Evaluating the method reproducibility of deep learning models in the biodiversity domain

0
Sign in to get full access
Overview
- This paper evaluates the method reproducibility of deep learning models in the biodiversity domain.
- The author investigates the challenges in reproducing the results of deep learning models, which is crucial for advancing scientific knowledge and building trust in these models.
- The research aims to provide insights into the factors that affect the reproducibility of deep learning models, especially in the context of biodiversity research.
Plain English Explanation
Deep learning, a type of artificial intelligence, has become increasingly popular in the field of biodiversity research. These complex algorithms can analyze large datasets and make predictions about things like species identification or habitat suitability. However, reproducing the results of deep learning models can be a significant challenge. This is because the models often rely on a lot of intricate details, like the specific dataset used, the model architecture, and the training process.
In this paper, the author examines the issues around reproducing the methods of deep learning models in biodiversity research. The goal is to understand what factors make it easier or harder to reproduce the results of these models, so that researchers can improve the reliability and interpretability of their work. This is important because it helps build trust in the findings and allows the research to be built upon by others in the field.
Technical Explanation
The paper presents an in-depth examination of the method reproducibility of deep learning models in the biodiversity domain. The author conducted a series of experiments to evaluate the factors that influence the reproducibility of these models, including the choice of dataset, model architecture, and training process.
The research involved replicating the methods used in several published studies that applied deep learning to biodiversity-related tasks, such as species identification or habitat mapping. The author carefully documented each step of the replication process and compared the results to the original findings. This allowed the identification of specific factors that made it easier or more challenging to reproduce the results.
The paper also discusses the practical challenges and considerations involved in integrating measures of replicability into the research process. The author provides recommendations for how researchers can design their studies and report their methods in a way that enhances the reproducibility of deep learning models in the biodiversity domain.
Critical Analysis
The paper provides valuable insights into the challenges of reproducing the results of deep learning models in biodiversity research. The author's thorough examination of the factors that influence reproducibility is commendable, and the recommendations offered are well-grounded in the findings.
However, the paper does not delve deeply into the potential causes of the observed issues with reproducibility. For example, it would have been interesting to explore whether the complexity of deep learning models, the lack of standardized data formats, or the limited reporting of model hyperparameters and training details contribute to the difficulties in replicating results.
Additionally, the paper could have benefited from a more critical analysis of the broader implications of the reproducibility challenges. How do these issues impact the reliability and interpretability of deep learning models in biodiversity research, and what are the potential consequences for scientific progress and decision-making in this domain?
Conclusion
This paper makes an important contribution to understanding the method reproducibility of deep learning models in the biodiversity domain. The author's systematic approach to evaluating the factors that influence reproducibility provides valuable insights that can inform the design and reporting of future deep learning studies in this field.
The findings highlight the need for greater attention to reproducibility and replicability in the application of deep learning to biodiversity research. By addressing these issues, the scientific community can build stronger foundations for advancing our understanding of the natural world and informing conservation and management efforts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating the method reproducibility of deep learning models in the biodiversity domain
Waqas Ahmed, Vamsi Krishna Kommineni, Birgitta Konig-Ries, Jitendra Gaikwad, Luiz Gadelha, Sheeba Samuel
Artificial Intelligence (AI) is revolutionizing biodiversity research by enabling advanced data analysis, species identification, and habitats monitoring, thereby enhancing conservation efforts. Ensuring reproducibility in AI-driven biodiversity research is crucial for fostering transparency, verifying results, and promoting the credibility of ecological findings.This study investigates the reproducibility of deep learning (DL) methods within the biodiversity domain. We design a methodology for evaluating the reproducibility of biodiversity-related publications that employ DL techniques across three stages. We define ten variables essential for method reproducibility, divided into four categories: resource requirements, methodological information, uncontrolled randomness, and statistical considerations. These categories subsequently serve as the basis for defining different levels of reproducibility. We manually extract the availability of these variables from a curated dataset comprising 61 publications identified using the keywords provided by biodiversity experts. Our study shows that the dataset is shared in 47% of the publications; however, a significant number of the publications lack comprehensive information on deep learning methods, including details regarding randomness.
Read more7/11/2024
0
What is Reproducibility in Artificial Intelligence and Machine Learning Research?
Abhyuday Desai, Mohamed Abdelhamid, Nakul R. Padalkar
In the rapidly evolving fields of Artificial Intelligence (AI) and Machine Learning (ML), the reproducibility crisis underscores the urgent need for clear validation methodologies to maintain scientific integrity and encourage advancement. The crisis is compounded by the prevalent confusion over validation terminology. Responding to this challenge, we introduce a validation framework that clarifies the roles and definitions of key validation efforts: repeatability, dependent and independent reproducibility, and direct and conceptual replicability. This structured framework aims to provide AI/ML researchers with the necessary clarity on these essential concepts, facilitating the appropriate design, conduct, and interpretation of validation studies. By articulating the nuances and specific roles of each type of validation study, we hope to contribute to a more informed and methodical approach to addressing the challenges of reproducibility, thereby supporting the community's efforts to enhance the reliability and trustworthiness of its research findings.
Read more7/16/2024
0
Towards Enhancing the Reproducibility of Deep Learning Bugs: An Empirical Study
Mehil B. Shah, Mohammad Masudur Rahman, Foutse Khomh
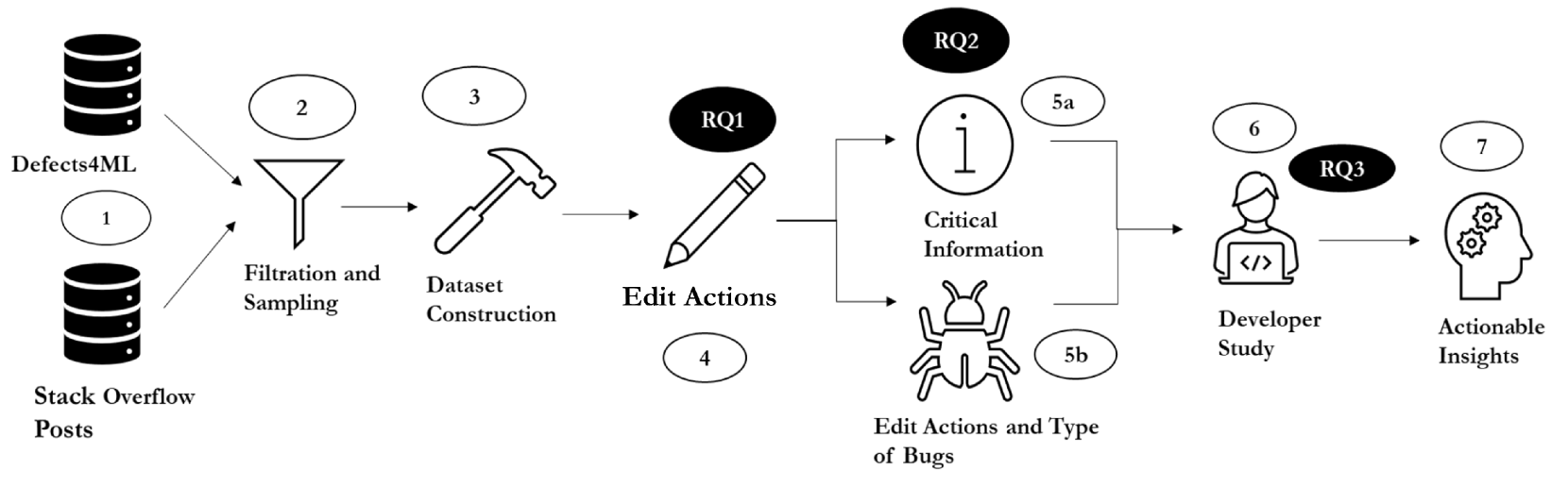
Context: Deep learning has achieved remarkable progress in various domains. However, like any software system, deep learning systems contain bugs, some of which can have severe impacts, as evidenced by crashes involving autonomous vehicles. Despite substantial advancements in deep learning techniques, little research has focused on reproducing deep learning bugs, which is an essential step for their resolution. Existing literature suggests that only 3% of deep learning bugs are reproducible, underscoring the need for further research. Objective: This paper examines the reproducibility of deep learning bugs. We identify edit actions and useful information that could improve the reproducibility of deep learning bugs. Method: First, we construct a dataset of 668 deep-learning bugs from Stack Overflow and GitHub across three frameworks and 22 architectures. Second, out of the 668 bugs, we select 165 bugs using stratified sampling and attempt to determine their reproducibility. While reproducing these bugs, we identify edit actions and useful information for their reproduction. Third, we used the Apriori algorithm to identify useful information and edit actions required to reproduce specific types of bugs. Finally, we conducted a user study involving 22 developers to assess the effectiveness of our findings in real-life settings. Results: We successfully reproduced 148 out of 165 bugs attempted. We identified ten edit actions and five useful types of component information that can help us reproduce the deep learning bugs. With the help of our findings, the developers were able to reproduce 22.92% more bugs and reduce their reproduction time by 24.35%. Conclusions: Our research addresses the critical issue of deep learning bug reproducibility. Practitioners and researchers can leverage our findings to improve deep learning bug reproducibility.
Read more8/26/2024

0
GeoAI Reproducibility and Replicability: a computational and spatial perspective
Wenwen Li, Chia-Yu Hsu, Sizhe Wang, Peter Kedron
GeoAI has emerged as an exciting interdisciplinary research area that combines spatial theories and data with cutting-edge AI models to address geospatial problems in a novel, data-driven manner. While GeoAI research has flourished in the GIScience literature, its reproducibility and replicability (R&R), fundamental principles that determine the reusability, reliability, and scientific rigor of research findings, have rarely been discussed. This paper aims to provide an in-depth analysis of this topic from both computational and spatial perspectives. We first categorize the major goals for reproducing GeoAI research, namely, validation (repeatability), learning and adapting the method for solving a similar or new problem (reproducibility), and examining the generalizability of the research findings (replicability). Each of these goals requires different levels of understanding of GeoAI, as well as different methods to ensure its success. We then discuss the factors that may cause the lack of R&R in GeoAI research, with an emphasis on (1) the selection and use of training data; (2) the uncertainty that resides in the GeoAI model design, training, deployment, and inference processes; and more importantly (3) the inherent spatial heterogeneity of geospatial data and processes. We use a deep learning-based image analysis task as an example to demonstrate the results' uncertainty and spatial variance caused by different factors. The findings reiterate the importance of knowledge sharing, as well as the generation of a replicability map that incorporates spatial autocorrelation and spatial heterogeneity into consideration in quantifying the spatial replicability of GeoAI research.
Read more4/23/2024