Large Language Models are Clinical Reasoners: Reasoning-Aware Diagnosis Framework with Prompt-Generated Rationales
2312.07399
0
0

Abstract
Machine reasoning has made great progress in recent years owing to large language models (LLMs). In the clinical domain, however, most NLP-driven projects mainly focus on clinical classification or reading comprehension, and under-explore clinical reasoning for disease diagnosis due to the expensive rationale annotation with clinicians. In this work, we present a reasoning-aware diagnosis framework that rationalizes the diagnostic process via prompt-based learning in a time- and labor-efficient manner, and learns to reason over the prompt-generated rationales. Specifically, we address the clinical reasoning for disease diagnosis, where the LLM generates diagnostic rationales providing its insight on presented patient data and the reasoning path towards the diagnosis, namely Clinical Chain-of-Thought (Clinical CoT). We empirically demonstrate LLMs/LMs' ability of clinical reasoning via extensive experiments and analyses on both rationale generation and disease diagnosis in various settings. We further propose a novel set of criteria for evaluating machine-generated rationales' potential for real-world clinical settings, facilitating and benefiting future research in this area.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) as clinical reasoners, proposing a framework for reasoning-aware disease diagnosis with prompt-generated rationales.
- The researchers investigate the ability of LLMs to engage in clinical reasoning and provide explanations for their diagnostic decisions.
- The framework involves prompting the LLM to generate a diagnosis and then asking it to explain its reasoning, with the goal of improving transparency and trust in the model's outputs.
Plain English Explanation
Large language models (LLMs) are artificial intelligence systems that can understand and generate human-like text. In this paper, the researchers explore how these powerful models can be used to help with medical diagnosis.
The key idea is to use LLMs as "clinical reasoners" - systems that can analyze a patient's symptoms and medical history, and then provide a diagnosis along with an explanation of their reasoning. This is important because doctors often need to understand the reasoning behind a diagnosis, not just the final conclusion, in order to trust and act on it.
The researchers developed a framework that prompts the LLM to first provide a diagnosis, and then to explain its reasoning for that diagnosis. By generating these explanatory "rationales," the LLM can make its decision-making process more transparent and understandable to human users.
This approach could be valuable in healthcare, where accurate and explainable diagnoses are crucial. If LLMs can be trained to reason about medical conditions in a way that aligns with human clinical expertise, they could potentially assist doctors and other healthcare providers in making more informed and trustworthy decisions.
Technical Explanation
The researchers propose a Reasoning-Aware Diagnosis Framework that leverages the capabilities of large language models (LLMs) for clinical reasoning and diagnosis.
The framework involves a two-step process:
- Diagnosis Generation: The LLM is prompted to generate a diagnosis based on a patient's clinical information (e.g., symptoms, medical history).
- Rationale Generation: The LLM is then prompted to explain its reasoning for the generated diagnosis, producing a "rationale" that provides insights into its decision-making process.
This approach aims to enhance the transparency and interpretability of the LLM's diagnostic decisions, addressing a key challenge in the deployment of AI systems in healthcare settings. By generating explanatory rationales, the framework allows users to better understand and trust the LLM's outputs.
The researchers evaluate their framework using a large clinical dataset, assessing the LLM's accuracy in diagnosis generation as well as the quality and relevance of the generated rationales. Their results demonstrate the potential of LLMs to serve as effective clinical reasoners, while also highlighting areas for further improvement, such as incorporating domain-specific knowledge and enhancing the coherence of the generated rationales.
Critical Analysis
The researchers' Reasoning-Aware Diagnosis Framework represents an interesting and promising approach to leveraging large language models (LLMs) for clinical decision-making. By focusing on the transparency of the LLM's reasoning process, the framework aims to address a key challenge in the deployment of AI systems in healthcare.
One potential limitation of the current work is the reliance on prompting the LLM to generate both the diagnosis and the rationale. This approach may be subject to biases or inconsistencies in the prompts, which could affect the quality and reliability of the model's outputs. Exploring more advanced techniques, such as integrating reasoning capabilities directly into the LLM architecture, could be a valuable area for future research.
Additionally, the evaluation of the framework focused primarily on the quality and relevance of the generated rationales, rather than on their impact on clinical decision-making and patient outcomes. Further research is needed to understand how these explainable AI systems can be effectively integrated into real-world healthcare settings and their effects on clinician decision-making and patient care.
Overall, the Reasoning-Aware Diagnosis Framework represents an important step towards enhancing the transparency and trust in LLM-based clinical decision support systems. Continued advancements in this area could lead to more effective and reliable AI tools for healthcare professionals and improved patient outcomes.
Conclusion
This paper presents a Reasoning-Aware Diagnosis Framework that leverages the clinical reasoning capabilities of large language models (LLMs) to support disease diagnosis. By prompting the LLM to not only generate a diagnosis but also explain its reasoning, the framework aims to improve the transparency and trustworthiness of the model's outputs.
The researchers' evaluation of this framework demonstrates the potential for LLMs to serve as effective clinical reasoners, while also highlighting areas for further improvement, such as enhancing the coherence and domain-specificity of the generated rationales. As research continues to advance the reasoning capabilities of LLMs, this work represents an important step towards the integration of explainable AI systems in healthcare, with the ultimate goal of improving patient care and outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Guiding Clinical Reasoning with Large Language Models via Knowledge Seeds
Jiageng WU, Xian Wu, Jie Yang
0
0
Clinical reasoning refers to the cognitive process that physicians employ in evaluating and managing patients. This process typically involves suggesting necessary examinations, diagnosing patients' diseases, and deciding on appropriate therapies, etc. Accurate clinical reasoning requires extensive medical knowledge and rich clinical experience, setting a high bar for physicians. This is particularly challenging in developing countries due to the overwhelming number of patients and limited physician resources, contributing significantly to global health inequity and necessitating automated clinical reasoning approaches. Recently, the emergence of large language models (LLMs) such as ChatGPT and GPT-4 have demonstrated their potential in clinical reasoning. However, these LLMs are prone to hallucination problems, and the reasoning process of LLMs may not align with the clinical decision path of physicians. In this study, we introduce a novel framework, In-Context Padding (ICP), designed to enhance LLMs with medical knowledge. Specifically, we infer critical clinical reasoning elements (referred to as knowledge seeds) and use these as anchors to guide the generation process of LLMs. Experiments on two clinical question datasets demonstrate that ICP significantly improves the clinical reasoning ability of LLMs.
6/11/2024

ArgMed-Agents: Explainable Clinical Decision Reasoning with LLM Disscusion via Argumentation Schemes
Shengxin Hong, Liang Xiao, Xin Zhang, Jianxia Chen
0
0
There are two main barriers to using large language models (LLMs) in clinical reasoning. Firstly, while LLMs exhibit significant promise in Natural Language Processing (NLP) tasks, their performance in complex reasoning and planning falls short of expectations. Secondly, LLMs use uninterpretable methods to make clinical decisions that are fundamentally different from the clinician's cognitive processes. This leads to user distrust. In this paper, we present a multi-agent framework called ArgMed-Agents, which aims to enable LLM-based agents to make explainable clinical decision reasoning through interaction. ArgMed-Agents performs self-argumentation iterations via Argumentation Scheme for Clinical Discussion (a reasoning mechanism for modeling cognitive processes in clinical reasoning), and then constructs the argumentation process as a directed graph representing conflicting relationships. Ultimately, use symbolic solver to identify a series of rational and coherent arguments to support decision. We construct a formal model of ArgMed-Agents and present conjectures for theoretical guarantees. ArgMed-Agents enables LLMs to mimic the process of clinical argumentative reasoning by generating explanations of reasoning in a self-directed manner. The setup experiments show that ArgMed-Agents not only improves accuracy in complex clinical decision reasoning problems compared to other prompt methods, but more importantly, it provides users with decision explanations that increase their confidence.
6/24/2024
🤯
D-NLP at SemEval-2024 Task 2: Evaluating Clinical Inference Capabilities of Large Language Models
Duygu Altinok
0
0
Large language models (LLMs) have garnered significant attention and widespread usage due to their impressive performance in various tasks. However, they are not without their own set of challenges, including issues such as hallucinations, factual inconsistencies, and limitations in numerical-quantitative reasoning. Evaluating LLMs in miscellaneous reasoning tasks remains an active area of research. Prior to the breakthrough of LLMs, Transformers had already proven successful in the medical domain, effectively employed for various natural language understanding (NLU) tasks. Following this trend, LLMs have also been trained and utilized in the medical domain, raising concerns regarding factual accuracy, adherence to safety protocols, and inherent limitations. In this paper, we focus on evaluating the natural language inference capabilities of popular open-source and closed-source LLMs using clinical trial reports as the dataset. We present the performance results of each LLM and further analyze their performance on a development set, particularly focusing on challenging instances that involve medical abbreviations and require numerical-quantitative reasoning. Gemini, our leading LLM, achieved a test set F1-score of 0.748, securing the ninth position on the task scoreboard. Our work is the first of its kind, offering a thorough examination of the inference capabilities of LLMs within the medical domain.
5/8/2024
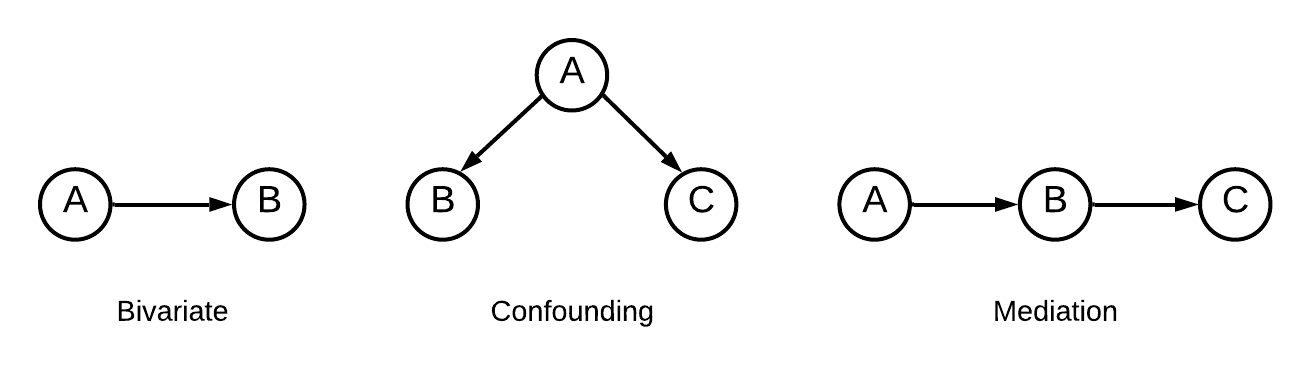
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
0
0
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
4/9/2024