Multimodal Segmentation for Vocal Tract Modeling

0
Sign in to get full access
Overview
- This paper presents a method for segmenting the vocal tract using multimodal data, which could improve the modeling and analysis of speech production.
- The approach integrates information from different modalities, such as audio and magnetic resonance imaging (MRI), to more accurately delineate the boundaries of the vocal tract structures.
- By leveraging complementary data sources, the researchers aim to enable more detailed and robust modeling of the human vocal system.
Plain English Explanation
The human vocal tract, which includes the mouth, throat, and nasal passages, plays a crucial role in speech production. Accurately modeling and understanding the vocal tract is important for various applications, such as speech synthesis, recognition, and clinical speech analysis.
However, segmenting the vocal tract structures from medical imaging data, such as MRI scans, can be challenging due to the complex anatomy and the limitations of a single modality. This paper explores the use of multimodal data, which combines different types of information, to improve the segmentation of the vocal tract.
The researchers hypothesize that by integrating audio data, which provides information about the acoustic properties of speech, with MRI data, which captures the physical structure of the vocal tract, they can develop a more comprehensive and accurate model of the system. [This approach could lead to advancements in areas like cross-modal cognitive consensus guided audio-visual and multimodal speech recognition for intelligent assistants in operating rooms.]
Technical Explanation
The paper presents a multimodal segmentation method that leverages both audio and MRI data to delineate the boundaries of the vocal tract structures. The approach involves:
- Data Collection: The researchers collected synchronized audio recordings and MRI scans of participants during speech tasks.
- Feature Extraction: They extracted relevant features from the audio and MRI data, such as spectral characteristics and geometric properties of the vocal tract, respectively.
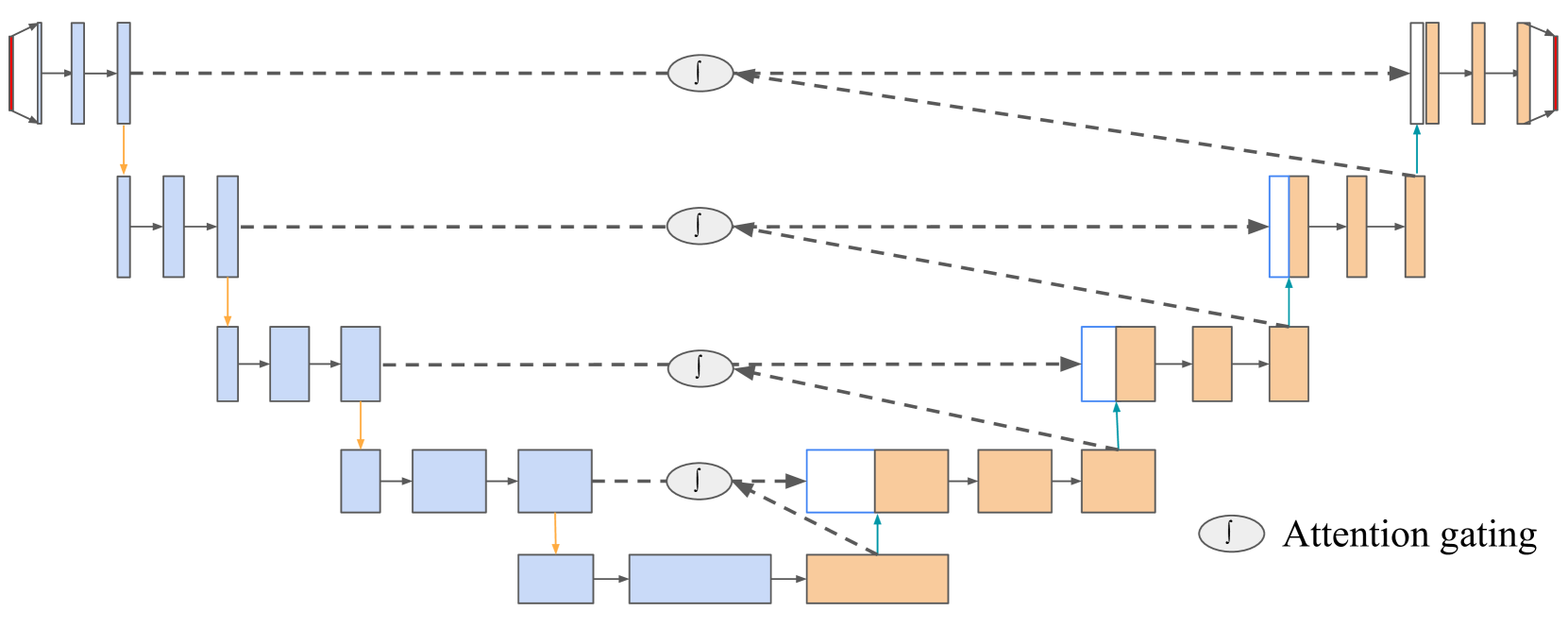
- Multimodal Integration: The extracted features were combined using a hybrid CTCRNN model to generate a unified representation of the vocal tract.
- Segmentation: The integrated multimodal features were used to segment the vocal tract structures, such as the lips, tongue, and velum, with improved accuracy compared to using a single modality.
The key innovation of this work is the seamless integration of audio and MRI data to enable more robust and detailed modeling of the vocal tract. By leveraging complementary information from different modalities, the researchers aim to overcome the limitations of relying on a single data source.
Critical Analysis
The paper presents a promising approach to vocal tract segmentation, but it also acknowledges several limitations and areas for further research:
- Limited Dataset: The study was conducted on a relatively small dataset, which may limit the generalizability of the findings. [Expanding the dataset, especially with multilingual audio-visual data, could strengthen the conclusions.](https://aimodels.fyi/papers/arxiv/language-augmentation-clip-improved-anatomy-detection-multi)
- Computational Complexity: The multimodal integration and segmentation process may be computationally intensive, which could hinder its practical application in real-time scenarios.
- Validation in Clinical Settings: The researchers should further evaluate the method's performance and robustness in clinical applications, such as speech therapy or surgical planning.
Overall, the presented multimodal segmentation approach shows promise in improving the modeling and analysis of the human vocal tract. However, additional research is needed to address the identified limitations and explore the broader implications of this work.
Conclusion
This paper introduces a novel method for segmenting the vocal tract using multimodal data, combining audio and MRI information. By integrating complementary data sources, the researchers aim to enable more accurate and comprehensive modeling of the human speech production system.
The proposed approach has the potential to advance various fields, such as speech synthesis, recognition, and clinical speech analysis. [Further development and validation of this technique could contribute to the broader goal of creating more intelligent and effective speech assistants that can better understand and respond to human speech.](https://aimodels.fyi/papers/arxiv/voice-ehr-introducing-multimodal-audio-data-health)
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Segmentation for Vocal Tract Modeling
Rishi Jain, Bohan Yu, Peter Wu, Tejas Prabhune, Gopala Anumanchipalli
Accurate modeling of the vocal tract is necessary to construct articulatory representations for interpretable speech processing and linguistics. However, vocal tract modeling is challenging because many internal articulators are occluded from external motion capture technologies. Real-time magnetic resonance imaging (RT-MRI) allows measuring precise movements of internal articulators during speech, but annotated datasets of MRI are limited in size due to time-consuming and computationally expensive labeling methods. We first present a deep labeling strategy for the RT-MRI video using a vision-only segmentation approach. We then introduce a multimodal algorithm using audio to improve segmentation of vocal articulators. Together, we set a new benchmark for vocal tract modeling in MRI video segmentation and use this to release labels for a 75-speaker RT-MRI dataset, increasing the amount of labeled public RT-MRI data of the vocal tract by over a factor of 9. The code and dataset labels can be found at url{rishiraij.github.io/multimodal-mri-avatar/}.
Read more6/26/2024

0
Speech2rtMRI: Speech-Guided Diffusion Model for Real-time MRI Video of the Vocal Tract during Speech
Hong Nguyen, Sean Foley, Kevin Huang, Xuan Shi, Tiantian Feng, Shrikanth Narayanan
Understanding speech production both visually and kinematically can inform second language learning system designs, as well as the creation of speaking characters in video games and animations. In this work, we introduce a data-driven method to visually represent articulator motion in Magnetic Resonance Imaging (MRI) videos of the human vocal tract during speech based on arbitrary audio or speech input. We leverage large pre-trained speech models, which are embedded with prior knowledge, to generalize the visual domain to unseen data using a speech-to-video diffusion model. Our findings demonstrate that the visual generation significantly benefits from the pre-trained speech representations. We also observed that evaluating phonemes in isolation is challenging but becomes more straightforward when assessed within the context of spoken words. Limitations of the current results include the presence of unsmooth tongue motion and video distortion when the tongue contacts the palate.
Read more9/25/2024

0
Integrating Audio, Visual, and Semantic Information for Enhanced Multimodal Speaker Diarization
Luyao Cheng, Hui Wang, Siqi Zheng, Yafeng Chen, Rongjie Huang, Qinglin Zhang, Qian Chen, Xihao Li
Speaker diarization, the process of segmenting an audio stream or transcribed speech content into homogenous partitions based on speaker identity, plays a crucial role in the interpretation and analysis of human speech. Most existing speaker diarization systems rely exclusively on unimodal acoustic information, making the task particularly challenging due to the innate ambiguities of audio signals. Recent studies have made tremendous efforts towards audio-visual or audio-semantic modeling to enhance performance. However, even the incorporation of up to two modalities often falls short in addressing the complexities of spontaneous and unstructured conversations. To exploit more meaningful dialogue patterns, we propose a novel multimodal approach that jointly utilizes audio, visual, and semantic cues to enhance speaker diarization. Our method elegantly formulates the multimodal modeling as a constrained optimization problem. First, we build insights into the visual connections among active speakers and the semantic interactions within spoken content, thereby establishing abundant pairwise constraints. Then we introduce a joint pairwise constraint propagation algorithm to cluster speakers based on these visual and semantic constraints. This integration effectively leverages the complementary strengths of different modalities, refining the affinity estimation between individual speaker embeddings. Extensive experiments conducted on multiple multimodal datasets demonstrate that our approach consistently outperforms state-of-the-art speaker diarization methods.
Read more8/23/2024

0
Multimodal Laryngoscopic Video Analysis for Assisted Diagnosis of Vocal Cord Paralysis
Yucong Zhang, Xin Zou, Jinshan Yang, Wenjun Chen, Faya Liang, Ming Li
This paper presents the Multimodal Analyzing System for Laryngoscope (MASL), a system that combines audio and video data to automatically extract key segments and metrics from laryngeal videostroboscopic videos for clinical assessment. MASL integrates glottis detection with keyword spotting to analyze patient vocalizations and refine video highlights for better inspection of vocal cord movements. The system includes a strobing video extraction module that identifies frames by analyzing hue, saturation, and value fluctuations. MASL also provides effective metrics for vocal cord paralysis detection, employing a two-stage glottis segmentation process using U-Net followed by diffusion-based refinement to reduce false positives. Instead of glottal area waveforms, MASL estimates anterior glottic angle waveforms (AGAW) from glottis masks, evaluating both left and right vocal cords to detect unilateral vocal cord paralysis (UVFP). By comparing AGAW variances, MASL distinguishes between left and right paralysis. Ablation studies and experiments on public and real-world datasets validate MASL's segmentation module and demonstrate its ability to provide reliable metrics for UVFP diagnosis.
Read more9/6/2024