Evaluating Human Alignment and Model Faithfulness of LLM Rationale

0

Sign in to get full access
Overview
- This paper evaluates the alignment between human-written and model-generated rationales for language model decisions.
- The researchers examined whether large language models (LLMs) can generate rationales that are faithful to their own decision-making process and aligned with human rationales.
- They conducted experiments to assess the perceived human alignment and model faithfulness of LLM-generated rationales across a range of tasks.
Plain English Explanation
The paper explores whether the reasons (or "rationales") that large language models (LLMs) give for their decisions are actually aligned with how humans would explain those decisions. The researchers wanted to see if the rationales generated by LLMs are faithfully representing the model's own internal reasoning, or if they are just producing plausible-sounding explanations that may not match the true decision-making process.
To investigate this, the researchers had LLMs generate rationales for their decisions on various tasks, and then compared those rationales to the explanations that humans would give for the same decisions. They looked at factors like whether the LLM rationales were perceived as aligned with human reasoning, and whether the LLM rationales accurately reflected the model's own internal logic.
By evaluating the alignment between human-written and model-generated rationales, the researchers aimed to shed light on the interpretability and trustworthiness of LLM decision-making. This is an important issue as these powerful language models become more widely deployed in high-stakes applications.
Technical Explanation
The paper first reviews relevant prior work on evaluating the faithfulness and human alignment of LLM-generated rationales. It also discusses studies on the persuasiveness of generated free-text rationales and the reasoning capabilities of large language models.
The researchers conducted a series of experiments to evaluate the human alignment and model faithfulness of LLM rationales. They first had humans provide rationales for various tasks, then had LLMs generate their own rationales for the same tasks. They then had human evaluators assess the alignment between the human-written and model-generated rationales, as well as the faithfulness of the LLM rationales to the model's own decision-making process.
The paper also examines the impact of readability constraints on the quality of LLM-generated rationales. Additionally, it explores the use of prompt engineering techniques to improve the faithfulness of LLM rationales.
Critical Analysis
The paper provides a thorough and nuanced evaluation of LLM rationale generation, highlighting both the promise and the limitations of current approaches. The researchers acknowledge that while LLMs can generate plausible-sounding rationales, these may not always accurately reflect the model's true decision-making process.
One potential limitation is the reliance on human evaluations of alignment, which could be influenced by biases or preconceptions. The researchers note that further work is needed to develop more objective metrics for assessing model faithfulness.
Additionally, the paper focuses primarily on textual rationales, but LLMs could also potentially generate visual or multimodal explanations, which were not explored in this study. Extending the evaluation to these other modalities could provide a more comprehensive understanding of LLM interpretability.
Overall, this paper makes an important contribution to the ongoing discussion around the transparency and trustworthiness of large language models. The findings highlight the need for continued research and development in this critical area as LLMs become more widely deployed in high-impact applications.
Conclusion
This paper presents a comprehensive evaluation of the alignment between human-written and model-generated rationales for language model decisions. The researchers found that while LLMs can generate plausible-sounding rationales, these may not always faithfully reflect the model's true decision-making process.
The findings underscore the importance of developing techniques to improve the interpretability and transparency of LLMs, particularly as they are increasingly used in high-stakes applications. The paper lays the groundwork for further research on objective metrics and modalities for evaluating model faithfulness, with the ultimate goal of building more trustworthy and accountable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating Human Alignment and Model Faithfulness of LLM Rationale
Mohsen Fayyaz, Fan Yin, Jiao Sun, Nanyun Peng
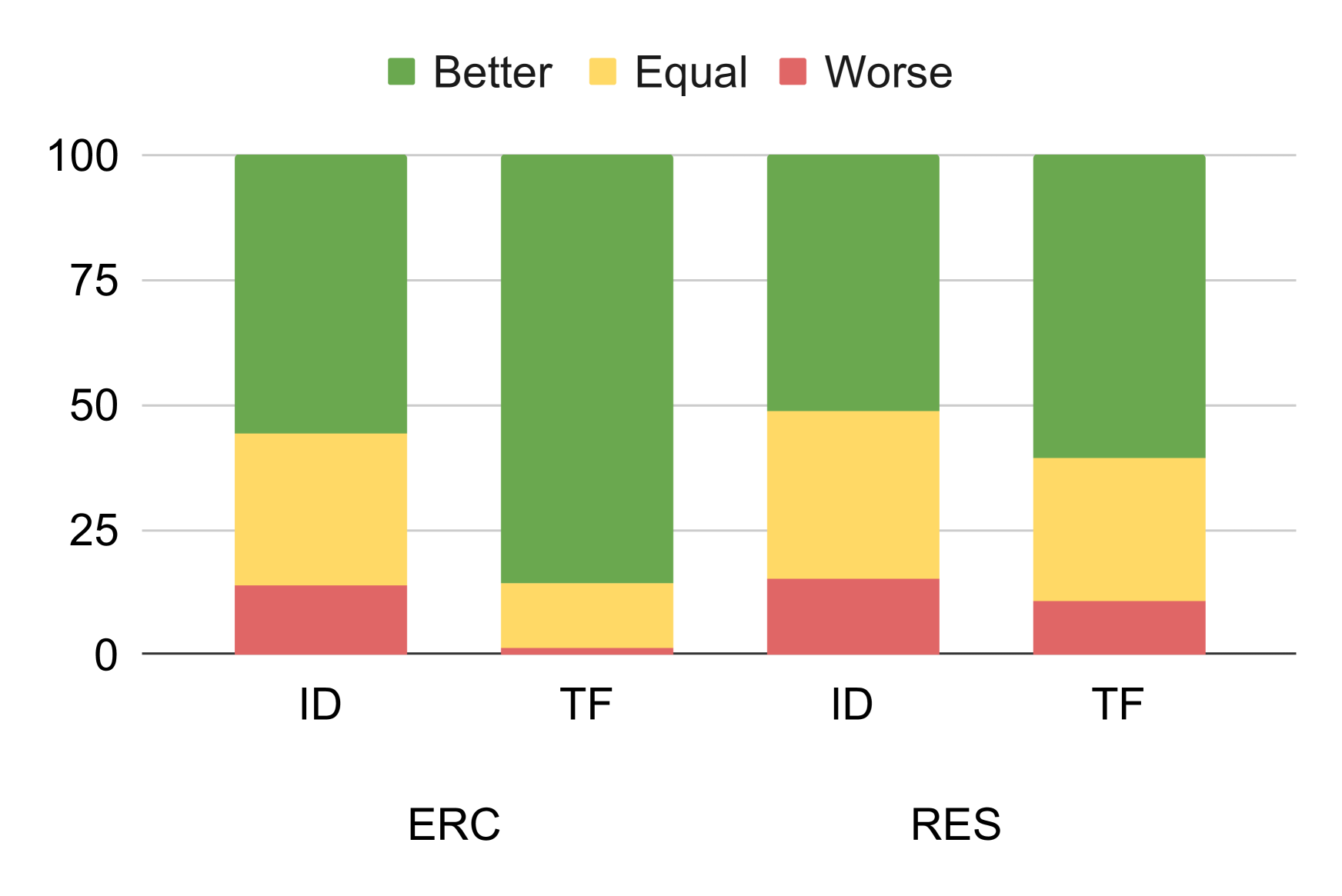
We study how well large language models (LLMs) explain their generations with rationales -- a set of tokens extracted from the input texts that reflect the decision process of LLMs. We examine LLM rationales extracted with two methods: 1) attribution-based methods that use attention or gradients to locate important tokens, and 2) prompting-based methods that guide LLMs to extract rationales using prompts. Through extensive experiments, we show that prompting-based rationales align better with human-annotated rationales than attribution-based rationales, and demonstrate reasonable alignment with humans even when model performance is poor. We additionally find that the faithfulness limitations of prompting-based methods, which are identified in previous work, may be linked to their collapsed predictions. By fine-tuning these models on the corresponding datasets, both prompting and attribution methods demonstrate improved faithfulness. Our study sheds light on more rigorous and fair evaluations of LLM rationales, especially for prompting-based ones.
Read more7/2/2024
0
Leveraging Machine-Generated Rationales to Facilitate Social Meaning Detection in Conversations
Ritam Dutt, Zhen Wu, Kelly Shi, Divyanshu Sheth, Prakhar Gupta, Carolyn Penstein Rose
We present a generalizable classification approach that leverages Large Language Models (LLMs) to facilitate the detection of implicitly encoded social meaning in conversations. We design a multi-faceted prompt to extract a textual explanation of the reasoning that connects visible cues to underlying social meanings. These extracted explanations or rationales serve as augmentations to the conversational text to facilitate dialogue understanding and transfer. Our empirical results over 2,340 experimental settings demonstrate the significant positive impact of adding these rationales. Our findings hold true for in-domain classification, zero-shot, and few-shot domain transfer for two different social meaning detection tasks, each spanning two different corpora.
Read more7/1/2024
0
Persuasiveness of Generated Free-Text Rationales in Subjective Decisions: A Case Study on Pairwise Argument Ranking
Mohamed Elaraby, Diane Litman, Xiang Lorraine Li, Ahmed Magooda
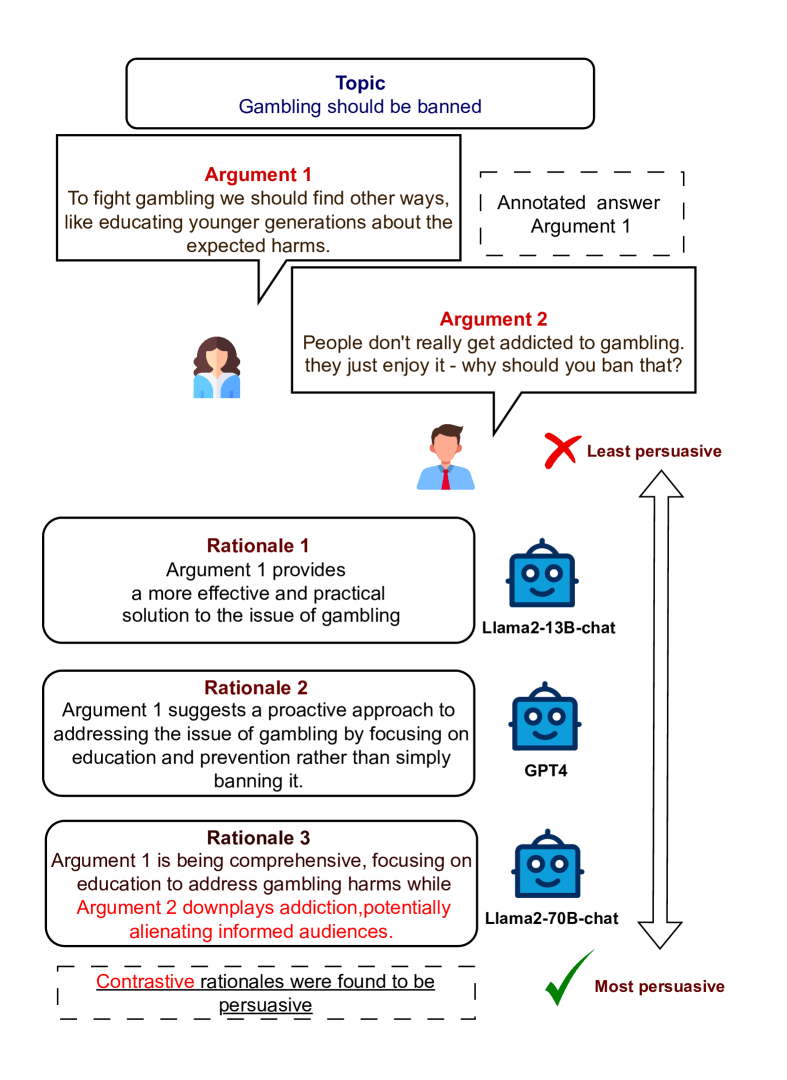
Generating free-text rationales is among the emergent capabilities of Large Language Models (LLMs). These rationales have been found to enhance LLM performance across various NLP tasks. Recently, there has been growing interest in using these rationales to provide insights for various important downstream tasks. In this paper, we analyze generated free-text rationales in tasks with subjective answers, emphasizing the importance of rationalization in such scenarios. We focus on pairwise argument ranking, a highly subjective task with significant potential for real-world applications, such as debate assistance. We evaluate the persuasiveness of rationales generated by nine LLMs to support their subjective choices. Our findings suggest that open-source LLMs, particularly Llama2-70B-chat, are capable of providing highly persuasive rationalizations, surpassing even GPT models. Additionally, our experiments show that rationale persuasiveness can be improved by controlling its parameters through prompting or through self-refinement.
Read more6/21/2024

0
Beyond Labels: Aligning Large Language Models with Human-like Reasoning
Muhammad Rafsan Kabir, Rafeed Mohammad Sultan, Ihsanul Haque Asif, Jawad Ibn Ahad, Fuad Rahman, Mohammad Ruhul Amin, Nabeel Mohammed, Shafin Rahman
Aligning large language models (LLMs) with a human reasoning approach ensures that LLMs produce morally correct and human-like decisions. Ethical concerns are raised because current models are prone to generating false positives and providing malicious responses. To contribute to this issue, we have curated an ethics dataset named Dataset for Aligning Reasons (DFAR), designed to aid in aligning language models to generate human-like reasons. The dataset comprises statements with ethical-unethical labels and their corresponding reasons. In this study, we employed a unique and novel fine-tuning approach that utilizes ethics labels and their corresponding reasons (L+R), in contrast to the existing fine-tuning approach that only uses labels (L). The original pre-trained versions, the existing fine-tuned versions, and our proposed fine-tuned versions of LLMs were then evaluated on an ethical-unethical classification task and a reason-generation task. Our proposed fine-tuning strategy notably outperforms the others in both tasks, achieving significantly higher accuracy scores in the classification task and lower misalignment rates in the reason-generation task. The increase in classification accuracies and decrease in misalignment rates indicate that the L+R fine-tuned models align more with human ethics. Hence, this study illustrates that injecting reasons has substantially improved the alignment of LLMs, resulting in more human-like responses. We have made the DFAR dataset and corresponding codes publicly available at https://github.com/apurba-nsu-rnd-lab/DFAR.
Read more8/23/2024