Evaluating ChatGPT as a Recommender System: A Rigorous Approach

0
🤿
Sign in to get full access
Overview
- Large language models (LLMs) like ChatGPT have shown impressive abilities in various natural language tasks.
- Current studies have assessed ChatGPT's superior performance, especially under zero/few-shot prompting conditions.
- The Recommender Systems (RSs) research community is investigating ChatGPT's potential applications in recommendation scenarios.
- However, current research struggles to comprehensively evaluate such models while considering the peculiarities of generative models.
- The evaluation often neglects the impact on beyond-accuracy facets, such as hallucinations, duplications, and out-of-the-closed domain recommendations.
Plain English Explanation
Large language models (LLMs) like ChatGPT have made significant progress in understanding and generating human-like text. Researchers have found that ChatGPT, in particular, performs very well on a wide range of tasks, even when provided with just a few examples or no examples at all (known as zero-shot or few-shot learning).
Given ChatGPT's impressive capabilities, the Recommender Systems (RS) research community has started exploring how to integrate this technology into recommendation systems. Recommendation systems are algorithms that suggest products, services, or content to users based on their preferences and behaviors.
However, the researchers have found that the current methods for evaluating ChatGPT and other LLMs in recommendation tasks are not comprehensive enough. They often focus solely on accuracy metrics, without considering the potential issues that can arise from using generative models, such as hallucinations (generating false information), duplications, and recommending items that are outside the model's intended domain.
To address this gap, the researchers propose a robust evaluation pipeline that can better assess ChatGPT's performance as a recommender system and account for these beyond-accuracy factors.
Technical Explanation
The researchers propose a comprehensive evaluation pipeline to assess ChatGPT's performance in recommendation tasks. They investigate ChatGPT-3.5 and ChatGPT-4 under the zero-shot condition, using a role-playing prompt to simulate the recommendation scenario.
The evaluation is conducted in three settings:
- Top-N Recommendation: Evaluating ChatGPT's ability to generate a list of the top N recommended items.
- Cold-start Recommendation: Assessing ChatGPT's performance in recommending items for new users with limited information.
- Re-ranking: Measuring ChatGPT's effectiveness in re-ranking a list of recommended items.
The experiments are carried out across three domains: movies, music, and books. The researchers analyze the model's accuracy as well as beyond-accuracy metrics, such as hallucinations, duplications, and out-of-domain recommendations.
The results reveal that ChatGPT exhibits higher accuracy than the baselines on the books domain. It also excels in re-ranking and cold-start scenarios while maintaining reasonable beyond-accuracy metrics. Additionally, the researchers measure the similarity between ChatGPT's recommendations and those of other recommender systems, providing insights into how ChatGPT can be categorized in the realm of recommender systems.
The evaluation pipeline developed by the researchers is publicly released for future research, enabling the community to further investigate the potential and limitations of using large language models like ChatGPT in recommendation tasks.
Critical Analysis
The researchers' approach to evaluating ChatGPT's performance as a recommender system is commendable, as it addresses the limitations of previous studies that focused solely on accuracy metrics. By considering beyond-accuracy factors, such as hallucinations, duplications, and out-of-domain recommendations, the researchers provide a more comprehensive assessment of ChatGPT's suitability for recommendation tasks.
However, the study is limited to the zero-shot condition, and it would be interesting to see how ChatGPT's performance compares when provided with more training data or fine-tuned on specific recommendation datasets. Additionally, the researchers only evaluate ChatGPT-3.5 and ChatGPT-4, and it would be valuable to assess the performance of other large language models, such as GPT-3 or RecGPT, to better understand the state of the art in this domain.
Furthermore, while the researchers provide insights into how ChatGPT's recommendations compare to those of other recommender systems, it would be interesting to explore the specific strengths and weaknesses of ChatGPT-based recommendations compared to traditional recommendation algorithms. This could help researchers and practitioners determine the best scenarios for deploying ChatGPT-based recommender systems.
Overall, the researchers' work represents an important step forward in evaluating the potential and limitations of using large language models like ChatGPT in recommendation tasks. The publicly released evaluation pipeline will undoubtedly be a valuable resource for future research in this area.
Conclusion
The study proposed a robust evaluation pipeline to assess ChatGPT's performance as a recommender system, addressing the limitations of previous research that focused solely on accuracy metrics. The experiments revealed that ChatGPT exhibits higher accuracy than baselines on the books domain and excels in re-ranking and cold-start scenarios, while maintaining reasonable beyond-accuracy metrics.
The researchers' work provides valuable insights into the potential and challenges of using large language models like ChatGPT in recommendation tasks. The publicly released evaluation pipeline will enable the research community to further explore the integration of these powerful language models into recommender systems, ultimately leading to more effective and user-friendly recommendation experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Evaluating ChatGPT as a Recommender System: A Rigorous Approach
Dario Di Palma, Giovanni Maria Biancofiore, Vito Walter Anelli, Fedelucio Narducci, Tommaso Di Noia, Eugenio Di Sciascio
Large Language Models (LLMs) have recently shown impressive abilities in handling various natural language-related tasks. Among different LLMs, current studies have assessed ChatGPT's superior performance across manifold tasks, especially under the zero/few-shot prompting conditions. Given such successes, the Recommender Systems (RSs) research community have started investigating its potential applications within the recommendation scenario. However, although various methods have been proposed to integrate ChatGPT's capabilities into RSs, current research struggles to comprehensively evaluate such models while considering the peculiarities of generative models. Often, evaluations do not consider hallucinations, duplications, and out-of-the-closed domain recommendations and solely focus on accuracy metrics, neglecting the impact on beyond-accuracy facets. To bridge this gap, we propose a robust evaluation pipeline to assess ChatGPT's ability as an RS and post-process ChatGPT recommendations to account for these aspects. Through this pipeline, we investigate ChatGPT-3.5 and ChatGPT-4 performance in the recommendation task under the zero-shot condition employing the role-playing prompt. We analyze the model's functionality in three settings: the Top-N Recommendation, the cold-start recommendation, and the re-ranking of a list of recommendations, and in three domains: movies, music, and books. The experiments reveal that ChatGPT exhibits higher accuracy than the baselines on books domain. It also excels in re-ranking and cold-start scenarios while maintaining reasonable beyond-accuracy metrics. Furthermore, we measure the similarity between the ChatGPT recommendations and the other recommenders, providing insights about how ChatGPT could be categorized in the realm of recommender systems. The evaluation pipeline is publicly released for future research.
Read more6/5/2024
🎲
0
Can we trust the evaluation on ChatGPT?
Rachith Aiyappa, Jisun An, Haewoon Kwak, Yong-Yeol Ahn
ChatGPT, the first large language model (LLM) with mass adoption, has demonstrated remarkable performance in numerous natural language tasks. Despite its evident usefulness, evaluating ChatGPT's performance in diverse problem domains remains challenging due to the closed nature of the model and its continuous updates via Reinforcement Learning from Human Feedback (RLHF). We highlight the issue of data contamination in ChatGPT evaluations, with a case study of the task of stance detection. We discuss the challenge of preventing data contamination and ensuring fair model evaluation in the age of closed and continuously trained models.
Read more8/23/2024
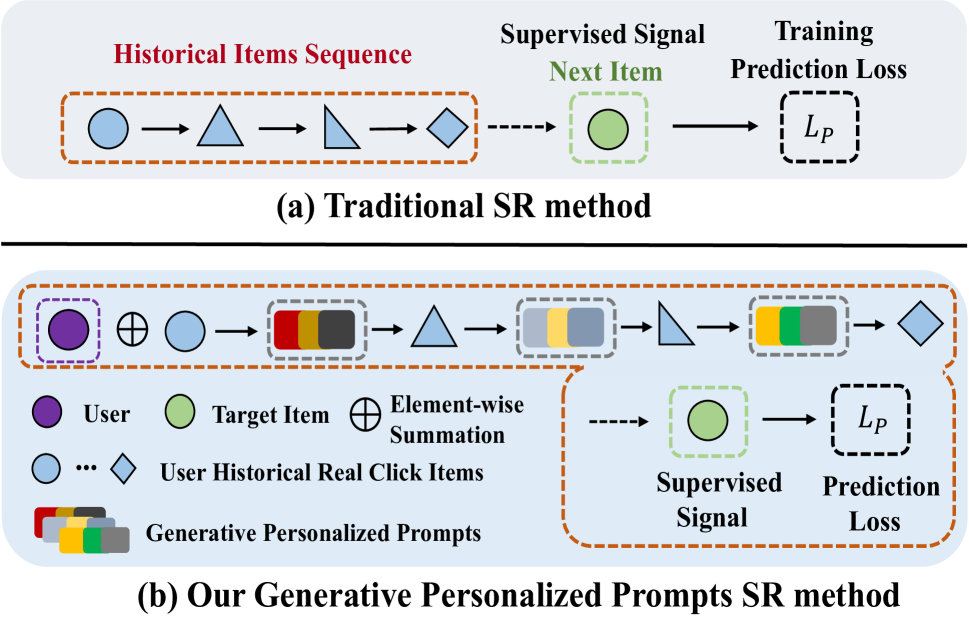
0
RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm
Yabin Zhang, Wenhui Yu, Erhan Zhang, Xu Chen, Lantao Hu, Peng Jiang, Kun Gai
ChatGPT has achieved remarkable success in natural language understanding. Considering that recommendation is indeed a conversation between users and the system with items as words, which has similar underlying pattern with ChatGPT, we design a new chat framework in item index level for the recommendation task. Our novelty mainly contains three parts: model, training and inference. For the model part, we adopt Generative Pre-training Transformer (GPT) as the sequential recommendation model and design a user modular to capture personalized information. For the training part, we adopt the two-stage paradigm of ChatGPT, including pre-training and fine-tuning. In the pre-training stage, we train GPT model by auto-regression. In the fine-tuning stage, we train the model with prompts, which include both the newly-generated results from the model and the user's feedback. For the inference part, we predict several user interests as user representations in an autoregressive manner. For each interest vector, we recall several items with the highest similarity and merge the items recalled by all interest vectors into the final result. We conduct experiments with both offline public datasets and online A/B test to demonstrate the effectiveness of our proposed method.
Read more4/16/2024
⚙️
0
Navigating User Experience of ChatGPT-based Conversational Recommender Systems: The Effects of Prompt Guidance and Recommendation Domain
Yizhe Zhang, Yucheng Jin, Li Chen, Ting Yang
Conversational recommender systems (CRS) enable users to articulate their preferences and provide feedback through natural language. With the advent of large language models (LLMs), the potential to enhance user engagement with CRS and augment the recommendation process with LLM-generated content has received increasing attention. However, the efficacy of LLM-powered CRS is contingent upon the use of prompts, and the subjective perception of recommendation quality can differ across various recommendation domains. Therefore, we have developed a ChatGPT-based CRS to investigate the impact of these two factors, prompt guidance (PG) and recommendation domain (RD), on the overall user experience of the system. We conducted an online empirical study (N = 100) by employing a mixed-method approach that utilized a between-subjects design for the variable of PG (with vs. without) and a within-subjects design for RD (book recommendations vs. job recommendations). The findings reveal that PG can substantially enhance the system's explainability, adaptability, perceived ease of use, and transparency. Moreover, users are inclined to perceive a greater sense of novelty and demonstrate a higher propensity to engage with and try recommended items in the context of book recommendations as opposed to job recommendations. Furthermore, the influence of PG on certain user experience metrics and interactive behaviors appears to be modulated by the recommendation domain, as evidenced by the interaction effects between the two examined factors. This work contributes to the user-centered evaluation of ChatGPT-based CRS by investigating two prominent factors and offers practical design guidance.
Read more5/24/2024