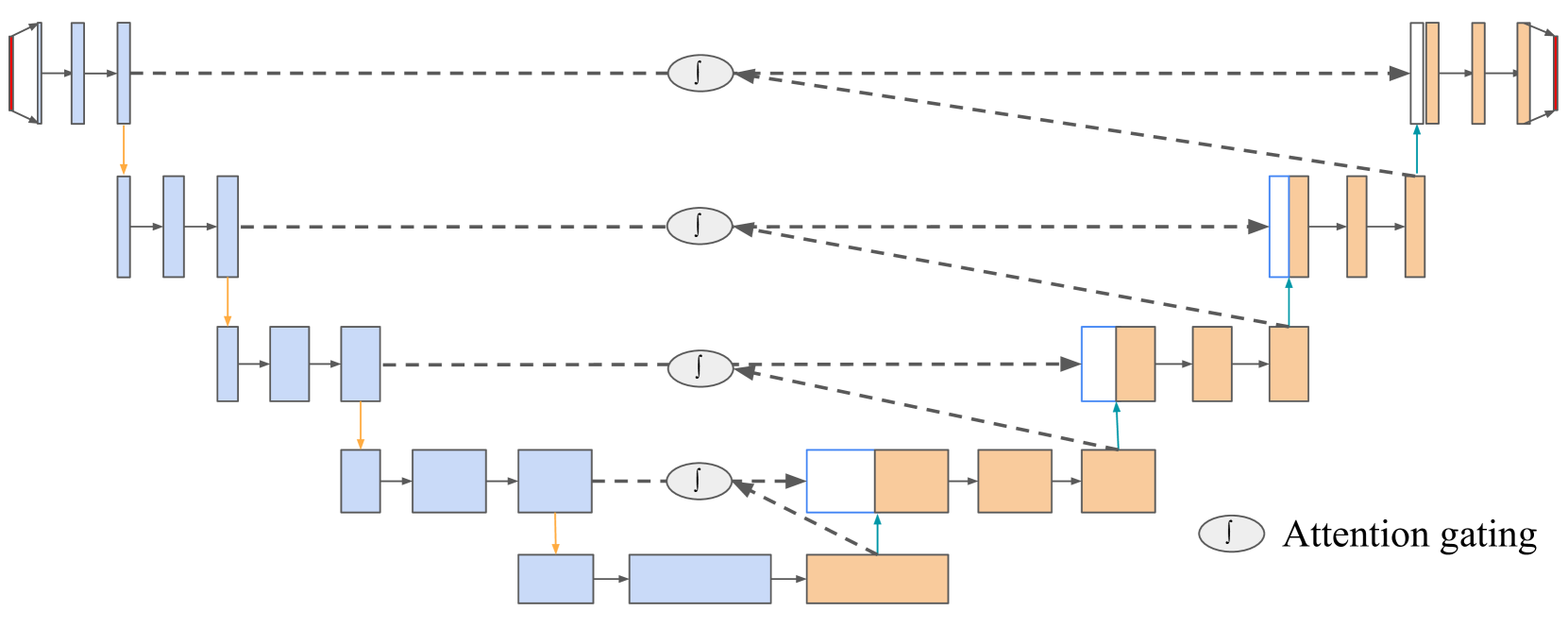
0
Multimodal Segmentation for Vocal Tract Modeling
Rishi Jain, Bohan Yu, Peter Wu, Tejas Prabhune, Gopala Anumanchipalli
Accurate modeling of the vocal tract is necessary to construct articulatory representations for interpretable speech processing and linguistics. However, vocal tract modeling is challenging because many internal articulators are occluded from external motion capture technologies. Real-time magnetic resonance imaging (RT-MRI) allows measuring precise movements of internal articulators during speech, but annotated datasets of MRI are limited in size due to time-consuming and computationally expensive labeling methods. We first present a deep labeling strategy for the RT-MRI video using a vision-only segmentation approach. We then introduce a multimodal algorithm using audio to improve segmentation of vocal articulators. Together, we set a new benchmark for vocal tract modeling in MRI video segmentation and use this to release labels for a 75-speaker RT-MRI dataset, increasing the amount of labeled public RT-MRI data of the vocal tract by over a factor of 9. The code and dataset labels can be found at url{rishiraij.github.io/multimodal-mri-avatar/}.
Read more6/26/2024
🤿
0
BrainVoxGen: Deep learning framework for synthesis of Ultrasound to MRI
Shubham Singh, Mrunal Bewoor, Ammar Ranapurwala, Satyam Rai, Sheetal Patil
The work proposes a novel deep-learning framework for the synthesis of three-dimensional MRI volumes from corresponding 3D ultrasound images of the brain, leveraging a modified iteration of the Pix2Pix Generative Adversarial Network (GAN) model. Addressing the formidable challenge of bridging the modality disparity between ultrasound and MRI, this research holds promise for transformative applications in medical diagnostics and treatment planning within the neuroimaging domain. While the findings reveal a discernible degree of similarity between the synthesized MRI volumes and anticipated outcomes, they fall short of practical deployment standards, primarily due to constraints associated with dataset scale and computational resources. The methodology yields MRI volumes with a satisfactory similarity score, establishing a foundational benchmark for subsequent investigations.
Read more7/19/2024