An Evaluation Benchmark for Autoformalization in Lean4

0

Sign in to get full access
Overview
- This paper presents an evaluation benchmark for assessing the performance of autoformalization systems in the Lean4 theorem prover.
- Autoformalization is the process of automatically translating natural language descriptions of mathematical concepts into formal logical statements that can be verified by a computer.
- The benchmark covers a diverse set of topics, including improving autoformalization using type checking, process-driven autoformalization in Lean4, and the capabilities of large language models for control engineering.
Plain English Explanation
The paper describes a new way to test and compare different computer programs that can automatically convert math problems written in plain language into a formal, logical format that a computer can understand. This is important because it can make it easier for people to use powerful mathematical tools without needing to learn complex formal languages.
The authors have created a diverse set of test problems that cover a wide range of mathematical topics, like improving autoformalization using type checking and the capabilities of large language models for control engineering. By using this benchmark, researchers can see how well their autoformalization systems perform and identify areas for improvement.
Overall, this work helps advance the field of automated translation of natural language math problems into a format that computers can understand and work with, which could make these powerful tools more accessible to a wider audience.
Technical Explanation
The paper presents a new evaluation benchmark for assessing the performance of autoformalization systems in the Lean4 theorem prover. Autoformalization is the process of automatically translating natural language descriptions of mathematical concepts into formal logical statements that can be verified by a computer.
The benchmark covers a diverse set of topics, including process-driven autoformalization in Lean4, improving autoformalization using type checking, and the capabilities of large language models for control engineering. The authors have curated a set of test problems that cover a wide range of mathematical concepts and difficulty levels.
The benchmark is designed to evaluate the performance of autoformalization systems in terms of their accuracy, completeness, and efficiency. The authors provide a set of metrics and evaluation procedures that can be used to assess the performance of different systems.
The results of the benchmark evaluation are presented, which demonstrate the effectiveness of the benchmark and the performance of various autoformalization systems. The authors also discuss the potential implications of their work for the field of automated theorem proving and the development of more accessible mathematical tools.
Critical Analysis
The evaluation benchmark presented in this paper is a valuable contribution to the field of autoformalization and automated theorem proving. By providing a standardized set of test problems and evaluation metrics, the authors have created a useful tool for researchers and developers to assess the performance of their autoformalization systems.
However, the paper does not address some potential limitations of the benchmark. For example, the test problems may not capture the full range of challenges that autoformalization systems may face in real-world applications, such as dealing with ambiguous or context-dependent language, or handling complex mathematical concepts that are not covered in the benchmark.
Additionally, the paper does not discuss the potential biases or limitations of the autoformalization systems themselves. It is possible that these systems may have inherent biases or weaknesses that are not fully captured by the benchmark, which could limit their usefulness in certain applications.
Further research is needed to address these limitations and explore ways to expand the benchmark to cover a wider range of mathematical topics and real-world use cases. This could involve incorporating more advanced techniques like type checking or leveraging the capabilities of large language models to improve the performance of autoformalization systems.
Conclusion
The evaluation benchmark presented in this paper represents an important step forward in the field of autoformalization and automated theorem proving. By providing a standardized set of test problems and evaluation metrics, the authors have created a valuable tool for researchers and developers to assess the performance of their autoformalization systems.
The results of the benchmark evaluation demonstrate the effectiveness of the benchmark and the performance of various autoformalization systems. This work has the potential to improve the accessibility of powerful mathematical tools, as well as advance the field of automated theorem proving more broadly.
While the paper does not address all potential limitations of the benchmark, it lays the groundwork for future research and development in this area. By continuing to expand and refine the benchmark, and exploring new techniques for improving autoformalization, researchers can work towards creating more robust and effective tools for translating natural language math problems into formal logical statements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Evaluation Benchmark for Autoformalization in Lean4
Aryan Gulati, Devanshu Ladsaria, Shubhra Mishra, Jasdeep Sidhu, Brando Miranda
Large Language Models (LLMs) hold the potential to revolutionize autoformalization. The introduction of Lean4, a mathematical programming language, presents an unprecedented opportunity to rigorously assess the autoformalization capabilities of LLMs. This paper introduces a novel evaluation benchmark designed for Lean4, applying it to test the abilities of state-of-the-art LLMs, including GPT-3.5, GPT-4, and Gemini Pro. Our comprehensive analysis reveals that, despite recent advancements, these LLMs still exhibit limitations in autoformalization, particularly in more complex areas of mathematics. These findings underscore the need for further development in LLMs to fully harness their potential in scientific research and development. This study not only benchmarks current LLM capabilities but also sets the stage for future enhancements in autoformalization.
Read more6/12/2024
0
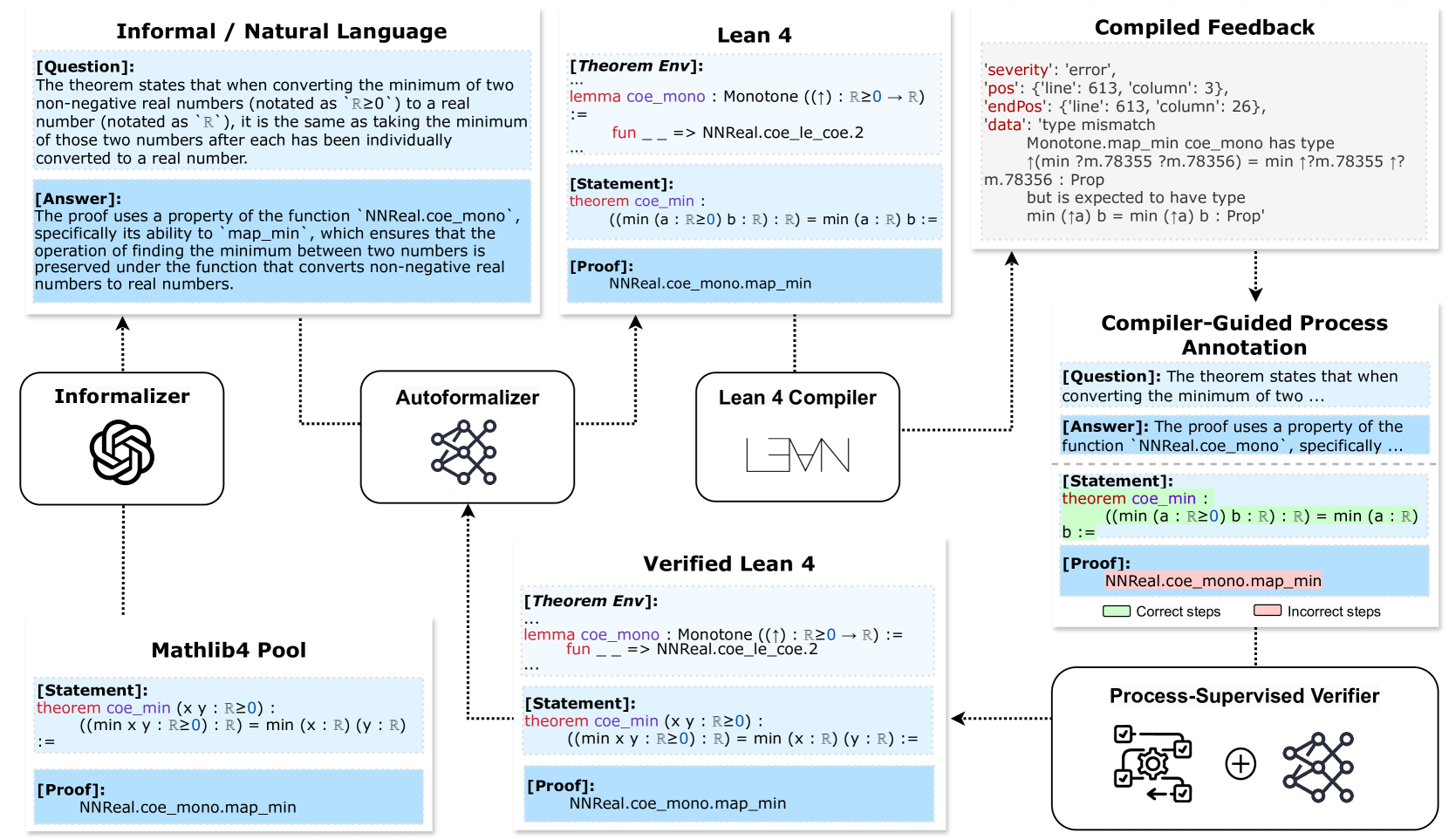
Process-Driven Autoformalization in Lean 4
Jianqiao Lu, Zhengying Liu, Yingjia Wan, Yinya Huang, Haiming Wang, Zhicheng Yang, Jing Tang, Zhijiang Guo
Autoformalization, the conversion of natural language mathematics into formal languages, offers significant potential for advancing mathematical reasoning. However, existing efforts are limited to formal languages with substantial online corpora and struggle to keep pace with rapidly evolving languages like Lean 4. To bridge this gap, we propose a new benchmark textbf{Form}alization for textbf{L}ean~textbf{4} (textbf{name}) designed to evaluate the autoformalization capabilities of large language models (LLMs). This benchmark encompasses a comprehensive assessment of questions, answers, formal statements, and proofs. Additionally, we introduce a textbf{P}rocess-textbf{S}upervised textbf{V}erifier (textbf{PSV}) model that leverages the precise feedback from Lean 4 compilers to enhance autoformalization. Our experiments demonstrate that the PSV method improves autoformalization, enabling higher accuracy using less filtered training data. Furthermore, when fine-tuned with data containing detailed process information, PSV can leverage the data more effectively, leading to more significant improvements in autoformalization for Lean 4. Our dataset and code are available at url{https://github.com/rookie-joe/PDA}.
Read more6/5/2024

0
Improving Autoformalization using Type Checking
Auguste Poiroux, Gail Weiss, Viktor Kunv{c}ak, Antoine Bosselut
Large language models show promise for autoformalization, the task of automatically translating natural language into formal languages. However, current autoformalization methods remain limited. The last reported state-of-the-art performance on the ProofNet formalization benchmark for the Lean proof assistant, achieved using Codex for Lean 3, only showed successful formalization of 16.1% of informal statements. Similarly, our evaluation of GPT-4o for Lean 4 only produces successful translations 34.9% of the time. Our analysis shows that the performance of these models is largely limited by their inability to generate formal statements that successfully type-check (i.e., are syntactically correct and consistent with types) - with a whopping 86.6% of GPT-4o errors starting from a type-check failure. In this work, we propose a method to fix this issue through decoding with type-check filtering, where we initially sample a diverse set of candidate formalizations for an informal statement, then use the Lean proof assistant to filter out candidates that do not type-check. Using GPT-4o as a base model, and combining our method with self-consistency, we obtain a +18.3% absolute increase in formalization accuracy, and achieve a new state-of-the-art of 53.2% on ProofNet with Lean 4.
Read more6/12/2024

0
TheoremLlama: Transforming General-Purpose LLMs into Lean4 Experts
Ruida Wang, Jipeng Zhang, Yizhen Jia, Rui Pan, Shizhe Diao, Renjie Pi, Tong Zhang
Proving mathematical theorems using computer-verifiable formal languages like Lean significantly impacts mathematical reasoning. One approach to formal theorem proving involves generating complete proofs using Large Language Models (LLMs) based on Natural Language (NL) proofs. Similar methods have shown promising results in code generation. However, most modern LLMs exhibit suboptimal performance due to the scarcity of aligned NL and Formal Language (FL) theorem-proving data. This scarcity results in a paucity of methodologies for training LLMs and techniques to fully utilize their capabilities in composing formal proofs. To address the challenges, this paper proposes **TheoremLlama**, an end-to-end framework to train a general-purpose LLM to become a Lean4 expert. This framework encompasses NL-FL aligned dataset generation methods, training approaches for the LLM formal theorem prover, and techniques for LLM Lean4 proof writing. Using the dataset generation method, we provide *Open Bootstrapped Theorems* (OBT), an NL-FL aligned and bootstrapped dataset. A key innovation in this framework is the NL-FL bootstrapping method, where NL proofs are integrated into Lean4 code for training datasets, leveraging the NL reasoning ability of LLMs for formal reasoning. The **TheoremLlama** framework achieves cumulative accuracies of 36.48% and 33.61% on MiniF2F-Valid and Test datasets respectively, surpassing the GPT-4 baseline of 22.95% and 25.41%. We have also open-sourced our model checkpoints and generated dataset, and will soon make all the code publicly available.
Read more7/4/2024