An Evaluation of Explanation Methods for Black-Box Detectors of Machine-Generated Text

0

Sign in to get full access
Overview
- The paper evaluates different explanation methods for black-box models that detect machine-generated text.
- Explanation methods aim to provide insights into how the models make their predictions.
- The authors test the effectiveness of these explanation methods on a range of machine-generated text detectors.
Plain English Explanation
When it comes to machine-generated text detection, there are often complex "black-box" models that make predictions, but it's not always clear how they arrive at those conclusions. Explanation methods are techniques that try to provide more insight into the inner workings of these models.
In this paper, the researchers evaluated different explanation methods to see how well they could help us understand the decision-making process of models that detect machine-generated text. They tested these explanation techniques on a variety of machine-generated text detectors to get a sense of their effectiveness across different types of models.
Technical Explanation
The paper explores the use of explanation methods for black-box detectors of machine-generated text. These detectors use complex models to identify whether a given piece of text was generated by a human or a machine, but the reasons behind their predictions are not always clear.
The authors tested several different explanation methods, including gradient-based saliency maps, layer-wise relevance propagation, and SHAP values. They applied these techniques to a range of machine-generated text detectors, including GLTR, GPT-2 Output Detector, and PPLM.
The researchers evaluated the explanation methods based on their fidelity (how well they aligned with the model's actual decision-making process) and interpretability (how easy they were for humans to understand). They also looked at how the explanation methods performed on different types of machine-generated text, such as those produced by GPT-2 and CTRL.
Critical Analysis
The paper provides a valuable evaluation of explanation methods for black-box machine-generated text detectors. The authors acknowledge that while these explanation techniques can provide useful insights, they also have limitations. For example, the interpretability of the explanations may vary, and the explanations may not always align perfectly with the model's true decision-making process (i.e., they may lack fidelity).
Additionally, the paper notes that the effectiveness of the explanation methods can depend on the specific model and type of machine-generated text being analyzed. This suggests that there may not be a one-size-fits-all explanation method that works equally well for all scenarios.
Further research could explore ways to improve the fidelity and interpretability of these explanation methods, as well as investigate how they perform on an even wider range of machine-generated text detectors and data sources. Developing more robust and generalizable explanation techniques could be an important step in improving the transparency and trustworthiness of these types of AI systems.
Conclusion
This paper presents a comprehensive evaluation of different explanation methods for black-box detectors of machine-generated text. The researchers tested the fidelity and interpretability of techniques like gradient-based saliency maps, layer-wise relevance propagation, and SHAP values on a variety of machine-generated text detection models.
The findings suggest that while these explanation methods can provide useful insights, they also have limitations and their effectiveness can depend on the specific model and type of machine-generated text being analyzed. Continued research in this area could lead to more robust and trustworthy explanations for AI systems that detect machine-generated content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Evaluation of Explanation Methods for Black-Box Detectors of Machine-Generated Text
Loris Schoenegger, Yuxi Xia, Benjamin Roth
The increasing difficulty to distinguish language-model-generated from human-written text has led to the development of detectors of machine-generated text (MGT). However, in many contexts, a black-box prediction is not sufficient, it is equally important to know on what grounds a detector made that prediction. Explanation methods that estimate feature importance promise to provide indications of which parts of an input are used by classifiers for prediction. However, the quality of different explanation methods has not previously been assessed for detectors of MGT. This study conducts the first systematic evaluation of explanation quality for this task. The dimensions of faithfulness and stability are assessed with five automated experiments, and usefulness is evaluated in a user study. We use a dataset of ChatGPT-generated and human-written documents, and pair predictions of three existing language-model-based detectors with the corresponding SHAP, LIME, and Anchor explanations. We find that SHAP performs best in terms of faithfulness, stability, and in helping users to predict the detector's behavior. In contrast, LIME, perceived as most useful by users, scores the worst in terms of user performance at predicting the detectors' behavior.
Read more8/27/2024

0
Evaluating Transparency of Machine Generated Fact Checking Explanations
Rui Xing, Timothy Baldwin, Jey Han Lau
An important factor when it comes to generating fact-checking explanations is the selection of evidence: intuitively, high-quality explanations can only be generated given the right evidence. In this work, we investigate the impact of human-curated vs. machine-selected evidence for explanation generation using large language models. To assess the quality of explanations, we focus on transparency (whether an explanation cites sources properly) and utility (whether an explanation is helpful in clarifying a claim). Surprisingly, we found that large language models generate similar or higher quality explanations using machine-selected evidence, suggesting carefully curated evidence (by humans) may not be necessary. That said, even with the best model, the generated explanations are not always faithful to the sources, suggesting further room for improvement in explanation generation for fact-checking.
Read more6/19/2024
💬
0
FaithLM: Towards Faithful Explanations for Large Language Models
Yu-Neng Chuang, Guanchu Wang, Chia-Yuan Chang, Ruixiang Tang, Shaochen Zhong, Fan Yang, Mengnan Du, Xuanting Cai, Xia Hu
Large Language Models (LLMs) have become proficient in addressing complex tasks by leveraging their extensive internal knowledge and reasoning capabilities. However, the black-box nature of these models complicates the task of explaining their decision-making processes. While recent advancements demonstrate the potential of leveraging LLMs to self-explain their predictions through natural language (NL) explanations, their explanations may not accurately reflect the LLMs' decision-making process due to a lack of fidelity optimization on the derived explanations. Measuring the fidelity of NL explanations is a challenging issue, as it is difficult to manipulate the input context to mask the semantics of these explanations. To this end, we introduce FaithLM to explain the decision of LLMs with NL explanations. Specifically, FaithLM designs a method for evaluating the fidelity of NL explanations by incorporating the contrary explanations to the query process. Moreover, FaithLM conducts an iterative process to improve the fidelity of derived explanations. Experiment results on three datasets from multiple domains demonstrate that FaithLM can significantly improve the fidelity of derived explanations, which also provides a better alignment with the ground-truth explanations.
Read more6/27/2024
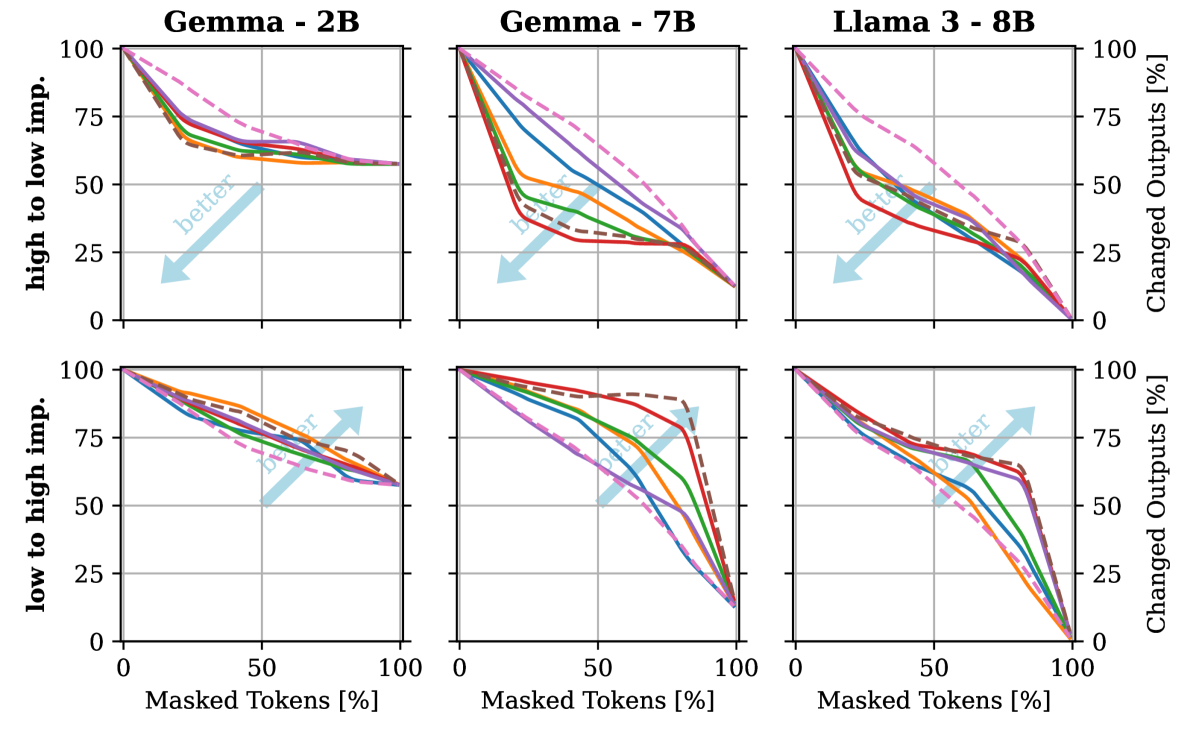
0
Evaluating the Reliability of Self-Explanations in Large Language Models
Korbinian Randl, John Pavlopoulos, Aron Henriksson, Tony Lindgren
This paper investigates the reliability of explanations generated by large language models (LLMs) when prompted to explain their previous output. We evaluate two kinds of such self-explanations - extractive and counterfactual - using three state-of-the-art LLMs (2B to 8B parameters) on two different classification tasks (objective and subjective). Our findings reveal, that, while these self-explanations can correlate with human judgement, they do not fully and accurately follow the model's decision process, indicating a gap between perceived and actual model reasoning. We show that this gap can be bridged because prompting LLMs for counterfactual explanations can produce faithful, informative, and easy-to-verify results. These counterfactuals offer a promising alternative to traditional explainability methods (e.g. SHAP, LIME), provided that prompts are tailored to specific tasks and checked for validity.
Read more7/22/2024