Competition-Level Problems are Effective LLM Evaluators
2312.02143
0
0
📉
Abstract
Large language models (LLMs) have demonstrated impressive reasoning capabilities, yet there is ongoing debate about these abilities and the potential data contamination problem recently. This paper aims to evaluate the reasoning capacities of LLMs, specifically in solving recent competition-level programming problems in Codeforces, which are expert-crafted and unique, requiring deep understanding and robust reasoning skills. We first provide a comprehensive evaluation of GPT-4's peiceived zero-shot performance on this task, considering various aspects such as problems' release time, difficulties, and types of errors encountered. Surprisingly, the peiceived performance of GPT-4 has experienced a cliff like decline in problems after September 2021 consistently across all the difficulties and types of problems, which shows the potential data contamination, as well as the challenges for any existing LLM to solve unseen complex reasoning problems. We further explore various approaches such as fine-tuning, Chain-of-Thought prompting and problem description simplification, unfortunately none of them is able to consistently mitigate the challenges. Through our work, we emphasis the importance of this excellent data source for assessing the genuine reasoning capabilities of LLMs, and foster the development of LLMs with stronger reasoning abilities and better generalization in the future.
Create account to get full access
Overview
- This paper aims to evaluate the reasoning capabilities of large language models (LLMs) by having them solve complex programming problems from the Codeforces competition.
- The researchers found that GPT-4's performance on these problems experienced a sharp decline after September 2021, suggesting potential data contamination and the challenges LLMs face in solving novel, complex reasoning tasks.
- The researchers explored various approaches like fine-tuning and prompt engineering, but none were able to consistently mitigate the challenges.
- The paper emphasizes the importance of using this dataset to assess the genuine reasoning abilities of LLMs and foster the development of models with stronger reasoning and generalization capabilities.
Plain English Explanation
Large language models (LLMs) like GPT-4 have shown impressive abilities when it comes to language tasks, but there's ongoing debate about how well they can actually reason and solve complex problems. This paper looks at how well LLMs can tackle programming problems from the Codeforces competition, which are designed by experts to require deep understanding and robust reasoning skills.
The researchers first had GPT-4 try to solve these problems without any special training or fine-tuning. Surprisingly, they found that GPT-4's performance on the problems took a sharp nosedive after September 2021, regardless of the problem's difficulty or type. This suggests that the model may have been affected by data contamination, where it was exposed to information about the problems during training, making it less able to solve truly novel challenges.
The researchers then tried various approaches to help the LLM perform better, like fine-tuning it on the problems or using prompting techniques to guide its reasoning. Unfortunately, none of these methods were able to consistently overcome the model's limitations.
Overall, the paper emphasizes that these Codeforces problems are an excellent way to assess the genuine reasoning abilities of LLMs, beyond just their language skills. By using this dataset, researchers can help develop models that are truly better at solving complex, novel problems, rather than just regurgitating information they've seen before. This is an important step towards building LLMs with stronger reasoning and generalization capabilities.
Technical Explanation
The researchers in this paper aimed to evaluate the reasoning capabilities of large language models (LLMs) by having them tackle competition-level programming problems from the Codeforces platform. Codeforces problems are designed by experts to require deep understanding and robust reasoning skills, making them an excellent benchmark for assessing the genuine problem-solving abilities of LLMs.
The researchers first conducted a comprehensive evaluation of GPT-4's zero-shot performance on the Codeforces problems, considering factors like the problems' release time, difficulty, and types of errors encountered. Surprisingly, they found that GPT-4's performance experienced a sharp, consistent decline across all problem types and difficulty levels after September 2021. This suggests the potential for data contamination, where the model may have been exposed to information about the problems during training, limiting its ability to solve truly novel challenges.
The researchers then explored various approaches to mitigate these challenges, such as fine-tuning the model on the Codeforces problems, using chain-of-thought prompting, and simplifying the problem descriptions. However, none of these methods were able to consistently improve the model's performance, highlighting the difficulties LLMs face in solving complex, unseen reasoning problems.
Critical Analysis
The researchers in this paper provide a valuable contribution to the ongoing debate about the reasoning capabilities of large language models (LLMs). By using the Codeforces dataset, which is designed to require deep understanding and robust reasoning skills, the researchers were able to uncover some significant limitations in GPT-4's problem-solving abilities.
The finding that GPT-4's performance declined sharply after September 2021, regardless of problem difficulty or type, is particularly concerning and suggests the potential for data contamination during the model's training. This raises important questions about the reliability and generalizability of LLMs' reasoning capabilities, and highlights the need for more rigorous testing and evaluation of these models.
While the researchers explored several approaches to mitigate the challenges, it's worth noting that the paper did not provide a comprehensive solution. The lack of consistent improvement across the various techniques, such as fine-tuning and prompt engineering, suggests that more fundamental advancements in LLM architecture and training may be necessary to achieve robust reasoning abilities.
Additionally, the paper could have delved deeper into the specific types of errors and reasoning failures observed in the LLM's attempts to solve the Codeforces problems. A more detailed analysis of these errors could provide valuable insights for improving the reasoning behavior of large language models.
Overall, this paper makes an important contribution to the field by highlighting the limitations of current LLMs in solving complex, novel reasoning problems. The researchers' emphasis on the Codeforces dataset as an excellent benchmark for assessing genuine reasoning capabilities is a valuable direction for future research in this area.
Conclusion
This paper provides a comprehensive evaluation of the reasoning capabilities of large language models (LLMs), specifically focusing on their ability to solve complex programming problems from the Codeforces competition. The researchers' findings suggest that while LLMs like GPT-4 have impressive language skills, they struggle with solving novel, expert-crafted reasoning problems, potentially due to issues like data contamination.
The paper underscores the importance of using datasets like Codeforces to rigorously assess the genuine reasoning abilities of LLMs, beyond just their language proficiency. By fostering the development of LLMs with stronger reasoning and generalization capabilities, researchers can work towards building AI systems that can tackle complex, real-world problems in a more robust and reliable manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
0
0
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
6/28/2024
🏷️
Navigating the Labyrinth: Evaluating and Enhancing LLMs' Ability to Reason About Search Problems
Nasim Borazjanizadeh, Roei Herzig, Trevor Darrell, Rogerio Feris, Leonid Karlinsky
0
0
Recently, Large Language Models (LLMs) attained impressive performance in math and reasoning benchmarks. However, they still often struggle with logic problems and puzzles that are relatively easy for humans. To further investigate this, we introduce a new benchmark, SearchBench, containing 11 unique search problem types, each equipped with automated pipelines to generate an arbitrary number of instances and analyze the feasibility, correctness, and optimality of LLM-generated solutions. We show that even the most advanced LLMs fail to solve these problems end-to-end in text, e.g. GPT4 solves only 1.4%. SearchBench problems require considering multiple pathways to the solution as well as backtracking, posing a significant challenge to auto-regressive models. Instructing LLMs to generate code that solves the problem helps, but only slightly, e.g., GPT4's performance rises to 11.7%. In this work, we show that in-context learning with A* algorithm implementations enhances performance. The full potential of this promoting approach emerges when combined with our proposed Multi-Stage-Multi-Try method, which breaks down the algorithm implementation into two stages and verifies the first stage against unit tests, raising GPT-4's performance above 57%.
6/19/2024

Can LLMs Reason in the Wild with Programs?
Yuan Yang, Siheng Xiong, Ali Payani, Ehsan Shareghi, Faramarz Fekri
0
0
Large Language Models (LLMs) have shown superior capability to solve reasoning problems with programs. While being a promising direction, most of such frameworks are trained and evaluated in settings with a prior knowledge of task requirements. However, as LLMs become more capable, it is necessary to assess their reasoning abilities in more realistic scenarios where many real-world problems are open-ended with ambiguous scope, and often require multiple formalisms to solve. To investigate this, we introduce the task of reasoning in the wild, where an LLM is tasked to solve a reasoning problem of unknown type by identifying the subproblems and their corresponding formalisms, and writing a program to solve each subproblem, guided by a tactic. We create a large tactic-guided trajectory dataset containing detailed solutions to a diverse set of reasoning problems, ranging from well-defined single-form reasoning (e.g., math, logic), to ambiguous and hybrid ones (e.g., commonsense, combined math and logic). This allows us to test various aspects of LLMs reasoning at the fine-grained level such as the selection and execution of tactics, and the tendency to take undesired shortcuts. In experiments, we highlight that existing LLMs fail significantly on problems with ambiguous and mixed scope, revealing critical limitations and overfitting issues (e.g. accuracy on GSM8K drops by at least 50%). We further show the potential of finetuning a local LLM on the tactic-guided trajectories in achieving better performance. Project repo is available at github.com/gblackout/Reason-in-the-Wild
6/21/2024
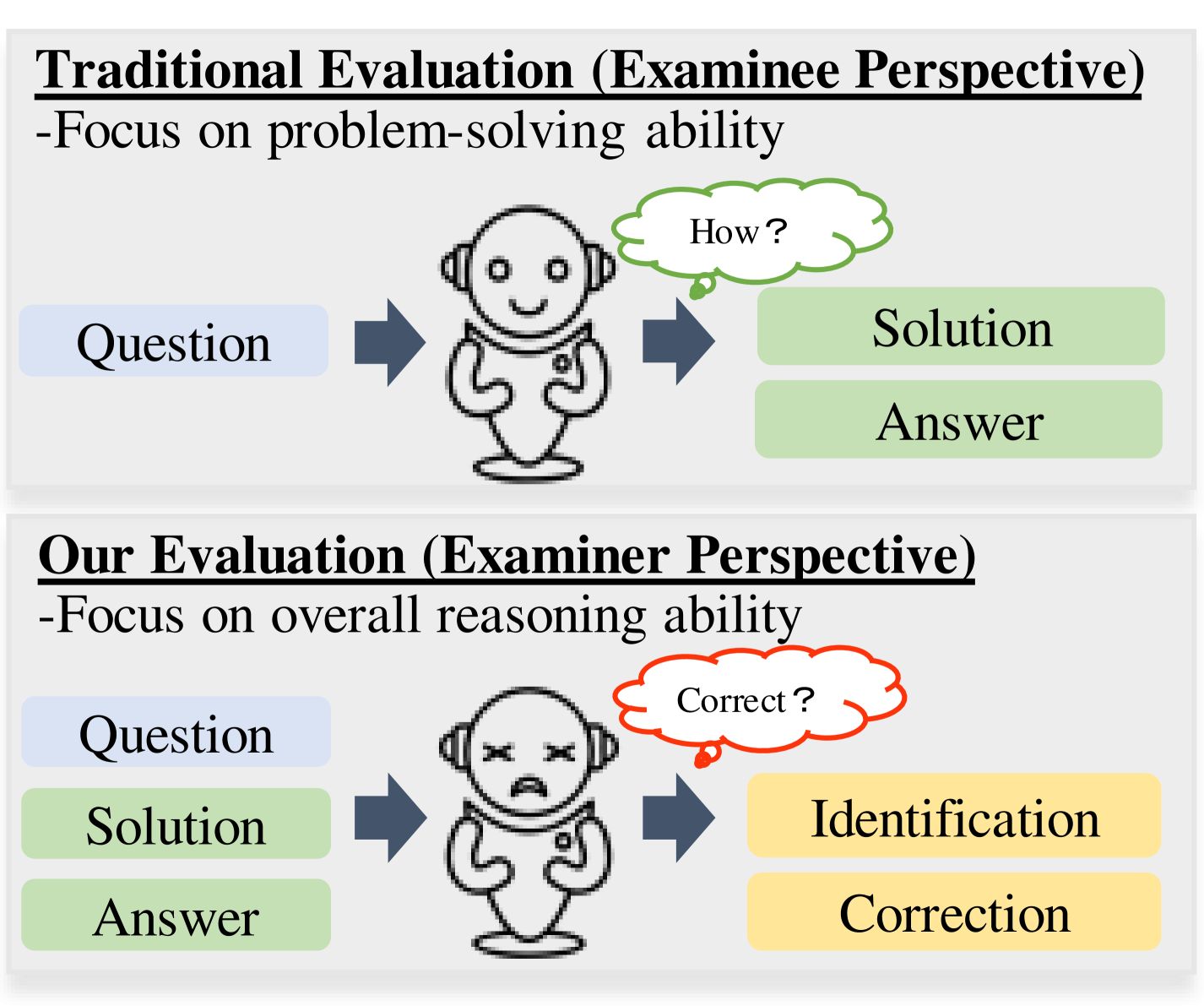
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
0
0
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
6/4/2024