Evaluating LLMs at Detecting Errors in LLM Responses
2404.03602
0
0

Abstract
With Large Language Models (LLMs) being widely used across various tasks, detecting errors in their responses is increasingly crucial. However, little research has been conducted on error detection of LLM responses. Collecting error annotations on LLM responses is challenging due to the subjective nature of many NLP tasks, and thus previous research focuses on tasks of little practical value (e.g., word sorting) or limited error types (e.g., faithfulness in summarization). This work introduces ReaLMistake, the first error detection benchmark consisting of objective, realistic, and diverse errors made by LLMs. ReaLMistake contains three challenging and meaningful tasks that introduce objectively assessable errors in four categories (reasoning correctness, instruction-following, context-faithfulness, and parameterized knowledge), eliciting naturally observed and diverse errors in responses of GPT-4 and Llama 2 70B annotated by experts. We use ReaLMistake to evaluate error detectors based on 12 LLMs. Our findings show: 1) Top LLMs like GPT-4 and Claude 3 detect errors made by LLMs at very low recall, and all LLM-based error detectors perform much worse than humans. 2) Explanations by LLM-based error detectors lack reliability. 3) LLMs-based error detection is sensitive to small changes in prompts but remains challenging to improve. 4) Popular approaches to improving LLMs, including self-consistency and majority vote, do not improve the error detection performance. Our benchmark and code are provided at https://github.com/psunlpgroup/ReaLMistake.
Create account to get full access
Overview
- This paper evaluates the ability of large language models (LLMs) to detect errors in their own responses.
- The researchers designed a novel benchmark to test LLMs' error detection capabilities across a range of tasks and error types.
- The results provide insights into the strengths and limitations of current LLM systems in self-evaluating their outputs.
Plain English Explanation
In this paper, the researchers set out to investigate how well large language models (LLMs) - the powerful AI systems that can generate human-like text - are able to detect mistakes or errors in their own responses. They created a new benchmark or test that challenged these LLMs to identify different types of errors across a variety of tasks.
The motivation behind this research is that as LLMs become more advanced and integrated into real-world applications, it's important to understand their ability to self-evaluate and catch their own mistakes. This could help improve the reliability and trustworthiness of these AI systems.
The researchers designed their benchmark to test LLMs on a range of error types, from factual inaccuracies to logical inconsistencies. They then evaluated how well popular LLM systems like GPT-3 and PaLM performed at detecting these errors in their own generated text.
The results provide insights into the current limitations of LLMs when it comes to self-evaluation. While the models showed some ability to catch certain types of errors, they struggled with more nuanced or complex mistakes. This suggests that more work is needed to develop LLMs that can reliably monitor and correct their own outputs.
Overall, this research highlights an important challenge in the development of advanced AI systems - ensuring they can accurately assess the quality and correctness of their own responses. The findings from this paper can help guide future efforts to improve LLMs' self-awareness and error detection capabilities.
Technical Explanation
The paper presents a novel benchmark for evaluating the ability of large language models (LLMs) to detect errors in their own generated responses. The researchers designed a diverse set of test cases covering a range of potential error types, including factual inaccuracies, logical inconsistencies, grammatical mistakes, and others.
The benchmark was structured as a two-stage process. First, the LLMs were tasked with generating responses to prompts across various tasks like question answering, summarization, and open-ended generation. Then, in the second stage, the models were asked to identify any errors present in their own outputs.
The researchers evaluated the performance of several prominent LLMs, including GPT-3, PaLM, and LLaMA, on this error detection benchmark. The results showed that while the models exhibited some capability to catch certain types of errors, they struggled with more nuanced or complex mistakes. For example, the LLMs performed better at identifying factual inaccuracies than logical inconsistencies.
The paper also explored how the performance of the LLMs varied across different task domains, error types, and confidence levels. These insights can help inform future research and development efforts to improve LLMs' self-evaluation abilities.
Overall, this work highlights the importance of developing robust error detection capabilities in advanced language models, as they become increasingly integrated into real-world applications. The benchmark and findings from this paper provide a valuable foundation for further exploration in this area.
Critical Analysis
The researchers have made a strong contribution to the field by developing a comprehensive benchmark for evaluating LLMs' error detection capabilities. The diversity of test cases and range of error types covered in the benchmark are notable strengths, providing a more holistic assessment than previous work.
However, the paper does acknowledge some potential limitations in the benchmark design. For example, the researchers note that the errors were manually injected into the LLM responses, which may not fully capture the types of errors that could arise in more naturalistic settings. Additionally, the benchmark only tested the LLMs' ability to detect errors, rather than their capacity to correct or remediate those errors.
Another area for further exploration is the role of model size, training data, and other architectural factors in LLMs' error detection performance. The paper compares the results across several prominent models, but a more systematic investigation of these design choices could yield additional insights.
It would also be valuable to understand the cognitive processes and reasoning strategies employed by LLMs when attempting to identify errors in their own outputs. Gaining deeper insights into these mechanisms could inform the development of more robust and transparent self-evaluation capabilities.
Overall, this paper represents an important step forward in evaluating the reliability and trustworthiness of large language models. The findings and benchmark design can serve as a valuable resource for the broader AI research community as they continue to push the boundaries of language understanding and generation.
Conclusion
This paper presents a novel benchmark for evaluating the ability of large language models (LLMs) to detect errors in their own generated responses. The researchers designed a diverse set of test cases covering a range of potential error types, and evaluated the performance of several prominent LLMs, including GPT-3, PaLM, and LLaMA.
The results provide valuable insights into the current limitations of LLMs when it comes to self-evaluation. While the models exhibited some capability to catch certain types of errors, they struggled with more nuanced or complex mistakes. This suggests that more work is needed to develop LLMs that can reliably monitor and correct their own outputs.
The benchmark and findings from this paper can serve as a valuable resource for the broader AI research community as they continue to explore ways to improve the reliability and trustworthiness of large language models. As these powerful AI systems become increasingly integrated into real-world applications, ensuring their ability to self-evaluate and catch their own mistakes will be crucial for building public trust and confidence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
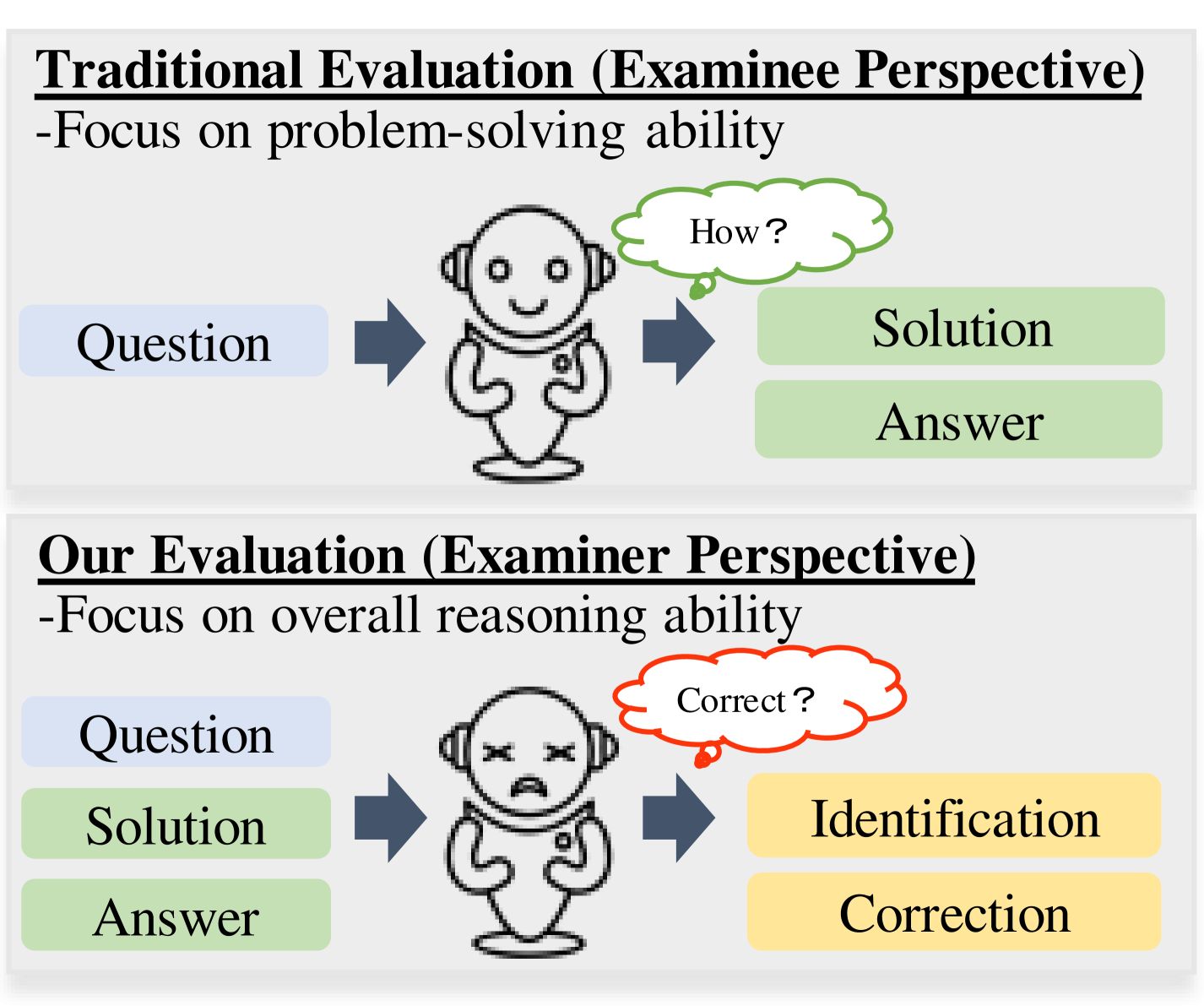
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
0
0
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
6/4/2024
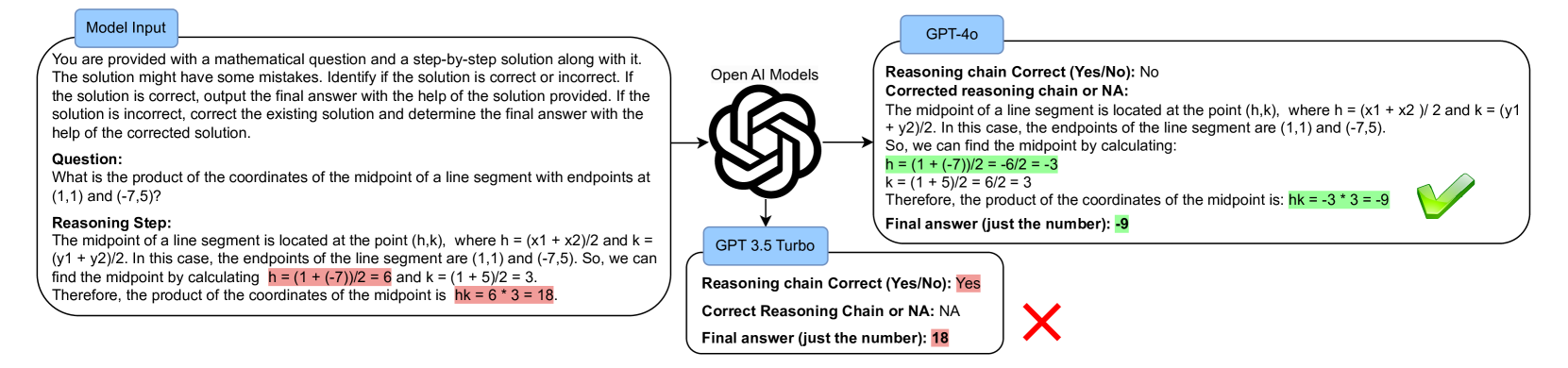
Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning
Joykirat Singh, Akshay Nambi, Vibhav Vineet
0
0
Large Language Models (LLMs) have been applied to Math Word Problems (MWPs) with transformative impacts, revolutionizing how these complex problems are approached and solved in various domains including educational settings. However, the evaluation of these models often prioritizes final accuracy, overlooking the crucial aspect of reasoning capabilities. This work addresses this gap by focusing on the ability of LLMs to detect and correct reasoning mistakes. We introduce a novel dataset MWP-MISTAKE, incorporating MWPs with both correct and incorrect reasoning steps generated through rule-based methods and smaller language models. Our comprehensive benchmarking reveals significant insights into the strengths and weaknesses of state-of-the-art models, such as GPT-4o, GPT-4, GPT-3.5Turbo, and others. We highlight GPT-$o's superior performance in mistake detection and rectification and the persistent challenges faced by smaller models. Additionally, we identify issues related to data contamination and memorization, impacting the reliability of LLMs in real-world applications. Our findings emphasize the importance of rigorous evaluation of reasoning processes and propose future directions to enhance the generalization and robustness of LLMs in mathematical problem-solving.
6/18/2024
Large Language Models Are State-of-the-Art Evaluator for Grammatical Error Correction
Masamune Kobayashi, Masato Mita, Mamoru Komachi
0
0
Large Language Models (LLMs) have been reported to outperform existing automatic evaluation metrics in some tasks, such as text summarization and machine translation. However, there has been a lack of research on LLMs as evaluators in grammatical error correction (GEC). In this study, we investigate the performance of LLMs in GEC evaluation by employing prompts designed to incorporate various evaluation criteria inspired by previous research. Our extensive experimental results demonstrate that GPT-4 achieved Kendall's rank correlation of 0.662 with human judgments, surpassing all existing methods. Furthermore, in recent GEC evaluations, we have underscored the significance of the LLMs scale and particularly emphasized the importance of fluency among evaluation criteria.
5/28/2024
🤯
LLMs cannot find reasoning errors, but can correct them given the error location
Gladys Tyen, Hassan Mansoor, Victor Cu{a}rbune, Peter Chen, Tony Mak
0
0
While self-correction has shown promise in improving LLM outputs in terms of style and quality (e.g. Chen et al., 2023b; Madaan et al., 2023), recent attempts to self-correct logical or reasoning errors often cause correct answers to become incorrect, resulting in worse performances overall (Huang et al., 2023). In this paper, we show that poor self-correction performance stems from LLMs' inability to find logical mistakes, rather than their ability to correct a known mistake. Firstly, we benchmark several state-of-the-art LLMs on their mistake-finding ability and demonstrate that they generally struggle with the task, even in highly objective, unambiguous cases. Secondly, we test the correction abilities of LLMs -- separately from mistake finding -- using a backtracking setup that feeds ground truth mistake location information to the model. We show that this boosts downstream task performance across our 5 reasoning tasks, indicating that LLMs' correction abilities are robust. Finally, we show that it is possible to obtain mistake location information without ground truth labels or in-domain training data. We train a small classifier with out-of-domain data, which exhibits stronger mistake-finding performance than prompting a large model. We release our dataset of LLM-generated logical mistakes, BIG-Bench Mistake, to enable further research into locating LLM reasoning mistakes.
6/5/2024