Exploring Spatial Schema Intuitions in Large Language and Vision Models
2402.00956
0
0
Abstract
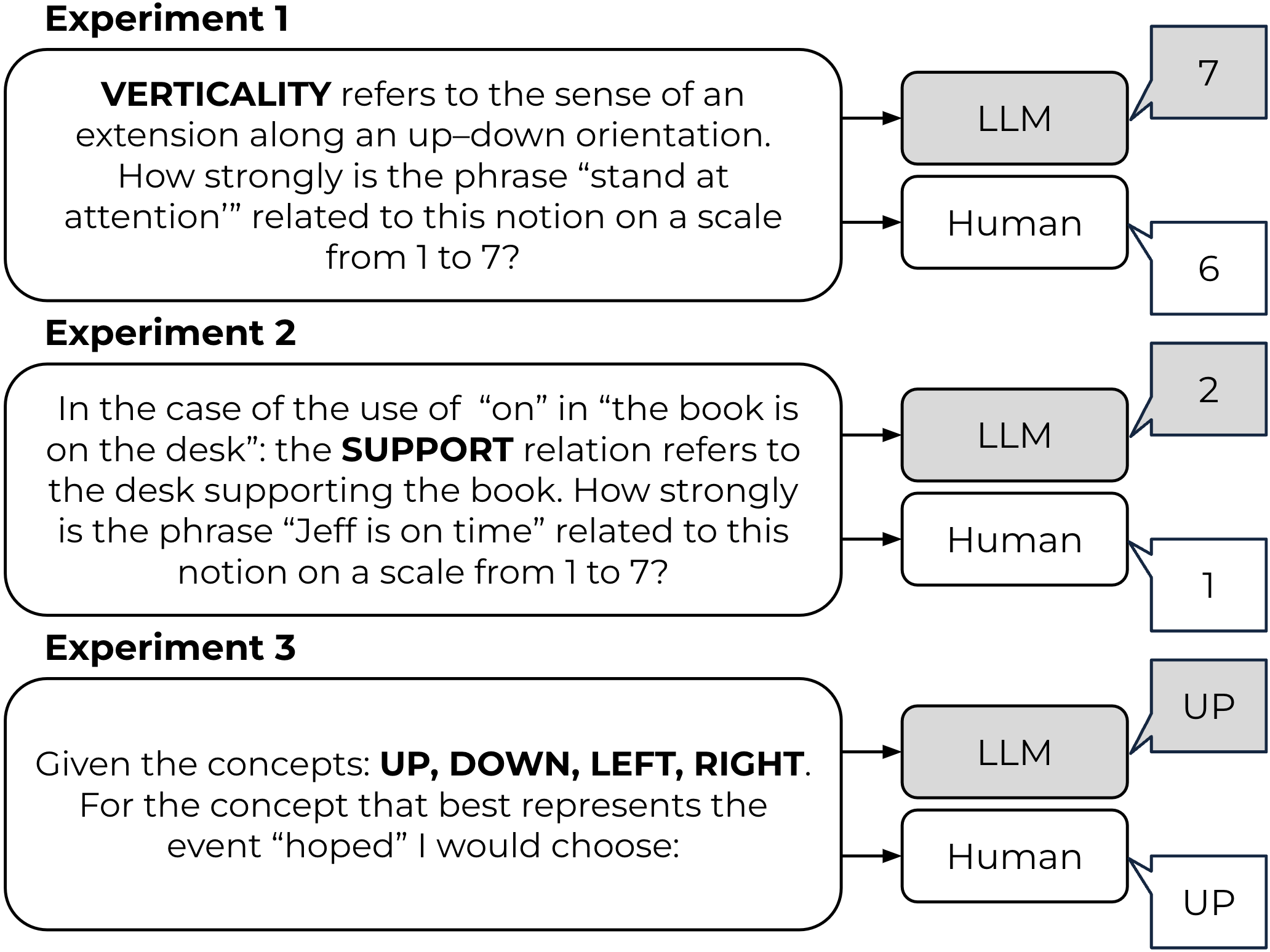
Despite the ubiquity of large language models (LLMs) in AI research, the question of embodiment in LLMs remains underexplored, distinguishing them from embodied systems in robotics where sensory perception directly informs physical action. Our investigation navigates the intriguing terrain of whether LLMs, despite their non-embodied nature, effectively capture implicit human intuitions about fundamental, spatial building blocks of language. We employ insights from spatial cognitive foundations developed through early sensorimotor experiences, guiding our exploration through the reproduction of three psycholinguistic experiments. Surprisingly, correlations between model outputs and human responses emerge, revealing adaptability without a tangible connection to embodied experiences. Notable distinctions include polarized language model responses and reduced correlations in vision language models. This research contributes to a nuanced understanding of the interplay between language, spatial experiences, and the computations made by large language models. More at https://cisnlp.github.io/Spatial_Schemas/
Create account to get full access
Overview
- The paper explores how large language and vision models (LLMs and LVMs) understand and reason about spatial concepts and schemas, which are fundamental to human cognition and language.
- The researchers investigate the models' ability to recognize, manipulate, and reason about spatial relations, as well as their capacity to generate and describe spatial imagery.
- The findings have implications for our understanding of how these models represent and reason about the physical world, and their potential applications in areas like navigation, robotics, and augmented reality.
Plain English Explanation
The paper looks at how powerful AI language and vision models, like the ones used in chatbots and image recognition, understand and think about spatial concepts. Spatial understanding - the ability to recognize, reason about, and manipulate the physical world around us - is a core part of how humans think and communicate.
The researchers wanted to see how well these AI models can grasp things like spatial relationships (e.g. "on top of," "next to"), visualize and describe scenes, and reason about 3D objects and environments. This gives insights into how the models represent and reason about the physical world, which is important for applications like navigation, robotics, and augmented reality.
The paper explores the models' "spatial schema intuitions" - their innate understanding of basic spatial concepts and how they apply them. The findings suggest these models have some impressive spatial reasoning capabilities, but also reveal limitations in their spatial understanding compared to humans.
Technical Explanation
The paper investigates the spatial reasoning capabilities of large language models (LLMs) and large vision-language models (LVMs) - powerful AI systems trained on vast amounts of text and visual data. The researchers designed a suite of tasks to probe the models' ability to recognize, manipulate, and reason about spatial concepts and schemas.
The tasks included identifying spatial relations in images, describing the spatial layout of scenes, and answering questions that require 3D spatial reasoning. The models were also asked to generate images based on text prompts involving spatial concepts. The performance of the models was compared to human benchmarks.
The results suggest the models have developed some robust spatial schema intuitions through their training, allowing them to successfully complete many of the spatial tasks. However, the models also exhibited systematic biases and limitations in their spatial understanding compared to humans. For example, they struggled with tasks involving complex 3D spatial reasoning or non-canonical viewpoints.
The findings have implications for understanding how these models internally represent and reason about the physical world. The researchers argue that probing spatial cognition provides a valuable window into the "minds" of LLMs and LVMs, with potential applications in areas like navigation, robotics, and augmented reality.
Critical Analysis
The paper provides a thoughtful and rigorous examination of spatial understanding in LLMs and LVMs, but also acknowledges several caveats and limitations to the research.
One key limitation is that the experiments were conducted on a relatively small set of models, and the findings may not generalize to the rapidly evolving field of large language and vision models. As the authors note, more diverse model architectures and training approaches should be explored to get a fuller picture.
Additionally, the paper focuses on evaluating spatial schema intuitions rather than more advanced spatial reasoning and manipulation abilities. While an important first step, further research is needed to understand the models' true spatial cognition capabilities and how they compare to human-level spatial intelligence.
The researchers also highlight the need to better characterize the types of spatial biases and blind spots exhibited by the models, and to investigate how these limitations might impact real-world applications. Developing more targeted diagnostic tools and probes could help shed light on these issues.
Overall, this work represents a valuable contribution to the growing body of research on the spatial and physical world understanding of LLMs and LVMs. By continuing to explore these models' strengths and limitations, we can gain key insights into their inner workings and guide their development towards more human-like spatial cognition.
Conclusion
This paper takes an important step in understanding the spatial reasoning capabilities of large language and vision models. By probing the models' ability to recognize, manipulate, and reason about spatial concepts and schemas, the researchers have uncovered both impressive spatial intuitions as well as systematic biases and limitations in the models' spatial understanding.
These findings have significant implications for our understanding of how these powerful AI systems internally represent and reason about the physical world. This, in turn, is crucial for realizing the full potential of these models in a wide range of applications, from navigation and robotics to augmented reality and beyond.
While more research is needed to fully characterize the spatial cognition of LLMs and LVMs, this work represents an important contribution to the field. By continuing to explore the models' strengths and weaknesses in spatial reasoning, we can work towards developing AI systems with more human-like understanding of the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Evaluating Spatial Understanding of Large Language Models
Yutaro Yamada, Yihan Bao, Andrew K. Lampinen, Jungo Kasai, Ilker Yildirim
0
0
Large language models (LLMs) show remarkable capabilities across a variety of tasks. Despite the models only seeing text in training, several recent studies suggest that LLM representations implicitly capture aspects of the underlying grounded concepts. Here, we explore LLM representations of a particularly salient kind of grounded knowledge -- spatial relationships. We design natural-language navigation tasks and evaluate the ability of LLMs, in particular GPT-3.5-turbo, GPT-4, and Llama2 series models, to represent and reason about spatial structures. These tasks reveal substantial variability in LLM performance across different spatial structures, including square, hexagonal, and triangular grids, rings, and trees. In extensive error analysis, we find that LLMs' mistakes reflect both spatial and non-spatial factors. These findings suggest that LLMs appear to capture certain aspects of spatial structure implicitly, but room for improvement remains.
4/16/2024

EmbSpatial-Bench: Benchmarking Spatial Understanding for Embodied Tasks with Large Vision-Language Models
Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, Zhongyu Wei
0
0
The recent rapid development of Large Vision-Language Models (LVLMs) has indicated their potential for embodied tasks.However, the critical skill of spatial understanding in embodied environments has not been thoroughly evaluated, leaving the gap between current LVLMs and qualified embodied intelligence unknown. Therefore, we construct EmbSpatial-Bench, a benchmark for evaluating embodied spatial understanding of LVLMs.The benchmark is automatically derived from embodied scenes and covers 6 spatial relationships from an egocentric perspective.Experiments expose the insufficient capacity of current LVLMs (even GPT-4V). We further present EmbSpatial-SFT, an instruction-tuning dataset designed to improve LVLMs' embodied spatial understanding.
6/11/2024

Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Neel Joshi
0
0
Large language models (LLMs) and vision-language models (VLMs) have demonstrated remarkable performance across a wide range of tasks and domains. Despite this promise, spatial understanding and reasoning -- a fundamental component of human cognition -- remains under-explored. We develop novel benchmarks that cover diverse aspects of spatial reasoning such as relationship understanding, navigation, and counting. We conduct a comprehensive evaluation of competitive language and vision-language models. Our findings reveal several counter-intuitive insights that have been overlooked in the literature: (1) Spatial reasoning poses significant challenges where competitive models can fall behind random guessing; (2) Despite additional visual input, VLMs often under-perform compared to their LLM counterparts; (3) When both textual and visual information is available, multi-modal language models become less reliant on visual information if sufficient textual clues are provided. Additionally, we demonstrate that leveraging redundancy between vision and text can significantly enhance model performance. We hope our study will inform the development of multimodal models to improve spatial intelligence and further close the gap with human intelligence.
6/24/2024
💬
Can Large Language Models Create New Knowledge for Spatial Reasoning Tasks?
Thomas Greatrix, Roger Whitaker, Liam Turner, Walter Colombo
0
0
The potential for Large Language Models (LLMs) to generate new information offers a potential step change for research and innovation. This is challenging to assert as it can be difficult to determine what an LLM has previously seen during training, making newness difficult to substantiate. In this paper we observe that LLMs are able to perform sophisticated reasoning on problems with a spatial dimension, that they are unlikely to have previously directly encountered. While not perfect, this points to a significant level of understanding that state-of-the-art LLMs can now achieve, supporting the proposition that LLMs are able to yield significant emergent properties. In particular, Claude 3 is found to perform well in this regard.
5/24/2024