Evaluating Large Language Models with Grid-Based Game Competitions: An Extensible LLM Benchmark and Leaderboard

0

Sign in to get full access
Overview
- This paper presents an extensible benchmark and leaderboard for evaluating the capabilities of large language models (LLMs) using grid-based game competitions.
- The benchmark, called LLM-Grid, consists of a set of games that assess various skills like strategic reasoning, language understanding, and task completion.
- The paper describes the design and implementation of LLM-Grid, as well as the results of experiments conducted to evaluate several state-of-the-art LLMs across the benchmark tasks.
Plain English Explanation
The paper introduces a new way to test the abilities of large language models (LLMs) - software systems that can understand and generate human-like text. Instead of traditional tests, the researchers created a set of competitive grid-based games that LLMs can play. These games are designed to assess different skills, like the ability to think strategically, understand language, and complete tasks.
By having LLMs compete against each other in these games, the researchers can get a better understanding of the models' strengths and weaknesses. This is important because as LLMs become more advanced, it's crucial to have robust ways to evaluate their capabilities across a wide range of tasks. The Exploring Latest LLMs Leaderboard Extraction paper discusses the need for comprehensive benchmarks to track the progress of LLMs.
The games in the LLM-Grid benchmark cover areas like reasoning, language understanding, and task completion. For example, one game might involve two LLMs competing to capture the most territory on a grid by taking strategic actions. Another game might test an LLM's ability to follow complex instructions and complete a set of tasks. By having the LLMs compete against each other, the researchers can see how they perform relative to one another and identify areas for improvement.
The GTBench: Uncovering Strategic Reasoning Limitations of LLMs via Grid-Based Games paper explores a similar approach to testing LLM capabilities through grid-based games. The GraphArena: Benchmarking Large Language Models for Graph Computational Reasoning paper also looks at evaluating LLMs using graph-based tasks.
Overall, the LLM-Grid benchmark provides a novel and extensible way to assess the capabilities of large language models, which is important as these models become more advanced and integrated into various applications.
Technical Explanation
The paper introduces LLM-Grid, an extensible benchmark for evaluating the capabilities of large language models (LLMs) using grid-based game competitions. The benchmark consists of a set of games that assess various skills, including strategic reasoning, language understanding, and task completion.
The games in LLM-Grid are designed to be played by two or more LLMs, with each model taking turns to make moves or perform actions within a grid-based environment. The games are implemented using a flexible framework that allows for the creation of new game scenarios and the integration of different LLM systems.
The researchers conducted experiments to evaluate several state-of-the-art LLMs, including GPT-3, Meena, and RETRO, across the LLM-Grid benchmark. The results of these experiments provide insights into the strengths and weaknesses of the tested LLMs, highlighting areas where they excel or struggle.
The How Far Are We? Decision-Making in Large Language Models paper discusses the importance of evaluating the decision-making capabilities of LLMs, which is a key focus of the LLM-Grid benchmark.
The LLM-Grid benchmark is designed to be extensible, allowing for the addition of new game scenarios and the integration of new LLM systems. This flexibility is important as the field of large language models continues to evolve, and new models with increasingly advanced capabilities are developed.
Critical Analysis
The LLM-Grid benchmark provides a novel and promising approach for evaluating the capabilities of large language models. By using grid-based games, the researchers are able to assess a wide range of skills, including strategic reasoning, language understanding, and task completion, in a competitive and engaging environment.
One potential limitation of the LLM-Grid benchmark is the scope of the games included. While the researchers describe the benchmark as extensible, the current set of games may not capture the full breadth of skills and capabilities required for real-world applications of LLMs. The MegaVerse: Benchmarking Large Language Models Across Languages and Modalities paper discusses the importance of evaluating LLMs across a diverse range of tasks and modalities.
Additionally, the performance of LLMs in grid-based games may not directly translate to their performance in other types of tasks or real-world scenarios. Further research is needed to understand the relationship between LLM performance in the LLM-Grid benchmark and their capabilities in other domains.
Despite these potential limitations, the LLM-Grid benchmark represents an important step forward in the evaluation of large language models. By providing a standardized and extensible framework for testing LLM capabilities, the researchers have created a valuable tool for the research community to better understand the current state of the art and identify areas for future development.
Conclusion
The LLM-Grid benchmark presented in this paper offers a novel and extensible approach for evaluating the capabilities of large language models. By using grid-based game competitions, the researchers are able to assess a range of skills, including strategic reasoning, language understanding, and task completion, in a competitive and engaging environment.
The results of the experiments conducted using the LLM-Grid benchmark provide valuable insights into the strengths and weaknesses of several state-of-the-art LLMs, highlighting areas where they excel or struggle. As the field of large language models continues to evolve, the LLM-Grid benchmark can serve as an important tool for tracking the progress of these models and identifying areas for further development.
Overall, the LLM-Grid benchmark represents an important contribution to the ongoing efforts to comprehensively evaluate the capabilities of large language models, which is crucial as these models become increasingly integrated into a wide range of applications and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating Large Language Models with Grid-Based Game Competitions: An Extensible LLM Benchmark and Leaderboard
Oguzhan Topsakal, Colby Jacob Edell, Jackson Bailey Harper
We introduce a novel and extensible benchmark for large language models (LLMs) through grid-based games such as Tic-Tac-Toe, Connect Four, and Gomoku. The open-source game simulation code, available on GitHub, allows LLMs to compete and generates detailed data files in JSON, CSV, TXT, and PNG formats for leaderboard rankings and further analysis. We present the results of games among leading LLMs, including Claude 3.5 Sonnet and Claude 3 Sonnet by Anthropic, Gemini 1.5 Pro and Gemini 1.5 Flash by Google, GPT-4 Turbo and GPT-4o by OpenAI, and Llama3-70B by Meta. We also encourage submissions of results from other LLMs. In total, we simulated 2,310 matches (5 sessions for each pair among 7 LLMs and a random player) across three types of games, using three distinct prompt types: list, illustration, and image. The results revealed significant variations in LLM performance across different games and prompt types, with analysis covering win and disqualification rates, missed opportunity analysis, and invalid move analysis. The details of the leaderboard and result matrix data are available as open-access data on GitHub. This study enhances our understanding of LLMs' capabilities in playing games they were not specifically trained for, helping to assess their rule comprehension and strategic thinking. On the path to Artificial General Intelligence (AGI), this study lays the groundwork for future exploration into their utility in complex decision-making scenarios, illuminating their strategic thinking abilities and offering directions for further inquiry into the limits of LLMs within game-based frameworks.
Read more7/12/2024
0
How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, Michael R. Lyu
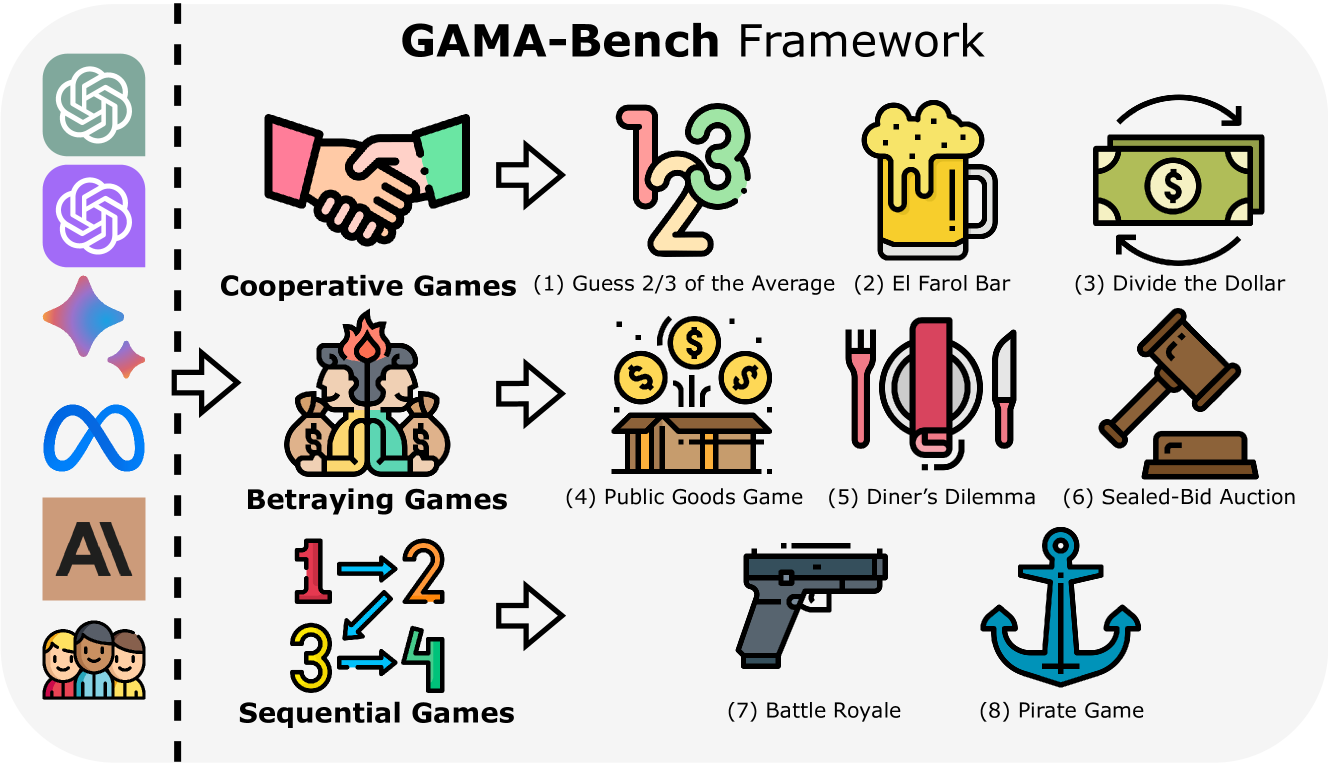
Decision-making, a complicated task requiring various types of abilities, presents an excellent framework for assessing Large Language Models (LLMs). Our research investigates decision-making capabilities of LLMs through the lens of Game Theory. We focus specifically on games that support the simultaneous participation of more than two agents. We introduce GAMA($gamma$)-Bench, which evaluates LLMs' Gaming Ability in Multi-Agent environments. $gamma$-Bench includes eight classical multi-agent games and a scoring scheme specially designed to quantitatively assess LLMs' performance. Leveraging $gamma$-Bench, we investigate LLMs' robustness, generalizability, and strategies for enhancement. Results reveal that while GPT-3.5 shows satisfying robustness, its generalizability is relatively limited. However, its performance can be improved through approaches such as Chain-of-Thought. Additionally, we evaluate twelve versions from six models, including GPT-3.5, GPT-4, Gemini, LLaMA-3.1, Mixtral, and Qwen-2. We find that Gemini-1.5-Pro outperforms other models with a score of $63.8$ out of $100$, followed by LLaMA-3.1-70B and GPT-4 with scores of $60.9$ and $60.5$, respectively. The code and experimental results are made publicly available via https://github.com/CUHK-ARISE/GAMABench.
Read more9/4/2024

0
Exploring the Latest LLMs for Leaderboard Extraction
Salomon Kabongo, Jennifer D'Souza, Soren Auer
The rapid advancements in Large Language Models (LLMs) have opened new avenues for automating complex tasks in AI research. This paper investigates the efficacy of different LLMs-Mistral 7B, Llama-2, GPT-4-Turbo and GPT-4.o in extracting leaderboard information from empirical AI research articles. We explore three types of contextual inputs to the models: DocTAET (Document Title, Abstract, Experimental Setup, and Tabular Information), DocREC (Results, Experiments, and Conclusions), and DocFULL (entire document). Our comprehensive study evaluates the performance of these models in generating (Task, Dataset, Metric, Score) quadruples from research papers. The findings reveal significant insights into the strengths and limitations of each model and context type, providing valuable guidance for future AI research automation efforts.
Read more7/10/2024
0
New!Evaluating the Performance of Large Language Models in Competitive Programming: A Multi-Year, Multi-Grade Analysis
Adrian Marius Dumitran, Adrian Catalin Badea, Stefan-Gabriel Muscalu
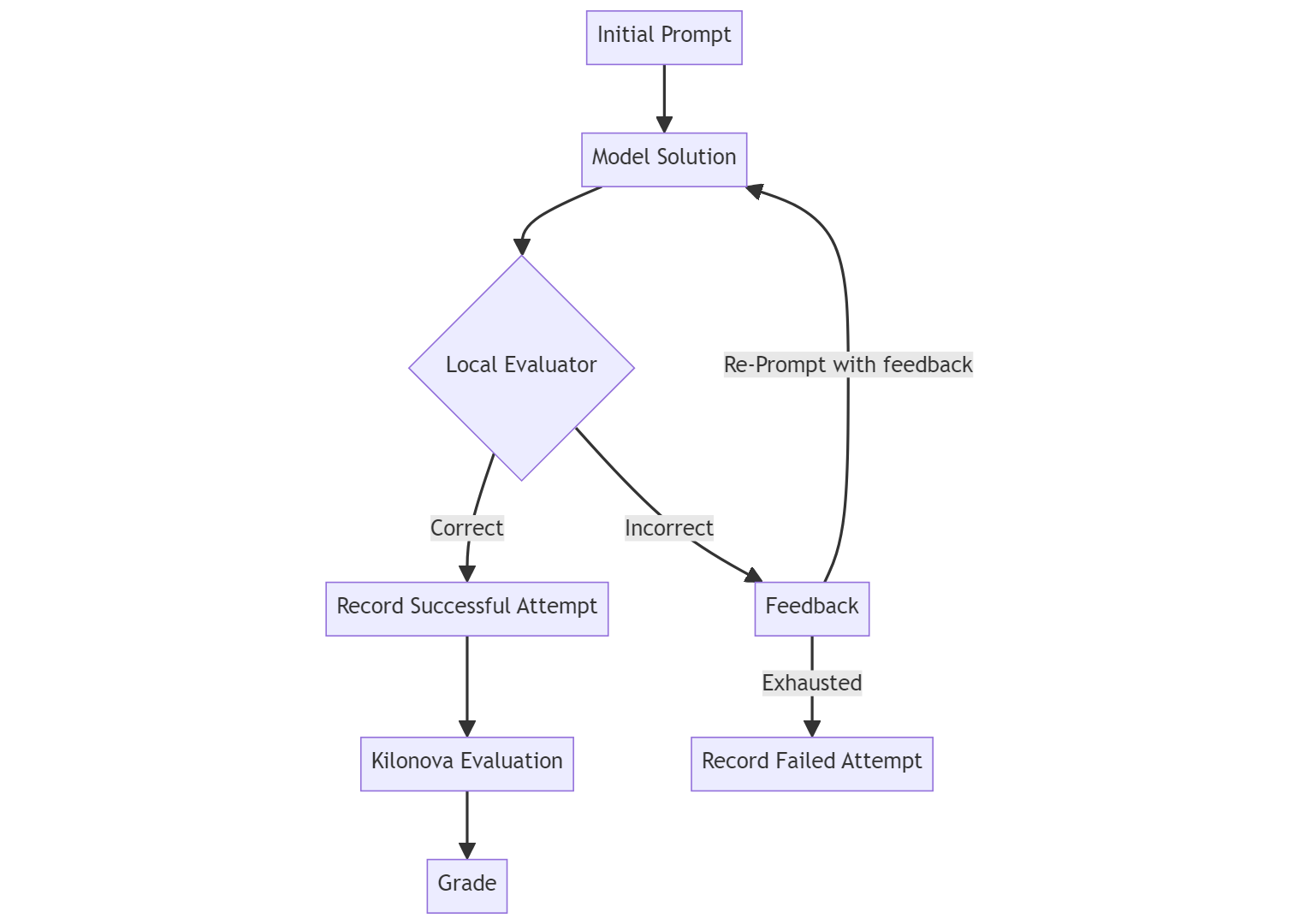
This study explores the performance of large language models (LLMs) in solving competitive programming problems from the Romanian Informatics Olympiad at the county level. Romania, a leading nation in computer science competitions, provides an ideal environment for evaluating LLM capabilities due to its rich history and stringent competition standards. We collected and analyzed a dataset comprising 304 challenges from 2002 to 2023, focusing on solutions written by LLMs in C++ and Python for these problems. Our primary goal is to understand why LLMs perform well or poorly on different tasks. We evaluated various models, including closed-source models like GPT-4 and open-weight models such as CodeLlama and RoMistral, using a standardized process involving multiple attempts and feedback rounds. The analysis revealed significant variations in LLM performance across different grades and problem types. Notably, GPT-4 showed strong performance, indicating its potential use as an educational tool for middle school students. We also observed differences in code quality and style across various LLMs
Read more9/17/2024