Evaluating and Enhancing Large Language Models for Novelty Assessment in Scholarly Publications

0

Sign in to get full access
Overview
- Evaluates and enhances large language models for assessing the novelty of scholarly publications
- Focuses on using language models to identify novel aspects in research papers
- Proposes methods to improve the performance of language models for this task
Plain English Explanation
This research paper explores ways to use large language models, which are advanced AI systems trained on massive amounts of text data, to assess the novelty of scholarly publications. The key idea is that language models can be leveraged to identify novel concepts, ideas, or methodologies presented in research papers.
The researchers first evaluate the performance of existing language models on the task of novelty assessment. They find that while these models can provide some insights, their accuracy is limited. To address this, the researchers propose several enhancements to the language models, such as fine-tuning them on relevant datasets and incorporating domain-specific knowledge.
These enhancements are designed to help the language models better understand the nuances of scholarly writing and more effectively identify novel contributions within research papers. The researchers then evaluate the performance of the enhanced models and demonstrate significant improvements in their ability to assess novelty compared to the original language models.
The potential applications of this work include improving literature review processes, assisting researchers in identifying promising research directions, and automating parts of the peer review process. By leveraging advanced language models, this research aims to enhance the way we navigate and make sense of the rapidly growing body of scholarly literature.
Technical Explanation
The researchers begin by evaluating the performance of several large language models on the task of novelty assessment in scholarly publications. They use a dataset of research papers and annotations of novel content to assess the models' ability to identify novel aspects in the papers.
To enhance the language models' performance, the researchers propose two key strategies:
-
Fine-tuning the language models on a dataset of scholarly publications: This allows the models to better understand the language and conventions of academic writing, improving their ability to identify novel contributions.
-
Incorporating domain-specific knowledge into the language models: The researchers explore ways to imbue the models with relevant background information, such as key concepts, techniques, and trends in the research field, to aid in novelty detection.
The researchers evaluate the enhanced language models on the same dataset used for the initial assessment. Their results demonstrate significant improvements in the models' ability to accurately identify novel content in research papers compared to the original language models.
Critical Analysis
The researchers acknowledge several limitations of their work, such as the reliance on a single dataset for evaluation and the potential for bias in the ground truth annotations of novel content. They also note that further research is needed to explore the generalizability of their approaches to different domains and types of scholarly publications.
Additionally, while the proposed enhancements do improve the language models' performance, there may still be challenges in accurately capturing the nuances of novelty in academic writing. Novelty can be a complex and subjective concept, and further advancements in natural language understanding may be required to fully address this challenge.
Conclusion
This research demonstrates the potential of leveraging large language models to enhance the assessment of novelty in scholarly publications. By fine-tuning and incorporating domain-specific knowledge, the researchers have shown significant improvements in the models' ability to identify novel aspects in research papers.
The implications of this work include streamlining literature review processes, assisting researchers in identifying promising research directions, and potentially automating parts of the peer review process. As the volume of scholarly literature continues to grow, tools that can effectively navigate and make sense of this information will become increasingly valuable for the research community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating and Enhancing Large Language Models for Novelty Assessment in Scholarly Publications
Ethan Lin, Zhiyuan Peng, Yi Fang
Recent studies have evaluated the creativity/novelty of large language models (LLMs) primarily from a semantic perspective, using benchmarks from cognitive science. However, accessing the novelty in scholarly publications is a largely unexplored area in evaluating LLMs. In this paper, we introduce a scholarly novelty benchmark (SchNovel) to evaluate LLMs' ability to assess novelty in scholarly papers. SchNovel consists of 15000 pairs of papers across six fields sampled from the arXiv dataset with publication dates spanning 2 to 10 years apart. In each pair, the more recently published paper is assumed to be more novel. Additionally, we propose RAG-Novelty, which simulates the review process taken by human reviewers by leveraging the retrieval of similar papers to assess novelty. Extensive experiments provide insights into the capabilities of different LLMs to assess novelty and demonstrate that RAG-Novelty outperforms recent baseline models.
Read more9/26/2024

0
Leveraging Large Language Models for NLG Evaluation: Advances and Challenges
Zhen Li, Xiaohan Xu, Tao Shen, Can Xu, Jia-Chen Gu, Yuxuan Lai, Chongyang Tao, Shuai Ma
In the rapidly evolving domain of Natural Language Generation (NLG) evaluation, introducing Large Language Models (LLMs) has opened new avenues for assessing generated content quality, e.g., coherence, creativity, and context relevance. This paper aims to provide a thorough overview of leveraging LLMs for NLG evaluation, a burgeoning area that lacks a systematic analysis. We propose a coherent taxonomy for organizing existing LLM-based evaluation metrics, offering a structured framework to understand and compare these methods. Our detailed exploration includes critically assessing various LLM-based methodologies, as well as comparing their strengths and limitations in evaluating NLG outputs. By discussing unresolved challenges, including bias, robustness, domain-specificity, and unified evaluation, this paper seeks to offer insights to researchers and advocate for fairer and more advanced NLG evaluation techniques.
Read more6/13/2024

0
Can Large Language Models Unlock Novel Scientific Research Ideas?
Sandeep Kumar, Tirthankar Ghosal, Vinayak Goyal, Asif Ekbal
An idea is nothing more nor less than a new combination of old elements (Young, J.W.). The widespread adoption of Large Language Models (LLMs) and publicly available ChatGPT have marked a significant turning point in the integration of Artificial Intelligence (AI) into people's everyday lives. This study explores the capability of LLMs in generating novel research ideas based on information from research papers. We conduct a thorough examination of 4 LLMs in five domains (e.g., Chemistry, Computer, Economics, Medical, and Physics). We found that the future research ideas generated by Claude-2 and GPT-4 are more aligned with the author's perspective than GPT-3.5 and Gemini. We also found that Claude-2 generates more diverse future research ideas than GPT-4, GPT-3.5, and Gemini 1.0. We further performed a human evaluation of the novelty, relevancy, and feasibility of the generated future research ideas. This investigation offers insights into the evolving role of LLMs in idea generation, highlighting both its capability and limitations. Our work contributes to the ongoing efforts in evaluating and utilizing language models for generating future research ideas. We make our datasets and codes publicly available.
Read more9/11/2024
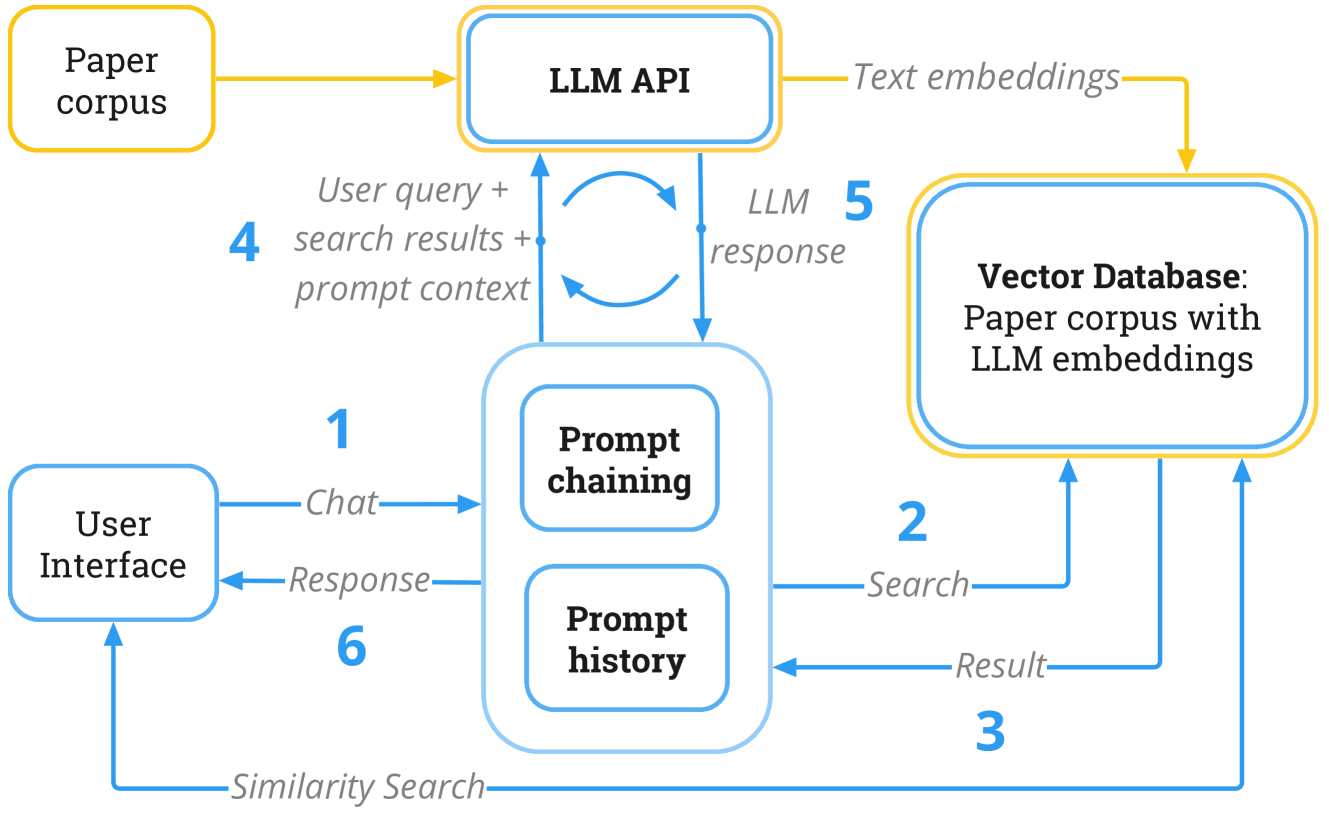
0
vitaLITy 2: Reviewing Academic Literature Using Large Language Models
Hongye An, Arpit Narechania, Emily Wall, Kai Xu
Academic literature reviews have traditionally relied on techniques such as keyword searches and accumulation of relevant back-references, using databases like Google Scholar or IEEEXplore. However, both the precision and accuracy of these search techniques is limited by the presence or absence of specific keywords, making literature review akin to searching for needles in a haystack. We present vitaLITy 2, a solution that uses a Large Language Model or LLM-based approach to identify semantically relevant literature in a textual embedding space. We include a corpus of 66,692 papers from 1970-2023 which are searchable through text embeddings created by three language models. vitaLITy 2 contributes a novel Retrieval Augmented Generation (RAG) architecture and can be interacted with through an LLM with augmented prompts, including summarization of a collection of papers. vitaLITy 2 also provides a chat interface that allow users to perform complex queries without learning any new programming language. This also enables users to take advantage of the knowledge captured in the LLM from its enormous training corpus. Finally, we demonstrate the applicability of vitaLITy 2 through two usage scenarios. vitaLITy 2 is available as open-source software at https://vitality-vis.github.io.
Read more8/27/2024