Capabilities of Large Language Models in Control Engineering: A Benchmark Study on GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra
2404.03647
0
0
💬
Abstract
In this paper, we explore the capabilities of state-of-the-art large language models (LLMs) such as GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra in solving undergraduate-level control problems. Controls provides an interesting case study for LLM reasoning due to its combination of mathematical theory and engineering design. We introduce ControlBench, a benchmark dataset tailored to reflect the breadth, depth, and complexity of classical control design. We use this dataset to study and evaluate the problem-solving abilities of these LLMs in the context of control engineering. We present evaluations conducted by a panel of human experts, providing insights into the accuracy, reasoning, and explanatory prowess of LLMs in control engineering. Our analysis reveals the strengths and limitations of each LLM in the context of classical control, and our results imply that Claude 3 Opus has become the state-of-the-art LLM for solving undergraduate control problems. Our study serves as an initial step towards the broader goal of employing artificial general intelligence in control engineering.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores the abilities of large language models (LLMs) like GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra in solving undergraduate-level control problems.
- Control engineering is an interesting case study for LLM reasoning due to its combination of mathematical theory and engineering design.
- The researchers introduced ControlBench, a benchmark dataset tailored to reflect the breadth, depth, and complexity of classical control design.
- They used this dataset to evaluate the problem-solving abilities of the LLMs in the context of control engineering, with insights from a panel of human experts.
Plain English Explanation
The paper looks at how well the latest and greatest language AI models, like GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra, can solve problems in the field of control engineering. Control engineering is all about designing systems that can automatically regulate and control things, like the temperature in your home or the speed of a robot arm. It involves a mix of mathematical theory and real-world engineering, which makes it an interesting test case for these language models.
The researchers created a new benchmark dataset called ControlBench, which contains a variety of control-related problems that match what you'd see in an undergraduate control engineering course. They then had these language models try to solve the problems and got feedback from human experts in the field to see how well the models did.
The results provide insights into the strengths and limitations of each language model when it comes to control engineering. For example, the paper suggests that Claude 3 Opus has become the best language model for solving these types of undergraduate-level control problems. The findings are an early step towards using advanced AI systems like these language models to help with control engineering tasks in the future.
Technical Explanation
The researchers introduced a new benchmark dataset called ControlBench, which was designed to reflect the breadth, depth, and complexity of classical control design problems. They used this dataset to evaluate the problem-solving abilities of several state-of-the-art large language models (LLMs), including GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra.
The evaluation process involved having a panel of human control engineering experts assess the accuracy, reasoning, and explanatory prowess of the LLMs on the ControlBench problems. The researchers' analysis revealed the relative strengths and limitations of each LLM in the context of classical control engineering.
The results suggest that Claude 3 Opus has become the state-of-the-art LLM for solving undergraduate-level control problems, outperforming the other models tested. This work serves as an initial step towards the broader goal of employing artificial general intelligence (AGI) systems in control engineering applications, as discussed in related research on using LLMs for mathematical tasks and benchmarking LLMs across languages.
Critical Analysis
The paper provides a comprehensive evaluation of the control engineering capabilities of several leading LLMs, which is a valuable contribution to the field. However, the researchers acknowledge that their study is limited to classical control problems and may not fully capture the models' abilities in more advanced or real-world control engineering scenarios.
Additionally, the paper does not delve into potential biases or limitations that may be present in the ControlBench dataset itself. It would be helpful to understand how representative the dataset is of the broader control engineering landscape, and whether there are any blind spots or underrepresented areas.
Further research is also needed to better understand the reasoning and explanatory processes of the LLMs when solving control problems. While the expert evaluations provide useful insights, a more fine-grained analysis of the models' internal workings could yield additional valuable information.
Lastly, the paper focuses on the current state of LLM capabilities in control engineering, but does not extensively explore the potential future implications or applications of this technology. Considering the rapid progress in LLM capabilities for code editing and mathematical reasoning, there may be interesting avenues for further research and development in the control engineering domain.
Conclusion
This paper provides a comprehensive evaluation of the capabilities of state-of-the-art large language models in solving undergraduate-level control engineering problems. The researchers introduced a new benchmark dataset, ControlBench, and used it to assess the accuracy, reasoning, and explanatory prowess of models like GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra.
The results suggest that Claude 3 Opus has become the leading LLM for these types of control engineering tasks, outperforming the other models tested. This work represents an important step towards the broader goal of employing artificial general intelligence systems in control engineering applications, with potential implications for improving the efficiency and effectiveness of control systems across a wide range of industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Sanchit Ahuja, Divyanshu Aggarwal, Varun Gumma, Ishaan Watts, Ashutosh Sathe, Millicent Ochieng, Rishav Hada, Prachi Jain, Maxamed Axmed, Kalika Bali, Sunayana Sitaram
0
0
There has been a surge in LLM evaluation research to understand LLM capabilities and limitations. However, much of this research has been confined to English, leaving LLM building and evaluation for non-English languages relatively unexplored. Several new LLMs have been introduced recently, necessitating their evaluation on non-English languages. This study aims to perform a thorough evaluation of the non-English capabilities of SoTA LLMs (GPT-3.5-Turbo, GPT-4, PaLM2, Gemini-Pro, Mistral, Llama2, and Gemma) by comparing them on the same set of multilingual datasets. Our benchmark comprises 22 datasets covering 83 languages, including low-resource African languages. We also include two multimodal datasets in the benchmark and compare the performance of LLaVA models, GPT-4-Vision and Gemini-Pro-Vision. Our experiments show that larger models such as GPT-4, Gemini-Pro and PaLM2 outperform smaller models on various tasks, notably on low-resource languages, with GPT-4 outperforming PaLM2 and Gemini-Pro on more datasets. We also perform a study on data contamination and find that several models are likely to be contaminated with multilingual evaluation benchmarks, necessitating approaches to detect and handle contamination while assessing the multilingual performance of LLMs.
4/4/2024
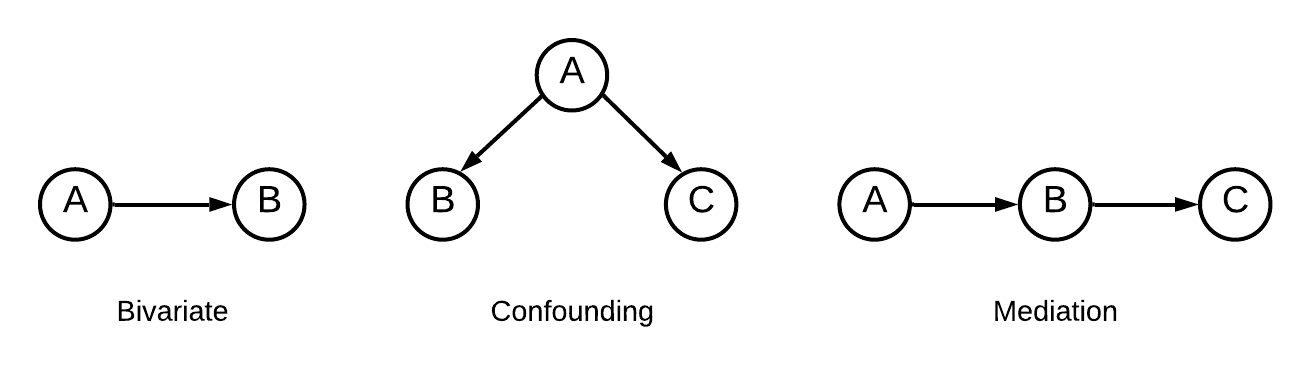
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
0
0
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
4/9/2024
💬
ChatGPT as an inventor: Eliciting the strengths and weaknesses of current large language models against humans in engineering design
Daniel Nyg{aa}rd Ege, Henrik H. {O}vreb{o}, Vegar Stubberud, Martin Francis Berg, Christer Elverum, Martin Steinert, H{aa}vard Vestad
0
0
This study compares the design practices and performance of ChatGPT 4.0, a large language model (LLM), against graduate engineering students in a 48-hour prototyping hackathon, based on a dataset comprising more than 100 prototypes. The LLM participated by instructing two participants who executed its instructions and provided objective feedback, generated ideas autonomously and made all design decisions without human intervention. The LLM exhibited similar prototyping practices to human participants and finished second among six teams, successfully designing and providing building instructions for functional prototypes. The LLM's concept generation capabilities were particularly strong. However, the LLM prematurely abandoned promising concepts when facing minor difficulties, added unnecessary complexity to designs, and experienced design fixation. Communication between the LLM and participants was challenging due to vague or unclear descriptions, and the LLM had difficulty maintaining continuity and relevance in answers. Based on these findings, six recommendations for implementing an LLM like ChatGPT in the design process are proposed, including leveraging it for ideation, ensuring human oversight for key decisions, implementing iterative feedback loops, prompting it to consider alternatives, and assigning specific and manageable tasks at a subsystem level.
4/30/2024

New!A Systematic Evaluation of Large Language Models for Natural Language Generation Tasks
Xuanfan Ni, Piji Li
0
0
Recent efforts have evaluated large language models (LLMs) in areas such as commonsense reasoning, mathematical reasoning, and code generation. However, to the best of our knowledge, no work has specifically investigated the performance of LLMs in natural language generation (NLG) tasks, a pivotal criterion for determining model excellence. Thus, this paper conducts a comprehensive evaluation of well-known and high-performing LLMs, namely ChatGPT, ChatGLM, T5-based models, LLaMA-based models, and Pythia-based models, in the context of NLG tasks. We select English and Chinese datasets encompassing Dialogue Generation and Text Summarization. Moreover, we propose a common evaluation setting that incorporates input templates and post-processing strategies. Our study reports both automatic results, accompanied by a detailed analysis.
5/17/2024