Speech2rtMRI: Speech-Guided Diffusion Model for Real-time MRI Video of the Vocal Tract during Speech

0

Sign in to get full access
Overview
- This paper introduces a speech-guided diffusion model called "Speech2rtMRI" for generating real-time MRI video of the vocal tract during speech.
- The model uses speech audio as input to generate high-quality video of the vocal tract, which can be useful for speech production research and clinical applications.
- The researchers demonstrate that the model can generate realistic videos that capture the complex dynamics of the vocal tract during speech.
Plain English Explanation
The researchers have developed a Speech2rtMRI, a speech-guided diffusion model that can generate real-time MRI videos of the vocal tract during speech. This means the model can take a person's speech audio as input and create a realistic video showing the movements of their vocal tract as they speak.
This could be very useful for speech production research and clinical applications, like studying how the vocal tract works or diagnosing speech disorders. The videos generated by the model capture the complex, dynamic motions of the vocal tract in a way that is difficult to observe directly.
The key innovation is using a "diffusion model", which is a type of machine learning technique, to generate the video from the speech audio input. Diffusion models are good at creating high-quality, realistic images and videos by learning the patterns in data. In this case, the model learns the relationship between speech audio and the corresponding vocal tract movements, allowing it to generate new video from just the audio.
Technical Explanation
The Speech2rtMRI model is a speech-guided diffusion model that takes speech audio as input and generates real-time MRI video of the vocal tract. The model consists of a U-Net-based neural network architecture that maps the speech audio features to the corresponding MRI video frames.
The key components of the model include:
- Speech encoder: Encodes the input speech audio into a compact representation.
- Video diffusion model: Uses a diffusion process to generate the output MRI video frames from the speech encoding.
- Video refinement module: Refines the generated video to produce higher-quality results.
The model is trained end-to-end on paired audio-video data of subjects speaking. During inference, the model takes a new speech audio input and generates a synchronized MRI video of the vocal tract.
The researchers demonstrate that the Speech2rtMRI model can generate high-quality, realistic videos that capture the complex dynamics of the vocal tract, outperforming previous approaches. This could enable new applications in speech production research and clinical diagnosis.
Critical Analysis
The Speech2rtMRI paper presents a compelling approach for generating real-time MRI video of the vocal tract from speech audio. The use of a diffusion model is an interesting and effective solution to this challenging inverse problem.
One potential limitation is the reliance on paired audio-video data for training, which may be difficult to obtain in large quantities. The researchers mention plans to explore weakly-supervised or self-supervised learning approaches to address this. Additionally, the model currently generates 2D MRI videos, whereas 3D information could be even more valuable for some applications, such as speech production modeling.
Overall, the Speech2rtMRI model represents an exciting advancement in the field of speech production research and could have significant implications for both clinical and scientific applications.
Conclusion
The Speech2rtMRI paper introduces a novel speech-guided diffusion model that can generate realistic, real-time MRI video of the vocal tract from speech audio. This technology has the potential to enable new research into speech production and clinical applications for diagnosing and treating speech disorders. The use of a diffusion model to solve this inverse problem is a clever and effective approach, though the reliance on paired audio-video data for training could be a limitation. Overall, this work represents an exciting advancement in the field of speech and language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Speech2rtMRI: Speech-Guided Diffusion Model for Real-time MRI Video of the Vocal Tract during Speech
Hong Nguyen, Sean Foley, Kevin Huang, Xuan Shi, Tiantian Feng, Shrikanth Narayanan
Understanding speech production both visually and kinematically can inform second language learning system designs, as well as the creation of speaking characters in video games and animations. In this work, we introduce a data-driven method to visually represent articulator motion in Magnetic Resonance Imaging (MRI) videos of the human vocal tract during speech based on arbitrary audio or speech input. We leverage large pre-trained speech models, which are embedded with prior knowledge, to generalize the visual domain to unseen data using a speech-to-video diffusion model. Our findings demonstrate that the visual generation significantly benefits from the pre-trained speech representations. We also observed that evaluating phonemes in isolation is challenging but becomes more straightforward when assessed within the context of spoken words. Limitations of the current results include the presence of unsmooth tongue motion and video distortion when the tongue contacts the palate.
Read more9/25/2024
0
Multimodal Segmentation for Vocal Tract Modeling
Rishi Jain, Bohan Yu, Peter Wu, Tejas Prabhune, Gopala Anumanchipalli
Accurate modeling of the vocal tract is necessary to construct articulatory representations for interpretable speech processing and linguistics. However, vocal tract modeling is challenging because many internal articulators are occluded from external motion capture technologies. Real-time magnetic resonance imaging (RT-MRI) allows measuring precise movements of internal articulators during speech, but annotated datasets of MRI are limited in size due to time-consuming and computationally expensive labeling methods. We first present a deep labeling strategy for the RT-MRI video using a vision-only segmentation approach. We then introduce a multimodal algorithm using audio to improve segmentation of vocal articulators. Together, we set a new benchmark for vocal tract modeling in MRI video segmentation and use this to release labels for a 75-speaker RT-MRI dataset, increasing the amount of labeled public RT-MRI data of the vocal tract by over a factor of 9. The code and dataset labels can be found at url{rishiraij.github.io/multimodal-mri-avatar/}.
Read more6/26/2024

0
Ethics of Generating Synthetic MRI Vocal Tract Views from the Face
Muhammad Suhaib Shahid, Gleb E. Yakubov, Andrew P. French
Forming oral models capable of understanding the complete dynamics of the oral cavity is vital across research areas such as speech correction, designing foods for the aging population, and dentistry. Magnetic resonance imaging (MRI) technologies, capable of capturing oral data essential for creating such detailed representations, offer a powerful tool for illustrating articulatory dynamics. However, its real-time application is hindered by expense and expertise requirements. Ever advancing generative AI approaches present themselves as a way to address this barrier by leveraging multi-modal approaches for generating pseudo-MRI views. Nonetheless, this immediately sparks ethical concerns regarding the utilisation of a technology with the capability to produce MRIs from facial observations. This paper explores the ethical implications of external-to-internal correlation modeling (E2ICM). E2ICM utilises facial movements to infer internal configurations and provides a cost-effective supporting technology for MRI. In this preliminary work, we employ Pix2PixGAN to generate pseudo-MRI views from external articulatory data, demonstrating the feasibility of this approach. Ethical considerations concerning privacy, consent, and potential misuse, which are fundamental to our examination of this innovative methodology, are discussed as a result of this experimentation.
Read more7/12/2024
0
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
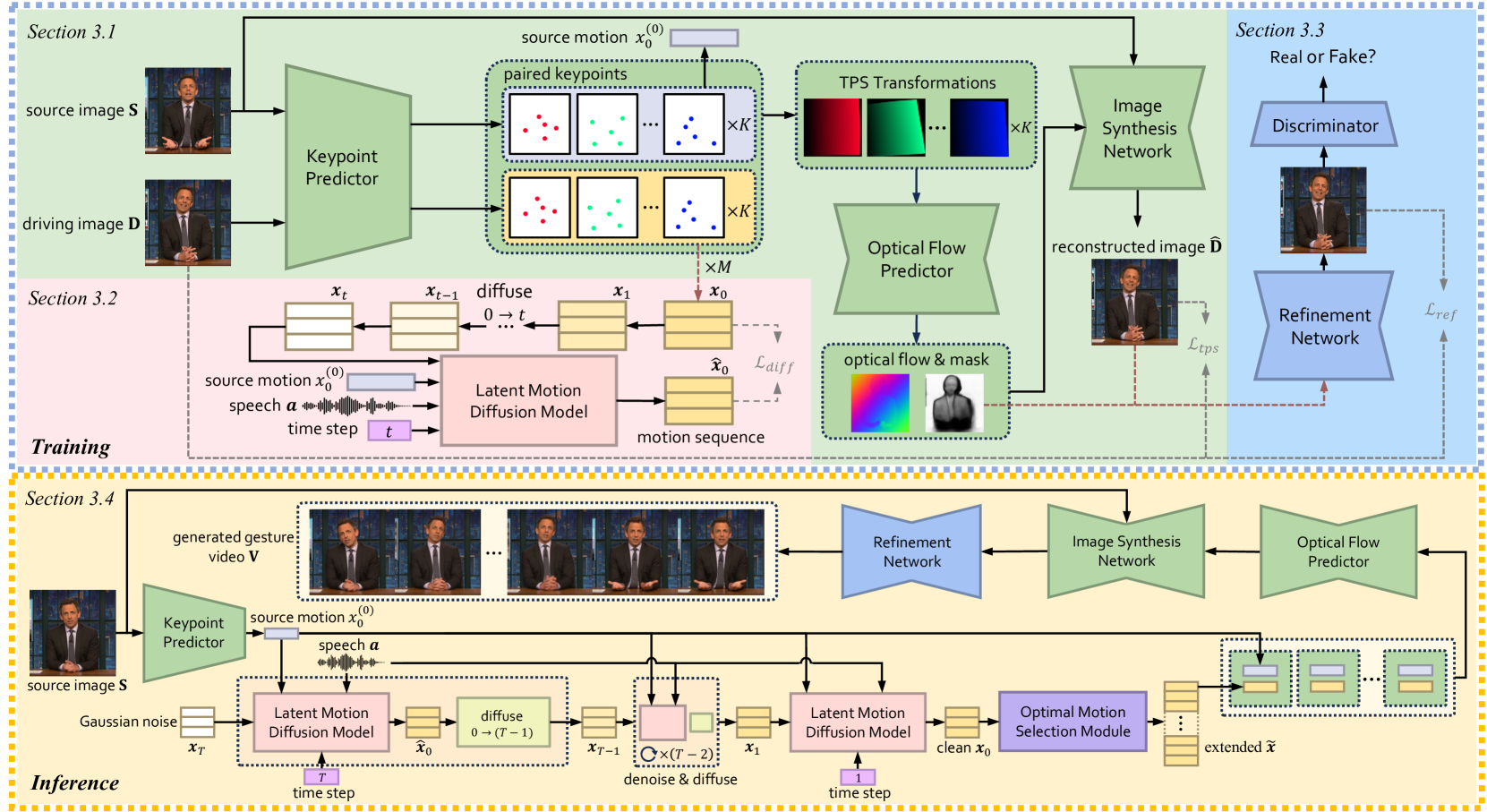
Xu He, Qiaochu Huang, Zhensong Zhang, Zhiwei Lin, Zhiyong Wu, Sicheng Yang, Minglei Li, Zhiyi Chen, Songcen Xu, Xiaofei Wu
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
Read more4/3/2024