Evaluating Knowledge-based Cross-lingual Inconsistency in Large Language Models
2407.01358
0
0
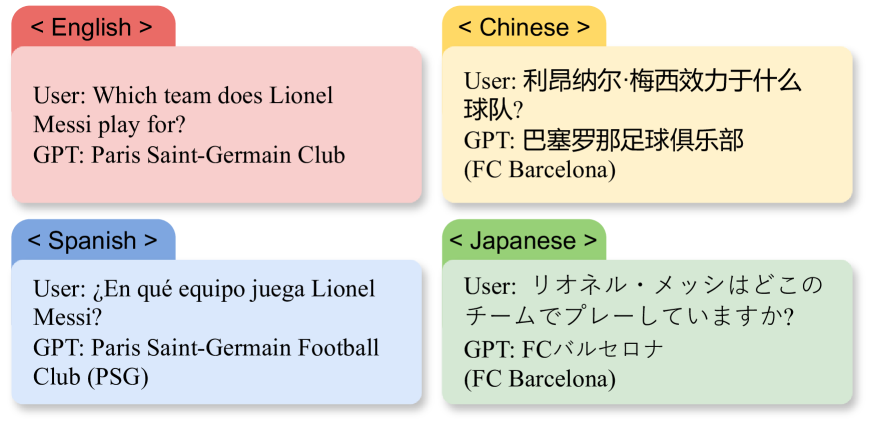
Abstract
This paper investigates the cross-lingual inconsistencies observed in Large Language Models (LLMs), such as ChatGPT, Llama, and Baichuan, which have shown exceptional performance in various Natural Language Processing (NLP) tasks. Despite their successes, these models often exhibit significant inconsistencies when processing the same concepts across different languages. This study focuses on three primary questions: the existence of cross-lingual inconsistencies in LLMs, the specific aspects in which these inconsistencies manifest, and the correlation between cross-lingual consistency and multilingual capabilities of LLMs.To address these questions, we propose an innovative evaluation method for Cross-lingual Semantic Consistency (xSC) using the LaBSE model. We further introduce metrics for Cross-lingual Accuracy Consistency (xAC) and Cross-lingual Timeliness Consistency (xTC) to comprehensively assess the models' performance regarding semantic, accuracy, and timeliness inconsistencies. By harmonizing these metrics, we provide a holistic measurement of LLMs' cross-lingual consistency. Our findings aim to enhance the understanding and improvement of multilingual capabilities and interpretability in LLMs, contributing to the development of more robust and reliable multilingual language models.
Create account to get full access
Overview
• This paper examines the knowledge-based cross-lingual inconsistencies in large language models (LLMs), which are AI systems trained on massive amounts of text data to generate human-like language.
• The researchers evaluate the ability of LLMs to maintain consistency in their knowledge and outputs across different languages, a critical factor for the widespread deployment of these models in multilingual applications.
• The findings provide insights into the limitations and barriers that need to be addressed to enable truly language-agnostic LLMs capable of delivering reliable and coherent information across languages.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text in various languages. However, these models may exhibit inconsistencies in their knowledge and outputs across different languages. This paper investigates this issue, known as knowledge-based cross-lingual inconsistency, to understand the challenges in developing multilingual LLMs that can provide reliable information regardless of the language used.
The researchers designed experiments to assess how well LLMs maintain consistency in their responses to the same questions or prompts when asked in different languages. They found that LLMs can sometimes give contradictory or inaccurate information across languages, even on factual topics where the underlying knowledge should be language-agnostic.
These findings highlight the need to address the language barriers and knowledge gaps in large language models to create truly multilingual AI systems that can understand and communicate coherently across languages. Further research is needed to understand the root causes of these cross-lingual inconsistencies and develop techniques to improve the language-agnostic capabilities of LLMs.
Technical Explanation
The researchers designed a series of experiments to evaluate the knowledge-based cross-lingual inconsistency in LLMs. They selected several LLMs, including GPT-3, BERT, and XLM-R, and probed them with the same questions or prompts in multiple languages, such as English, German, and Hindi.
By analyzing the models' responses, the researchers identified instances where the LLMs provided contradictory or inaccurate information across languages, even on factual topics where the underlying knowledge should be language-agnostic. These inconsistencies were observed in areas such as general knowledge, current events, and common sense reasoning.
The findings suggest that while LLMs have made significant progress in language understanding and generation, they still struggle to maintain coherent and reliable knowledge representations that can be seamlessly applied across multiple languages. This limitation poses a barrier to the development of truly multilingual AI systems that can serve users regardless of their language proficiency.
Critical Analysis
The paper highlights an important and under-explored challenge in the development of large language models: ensuring consistent knowledge and outputs across languages. While the researchers provide a thorough evaluation of this issue, the paper does not delve deeply into the potential causes of the observed cross-lingual inconsistencies.
One area that could benefit from further investigation is the role of the training data and its quality, coverage, and alignment across languages. The researchers acknowledge that the LLMs' performance may be influenced by the availability and composition of the multilingual data used during training.
Additionally, the paper does not explore potential mitigation strategies or architectural modifications that could help address the knowledge-based cross-lingual inconsistency problem. Future research could focus on developing techniques to enhance the language-agnostic capabilities of LLMs, such as improved multilingual data curation, cross-lingual knowledge transfer, or model architectures specifically designed for multilingual coherence.
Conclusion
This paper sheds light on a crucial challenge facing the development of large language models: maintaining consistent and reliable knowledge representations across multiple languages. The findings demonstrate that even state-of-the-art LLMs can exhibit contradictory or inaccurate outputs when responding to the same prompts in different languages, highlighting the need for further research and innovation to address this limitation.
Overcoming the knowledge-based cross-lingual inconsistency in LLMs is essential for the widespread deployment of these models in a wide range of multilingual applications, from language translation and content generation to question-answering and decision support systems. The insights from this study can inform future efforts to create truly language-agnostic AI systems that can reliably and coherently serve users regardless of their linguistic background.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Lynn Chua, Badih Ghazi, Yangsibo Huang, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Amer Sinha, Chulin Xie, Chiyuan Zhang
0
0
Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
6/26/2024

1+1>2: Can Large Language Models Serve as Cross-Lingual Knowledge Aggregators?
Yue Huang, Chenrui Fan, Yuan Li, Siyuan Wu, Tianyi Zhou, Xiangliang Zhang, Lichao Sun
0
0
Large Language Models (LLMs) have garnered significant attention due to their remarkable ability to process information across various languages. Despite their capabilities, they exhibit inconsistencies in handling identical queries in different languages, presenting challenges for further advancement. This paper introduces a method to enhance the multilingual performance of LLMs by aggregating knowledge from diverse languages. This approach incorporates a low-resource knowledge detector specific to a language, a language selection process, and mechanisms for answer replacement and integration. Our experiments demonstrate notable performance improvements, particularly in reducing language performance disparity. An ablation study confirms that each component of our method significantly contributes to these enhancements. This research highlights the inherent potential of LLMs to harmonize multilingual capabilities and offers valuable insights for further exploration.
6/24/2024
A Survey on Multilingual Large Language Models: Corpora, Alignment, and Bias
Yuemei Xu, Ling Hu, Jiayi Zhao, Zihan Qiu, Yuqi Ye, Hanwen Gu
0
0
Based on the foundation of Large Language Models (LLMs), Multilingual Large Language Models (MLLMs) have been developed to address the challenges of multilingual natural language processing tasks, hoping to achieve knowledge transfer from high-resource to low-resource languages. However, significant limitations and challenges still exist, such as language imbalance, multilingual alignment, and inherent bias. In this paper, we aim to provide a comprehensive analysis of MLLMs, delving deeply into discussions surrounding these critical issues. First of all, we start by presenting an overview of MLLMs, covering their evolution, key techniques, and multilingual capacities. Secondly, we explore widely utilized multilingual corpora for MLLMs' training and multilingual datasets oriented for downstream tasks that are crucial for enhancing the cross-lingual capability of MLLMs. Thirdly, we survey the existing studies on multilingual representations and investigate whether the current MLLMs can learn a universal language representation. Fourthly, we discuss bias on MLLMs including its category and evaluation metrics, and summarize the existing debiasing techniques. Finally, we discuss existing challenges and point out promising research directions. By demonstrating these aspects, this paper aims to facilitate a deeper understanding of MLLMs and their potentiality in various domains.
6/7/2024

The Model Arena for Cross-lingual Sentiment Analysis: A Comparative Study in the Era of Large Language Models
Xiliang Zhu, Shayna Gardiner, Tere Rold'an, David Rossouw
0
0
Sentiment analysis serves as a pivotal component in Natural Language Processing (NLP). Advancements in multilingual pre-trained models such as XLM-R and mT5 have contributed to the increasing interest in cross-lingual sentiment analysis. The recent emergence in Large Language Models (LLM) has significantly advanced general NLP tasks, however, the capability of such LLMs in cross-lingual sentiment analysis has not been fully studied. This work undertakes an empirical analysis to compare the cross-lingual transfer capability of public Small Multilingual Language Models (SMLM) like XLM-R, against English-centric LLMs such as Llama-3, in the context of sentiment analysis across English, Spanish, French and Chinese. Our findings reveal that among public models, SMLMs exhibit superior zero-shot cross-lingual performance relative to LLMs. However, in few-shot cross-lingual settings, public LLMs demonstrate an enhanced adaptive potential. In addition, we observe that proprietary GPT-3.5 and GPT-4 lead in zero-shot cross-lingual capability, but are outpaced by public models in few-shot scenarios.
6/28/2024