How Multilingual Are Large Language Models Fine-Tuned for Translation?

0
Sign in to get full access
Overview
- The paper examines the multilingual capabilities of large language models fine-tuned for translation tasks.
- It evaluates the models' performance across a diverse set of language pairs and identifies factors that impact their translation quality.
- The findings provide insights into the challenges and limitations of using these models for multilingual translation.
Plain English Explanation
The paper looks at how well large language models that have been specially trained for translation work with multiple languages. These models are very capable at understanding and generating natural language, but the researchers wanted to test how well they can actually translate between different languages.
They evaluated the models' performance on a wide range of language pairs, from common ones like English-Spanish to less common ones like Hausa-Norwegian. This allowed them to identify which factors, like the language pair or the amount of training data, had the biggest impact on the quality of the translations.
The results provide important insights into the strengths and limitations of using these large language models for multilingual translation tasks. While they can be quite effective, there are still challenges, especially for language pairs with fewer available training resources. This information can help guide future research and development in this area.
Technical Explanation
The researchers conducted a comprehensive evaluation of the multilingual translation capabilities of large language models that had been fine-tuned on translation tasks. They assessed the models' performance across a diverse set of language pairs, including both high-resource and low-resource languages.
The experiment design involved evaluating the models on standardized translation benchmarks covering a wide range of language combinations. This allowed them to identify factors like language similarity, data availability, and model architecture that influenced the translation quality.
The results showed that while the fine-tuned models demonstrated strong multilingual abilities, there were significant disparities in performance across language pairs. Factors like language family and dataset size had a substantial impact on the models' translation quality. The researchers also observed interesting patterns, such as an asymmetry in translation performance between language directions.
These findings provide important insights into the nuanced multilingual capabilities of large language models and the challenges involved in deploying them for real-world multilingual translation tasks. The analysis underscores the need for further research and development to address the limitations and inconsistencies identified in the study.
Critical Analysis
The paper offers a rigorous and systematic evaluation of the multilingual translation abilities of fine-tuned large language models. By assessing a diverse set of language pairs, the researchers were able to identify key factors that influence translation quality, which is a valuable contribution to the field.
However, the study does not delve deeply into the specific architectural or training details of the models evaluated. A more detailed analysis of how the model design and training process impact multilingual performance could provide additional insights.
Additionally, the paper does not address the potential ethical and societal implications of deploying these models for translation tasks, such as concerns around bias, fairness, and the preservation of linguistic diversity. Exploring these aspects could be an important area for future research.
Overall, the paper presents a solid technical evaluation and highlights the need for continued advancements to address the limitations of current multilingual translation models. Encouraging further critical analysis and discussion around these issues can help drive the field forward in a responsible and impactful way.
Conclusion
This paper provides a comprehensive assessment of the multilingual translation capabilities of large language models that have been fine-tuned for translation tasks. The findings reveal that while these models demonstrate impressive multilingual abilities, there are significant disparities in their performance across different language pairs.
The researchers identify key factors, such as language similarity and data availability, that heavily influence the translation quality. These insights are valuable for guiding future research and development efforts to improve the multilingual capabilities of large language models and make them more reliable and robust for real-world translation applications.
Ultimately, this study underscores the importance of continued exploration and critical examination of the strengths, limitations, and societal implications of using these powerful language models for multilingual translation. By addressing the challenges highlighted in this paper, the field can work towards more equitable and effective multilingual translation solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How Multilingual Are Large Language Models Fine-Tuned for Translation?
Aquia Richburg, Marine Carpuat
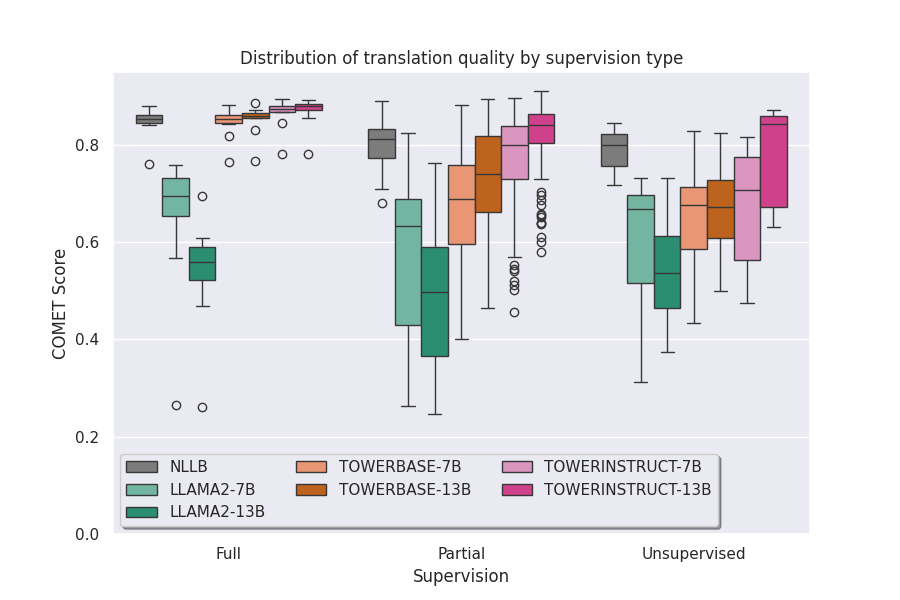
A new paradigm for machine translation has recently emerged: fine-tuning large language models (LLM) on parallel text has been shown to outperform dedicated translation systems trained in a supervised fashion on much larger amounts of parallel data (Xu et al., 2024a; Alves et al., 2024). However, it remains unclear whether this paradigm can enable massively multilingual machine translation or whether it requires fine-tuning dedicated models for a small number of language pairs. How does translation fine-tuning impact the MT capabilities of LLMs for zero-shot languages, zero-shot language pairs, and translation tasks that do not involve English? To address these questions, we conduct an extensive empirical evaluation of the translation quality of the TOWER family of language models (Alves et al., 2024) on 132 translation tasks from the multi-parallel FLORES-200 data. We find that translation fine-tuning improves translation quality even for zero-shot languages on average, but that the impact is uneven depending on the language pairs involved. These results call for further research to effectively enable massively multilingual translation with LLMs.
Read more6/3/2024
0
The Fine-Tuning Paradox: Boosting Translation Quality Without Sacrificing LLM Abilities
David Stap, Eva Hasler, Bill Byrne, Christof Monz, Ke Tran
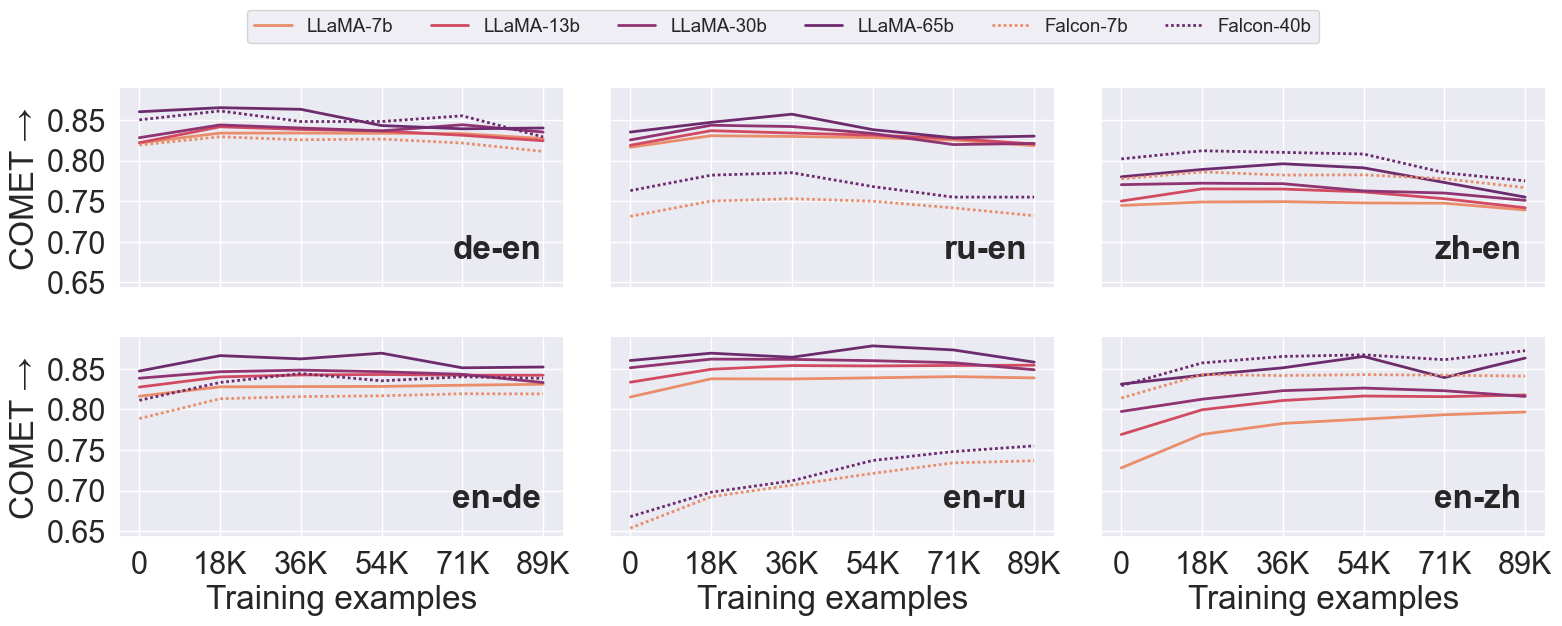
Fine-tuning large language models (LLMs) for machine translation has shown improvements in overall translation quality. However, it is unclear what is the impact of fine-tuning on desirable LLM behaviors that are not present in neural machine translation models, such as steerability, inherent document-level translation abilities, and the ability to produce less literal translations. We perform an extensive translation evaluation on the LLaMA and Falcon family of models with model size ranging from 7 billion up to 65 billion parameters. Our results show that while fine-tuning improves the general translation quality of LLMs, several abilities degrade. In particular, we observe a decline in the ability to perform formality steering, to produce technical translations through few-shot examples, and to perform document-level translation. On the other hand, we observe that the model produces less literal translations after fine-tuning on parallel data. We show that by including monolingual data as part of the fine-tuning data we can maintain the abilities while simultaneously enhancing overall translation quality. Our findings emphasize the need for fine-tuning strategies that preserve the benefits of LLMs for machine translation.
Read more8/7/2024

0
A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
Read more4/16/2024
💬
0
Investigating the translation capabilities of Large Language Models trained on parallel data only
Javier Garc'ia Gilabert, Carlos Escolano, Aleix Sant Savall, Francesca De Luca Fornaciari, Audrey Mash, Xixian Liao, Maite Melero
In recent years, Large Language Models (LLMs) have demonstrated exceptional proficiency across a broad spectrum of Natural Language Processing (NLP) tasks, including Machine Translation. However, previous methods predominantly relied on iterative processes such as instruction fine-tuning or continual pre-training, leaving unexplored the challenges of training LLMs solely on parallel data. In this work, we introduce PLUME (Parallel Language Model), a collection of three 2B LLMs featuring varying vocabulary sizes (32k, 128k, and 256k) trained exclusively on Catalan-centric parallel examples. These models perform comparably to previous encoder-decoder architectures on 16 supervised translation directions and 56 zero-shot ones. Utilizing this set of models, we conduct a thorough investigation into the translation capabilities of LLMs, probing their performance, the impact of the different elements of the prompt, and their cross-lingual representation space.
Read more6/14/2024