On the Evaluation Practices in Multilingual NLP: Can Machine Translation Offer an Alternative to Human Translations?
2406.14267
0
0

Abstract
While multilingual language models (MLMs) have been trained on 100+ languages, they are typically only evaluated across a handful of them due to a lack of available test data in most languages. This is particularly problematic when assessing MLM's potential for low-resource and unseen languages. In this paper, we present an analysis of existing evaluation frameworks in multilingual NLP, discuss their limitations, and propose several directions for more robust and reliable evaluation practices. Furthermore, we empirically study to what extent machine translation offers a {reliable alternative to human translation} for large-scale evaluation of MLMs across a wide set of languages. We use a SOTA translation model to translate test data from 4 tasks to 198 languages and use them to evaluate three MLMs. We show that while the selected subsets of high-resource test languages are generally sufficiently representative of a wider range of high-resource languages, we tend to overestimate MLMs' ability on low-resource languages. Finally, we show that simpler baselines can achieve relatively strong performance without having benefited from large-scale multilingual pretraining.
Create account to get full access
Overview
- This paper explores the use of machine translation as an alternative to human translations in the evaluation of multilingual natural language processing (NLP) systems.
- The researchers investigate current evaluation practices in multilingual NLP and examine whether machine translation can provide a viable substitute for human translations.
- The paper presents a comprehensive analysis of the benefits and limitations of using machine translation for evaluation, as well as potential ways to improve the reliability and validity of this approach.
Plain English Explanation
When researchers develop NLP systems that can work with multiple languages, they need to evaluate how well these systems perform. Typically, this involves having human translators convert test materials from one language to another so the systems can be assessed across different languages.
However, this paper explores whether machine translation could be used instead of human translators. Machine translation systems have improved dramatically in recent years, and the researchers wanted to see if they could provide a reliable alternative for evaluating multilingual NLP models.
The paper examines the current practices for evaluating multilingual NLP systems and looks at the pros and cons of using machine translation. For example, machine translation could be faster and more cost-effective than human translators, but it may not capture nuances and context as well. The researchers aim to provide guidance on when machine translation could be a suitable replacement and how to ensure the evaluation remains valid and reliable.
By considering machine translation as an evaluation tool, the researchers hope to make the process of developing multilingual NLP systems more efficient and accessible, especially for tasks like multilingual machine translation and multilingual text classification.
Technical Explanation
The paper begins by outlining the current evaluation practices in multilingual NLP, which typically rely on human translators to create test materials in multiple languages. The researchers then explore the potential of using machine translation as an alternative approach.
To assess the viability of machine translation, the paper examines several key factors, including:
-
Translation Quality: The researchers analyze the accuracy and fluency of machine translations compared to human translations, considering factors like linguistic nuance and contextual understanding.
-
Evaluation Reliability: The paper investigates whether machine-translated test materials can still provide a reliable assessment of multilingual NLP systems, compared to using human translations.
-
Evaluation Validity: The researchers explore whether the use of machine translation might introduce biases or other threats to the validity of the evaluation process.
The paper also discusses strategies for improving the reliability and validity of machine translation-based evaluations, such as using ensemble models or incorporating human feedback to enhance the translation quality.
Additionally, the researchers highlight the potential benefits of using machine translation, including increased efficiency, cost-effectiveness, and the ability to scale evaluation efforts across a broader range of languages.
Critical Analysis
The paper presents a thorough and well-reasoned analysis of the use of machine translation in the evaluation of multilingual NLP systems. The researchers acknowledge several limitations and areas for further research, such as the need to explore the impact of different machine translation models and the potential for domain-specific biases.
One potential concern raised is the possibility that machine translation may not capture the nuances and contextual information that human translators can provide. This could lead to biases or inaccuracies in the evaluation process, particularly for tasks that require a deep understanding of language and culture.
Additionally, the paper does not address the potential challenges of ensuring the fairness and ethical use of machine translation in evaluation contexts. As these systems can reflect societal biases and may not perform equally well across different languages or demographics, further research is needed to understand and mitigate these issues.
Despite these limitations, the paper offers a valuable contribution to the field by exploring an alternative approach to the evaluation of multilingual NLP systems. The researchers provide a thoughtful framework for assessing the viability of machine translation and offer practical guidance for researchers and practitioners.
Conclusion
This paper presents a comprehensive investigation into the use of machine translation as an alternative to human translations in the evaluation of multilingual NLP systems. The researchers provide a detailed analysis of the potential benefits and limitations of this approach, offering insights that can inform the development and assessment of multilingual language models and other multilingual NLP technologies.
By considering machine translation as an evaluation tool, the paper opens up new possibilities for making the development of multilingual NLP systems more efficient and accessible. The researchers' findings can help guide future research and practices in this important area, ultimately contributing to the advancement of multilingual NLP capabilities and their applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Chaoqun Liu, Wenxuan Zhang, Yiran Zhao, Anh Tuan Luu, Lidong Bing
0
0
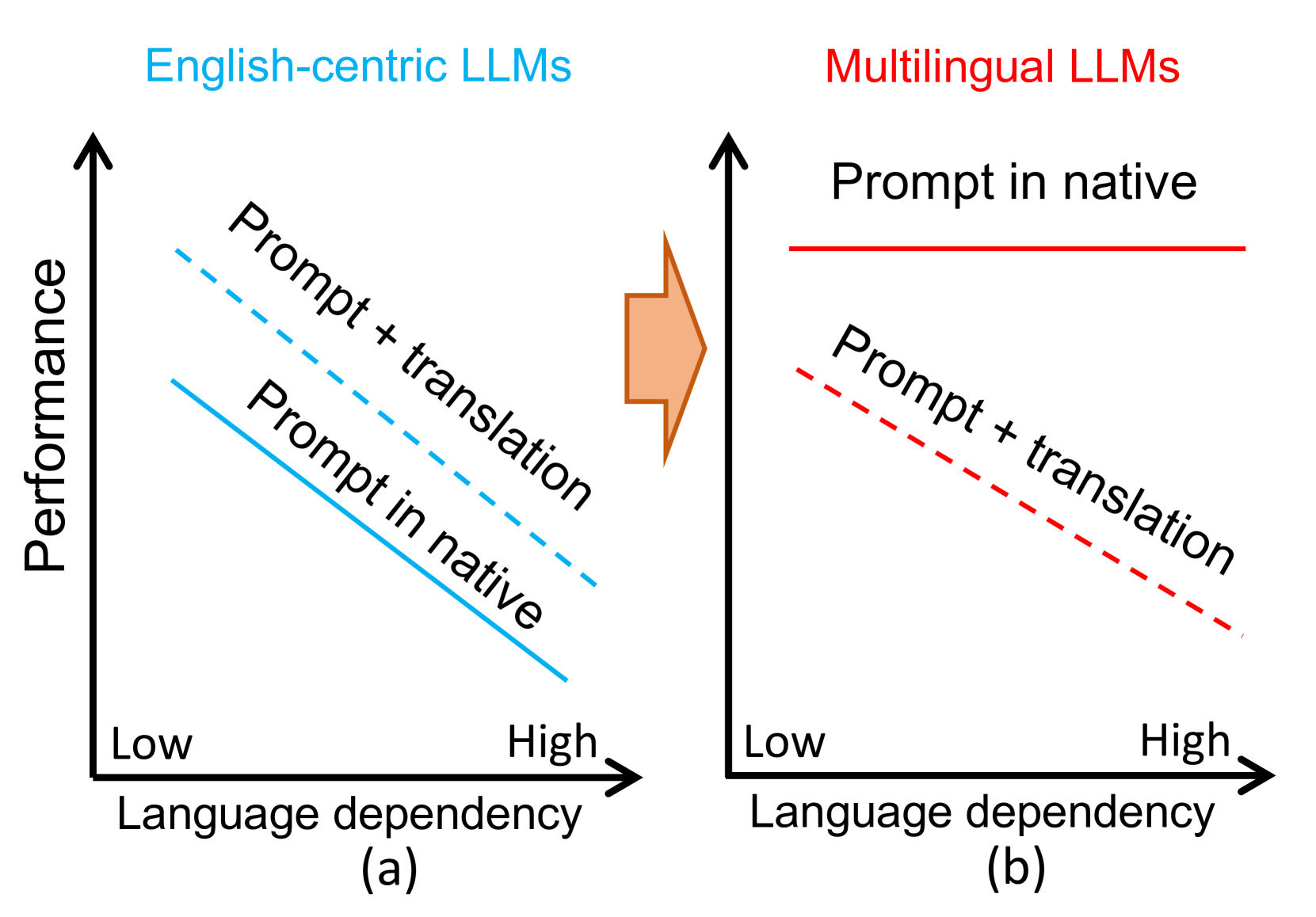
Large language models (LLMs) have demonstrated multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances through translation, primarily on natural language processing (NLP) tasks. This work extends the evaluation from NLP tasks to real user queries and from English-centric LLMs to non-English-centric LLMs. While translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language tends to be more promising as it better captures the nuances of culture and language. Our experiments reveal varied behaviors among different LLMs and tasks in the multilingual context. Therefore, we advocate for more comprehensive multilingual evaluation and more efforts toward developing multilingual LLMs beyond English-centric ones.
6/21/2024
💬
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
0
0
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
6/17/2024
🏷️
Using Machine Translation to Augment Multilingual Classification
Adam King
0
0
An all-too-present bottleneck for text classification model development is the need to annotate training data and this need is multiplied for multilingual classifiers. Fortunately, contemporary machine translation models are both easily accessible and have dependable translation quality, making it possible to translate labeled training data from one language into another. Here, we explore the effects of using machine translation to fine-tune a multilingual model for a classification task across multiple languages. We also investigate the benefits of using a novel technique, originally proposed in the field of image captioning, to account for potential negative effects of tuning models on translated data. We show that translated data are of sufficient quality to tune multilingual classifiers and that this novel loss technique is able to offer some improvement over models tuned without it.
5/10/2024
Spanish and LLM Benchmarks: is MMLU Lost in Translation?
Irene Plaza, Nina Melero, Cristina del Pozo, Javier Conde, Pedro Reviriego, Marina Mayor-Rocher, Mar'ia Grandury
0
0
The evaluation of Large Language Models (LLMs) is a key element in their continuous improvement process and many benchmarks have been developed to assess the performance of LLMs in different tasks and topics. As LLMs become adopted worldwide, evaluating them in languages other than English is increasingly important. However, most LLM benchmarks are simply translated using an automated tool and then run in the target language. This means that the results depend not only on the LLM performance in that language but also on the quality of the translation. In this paper, we consider the case of the well-known Massive Multitask Language Understanding (MMLU) benchmark. Selected categories of the benchmark are translated into Spanish using Azure Translator and ChatGPT4 and run on ChatGPT4. Next, the results are processed to identify the test items that produce different answers in Spanish and English. Those are then analyzed manually to understand if the automatic translation caused the change. The results show that a significant fraction of the failing items can be attributed to mistakes in the translation of the benchmark. These results make a strong case for improving benchmarks in languages other than English by at least revising the translations of the items and preferably by adapting the tests to the target language by experts.
6/27/2024