Breaking Boundaries: Investigating the Effects of Model Editing on Cross-linguistic Performance

0

Sign in to get full access
Overview
- This research paper investigates the effects of editing large language models on their cross-linguistic performance.
- It explores how making targeted changes to a model's parameters can impact its ability to perform well on tasks in multiple languages.
- The paper provides insights into the complex relationships between model architecture, training data, and cross-lingual generalization.
Plain English Explanation
Large language models like GPT-3 have become incredibly powerful at tasks like translation, question answering, and text generation. However, these models are often trained on data from a limited set of languages, which can result in biased or suboptimal performance when applied to other languages.
This research investigates whether it's possible to improve a model's cross-linguistic abilities by directly editing its parameters. The researchers took a pre-trained multilingual language model and made small, targeted changes to its internal representations. They then tested the model's performance on a variety of tasks in different languages to see how the editing impacted its cross-lingual capabilities.
The results show that even minor edits to a model's parameters can have significant effects on its cross-linguistic performance. In some cases, the researchers were able to improve the model's performance in one language while maintaining or even enhancing its abilities in other languages. This suggests that careful model editing could be a powerful technique for developing more robust and versatile language AI systems.
Technical Explanation
The researchers used a pre-trained multilingual model as a starting point, which had been trained on data from over 100 languages using a technique called cross-lingual transfer learning. They then applied a series of targeted edits to the model's parameters, inspired by previous work on editing language models.
The edits were designed to either enhance or degrade the model's performance on specific languages. The researchers then evaluated the model's cross-lingual abilities on a battery of tasks, including machine translation, named entity recognition, and question answering.
The results showed that the model editing had a significant impact on its cross-linguistic performance. In some cases, the researchers were able to improve the model's abilities in one language while maintaining or even enhancing its performance in others. This suggests that targeted parameter editing could be a powerful technique for developing more robust and versatile language AI systems.
Critical Analysis
The research presented in this paper provides valuable insights into the complex relationships between model architecture, training data, and cross-lingual generalization. The authors' findings demonstrate the potential of model editing as a technique for improving the cross-linguistic capabilities of large language models.
However, the paper also acknowledges several limitations and areas for further research. For example, the experiments were conducted on a relatively small set of languages, and the editing process was manually designed by the researchers. It's unclear whether the same techniques would scale to larger, more diverse sets of languages or whether the editing process could be automated.
Additionally, the paper does not delve into the potential ethical implications of model editing, such as the risks of unintended biases or the challenges of ensuring transparency and accountability in the model development process.
Overall, this research represents an important step forward in our understanding of how to build more robust and versatile language AI systems. However, there is still much work to be done to fully realize the potential of these techniques and to address the significant challenges that remain.
Conclusion
This research paper presents a novel approach to improving the cross-linguistic performance of large language models by directly editing their internal parameters. The results demonstrate that targeted model editing can have a significant impact on a model's abilities across multiple languages, suggesting that this technique could be a powerful tool for developing more robust and versatile language AI systems.
While the paper acknowledges several limitations and areas for further research, its findings represent an important contribution to the field of natural language processing. As AI systems become increasingly integrated into our daily lives, the ability to build models that can perform well across diverse linguistic and cultural contexts will be crucial. This research represents an important step towards realizing that goal.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Breaking Boundaries: Investigating the Effects of Model Editing on Cross-linguistic Performance
Somnath Banerjee, Avik Halder, Rajarshi Mandal, Sayan Layek, Ian Soboroff, Rima Hazra, Animesh Mukherjee
The integration of pretrained language models (PLMs) like BERT and GPT has revolutionized NLP, particularly for English, but it has also created linguistic imbalances. This paper strategically identifies the need for linguistic equity by examining several knowledge editing techniques in multilingual contexts. We evaluate the performance of models such as Mistral, TowerInstruct, OpenHathi, Tamil-Llama, and Kan-Llama across languages including English, German, French, Italian, Spanish, Hindi, Tamil, and Kannada. Our research identifies significant discrepancies in normal and merged models concerning cross-lingual consistency. We employ strategies like 'each language for itself' (ELFI) and 'each language for others' (ELFO) to stress-test these models. Our findings demonstrate the potential for LLMs to overcome linguistic barriers, laying the groundwork for future research in achieving linguistic inclusivity in AI technologies.
Read more7/19/2024

0
Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Lynn Chua, Badih Ghazi, Yangsibo Huang, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Amer Sinha, Chulin Xie, Chiyuan Zhang
Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
Read more6/26/2024
💬
0
Cross-Lingual Knowledge Editing in Large Language Models
Jiaan Wang, Yunlong Liang, Zengkui Sun, Yuxuan Cao, Jiarong Xu, Fandong Meng
Knowledge editing aims to change language models' performance on several special cases (i.e., editing scope) by infusing the corresponding expected knowledge into them. With the recent advancements in large language models (LLMs), knowledge editing has been shown as a promising technique to adapt LLMs to new knowledge without retraining from scratch. However, most of the previous studies neglect the multi-lingual nature of some main-stream LLMs (e.g., LLaMA, ChatGPT and GPT-4), and typically focus on monolingual scenarios, where LLMs are edited and evaluated in the same language. As a result, it is still unknown the effect of source language editing on a different target language. In this paper, we aim to figure out this cross-lingual effect in knowledge editing. Specifically, we first collect a large-scale cross-lingual synthetic dataset by translating ZsRE from English to Chinese. Then, we conduct English editing on various knowledge editing methods covering different paradigms, and evaluate their performance in Chinese, and vice versa. To give deeper analyses of the cross-lingual effect, the evaluation includes four aspects, i.e., reliability, generality, locality and portability. Furthermore, we analyze the inconsistent behaviors of the edited models and discuss their specific challenges. Data and codes are available at https://github.com/krystalan/Bi_ZsRE
Read more5/31/2024
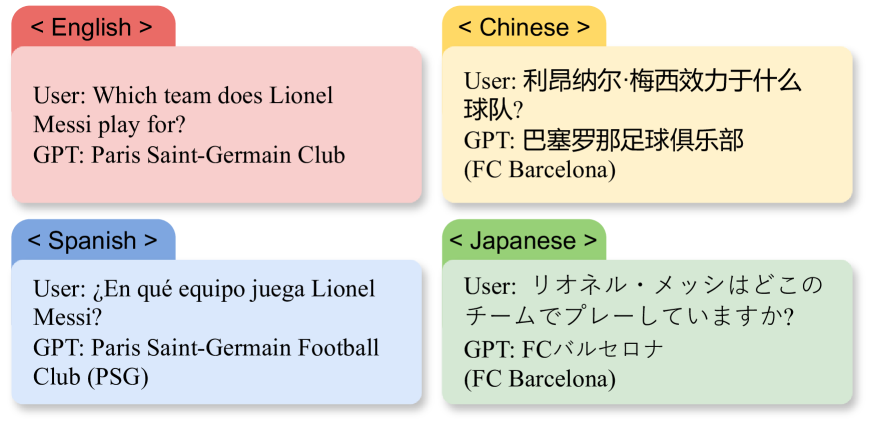
0
Evaluating Knowledge-based Cross-lingual Inconsistency in Large Language Models
Xiaolin Xing, Zhiwei He, Haoyu Xu, Xing Wang, Rui Wang, Yu Hong
This paper investigates the cross-lingual inconsistencies observed in Large Language Models (LLMs), such as ChatGPT, Llama, and Baichuan, which have shown exceptional performance in various Natural Language Processing (NLP) tasks. Despite their successes, these models often exhibit significant inconsistencies when processing the same concepts across different languages. This study focuses on three primary questions: the existence of cross-lingual inconsistencies in LLMs, the specific aspects in which these inconsistencies manifest, and the correlation between cross-lingual consistency and multilingual capabilities of LLMs.To address these questions, we propose an innovative evaluation method for Cross-lingual Semantic Consistency (xSC) using the LaBSE model. We further introduce metrics for Cross-lingual Accuracy Consistency (xAC) and Cross-lingual Timeliness Consistency (xTC) to comprehensively assess the models' performance regarding semantic, accuracy, and timeliness inconsistencies. By harmonizing these metrics, we provide a holistic measurement of LLMs' cross-lingual consistency. Our findings aim to enhance the understanding and improvement of multilingual capabilities and interpretability in LLMs, contributing to the development of more robust and reliable multilingual language models.
Read more7/2/2024