Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
2403.10258
0
0
Abstract
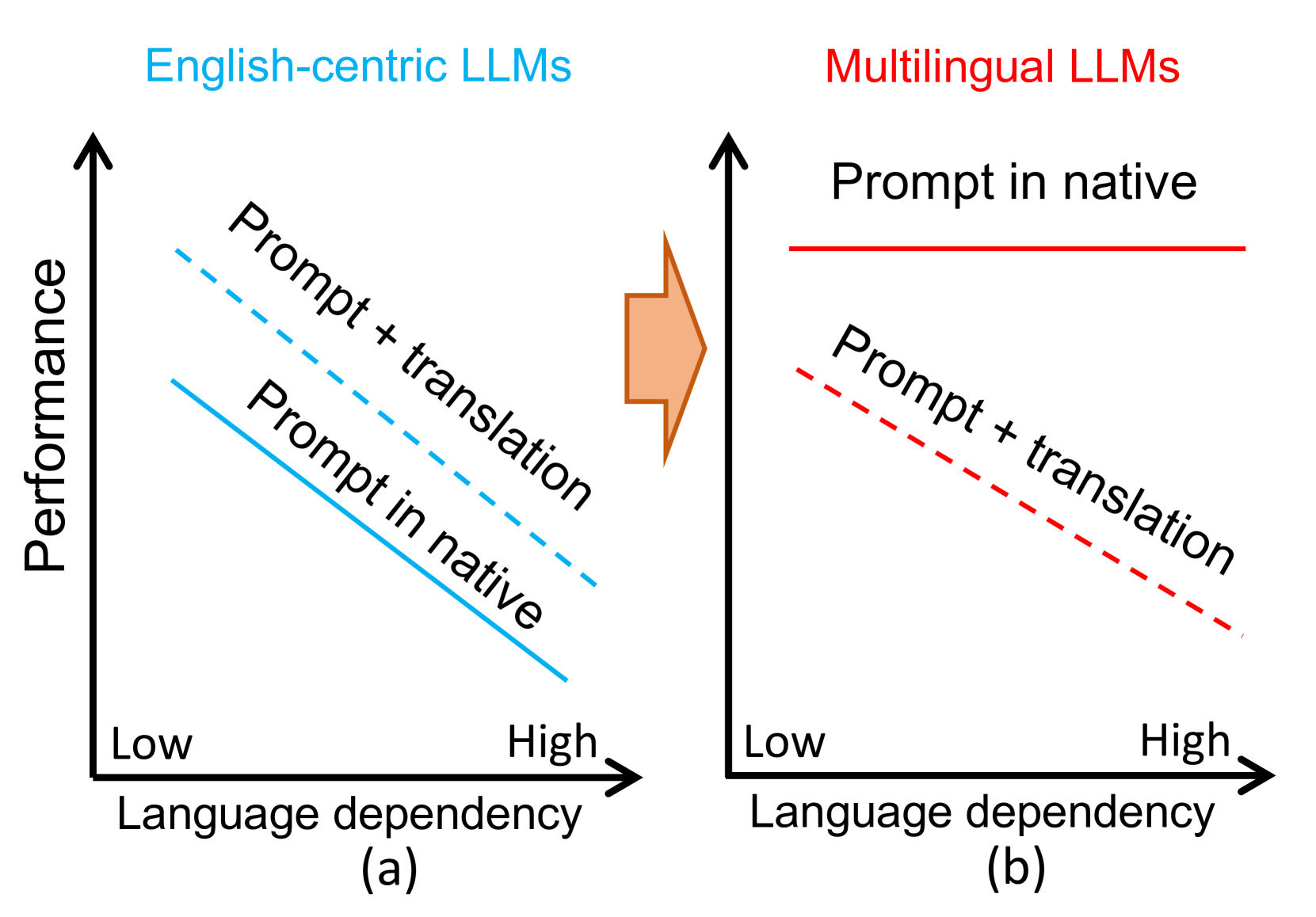
Large language models (LLMs) have demonstrated multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances through translation, primarily on natural language processing (NLP) tasks. This work extends the evaluation from NLP tasks to real user queries and from English-centric LLMs to non-English-centric LLMs. While translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language tends to be more promising as it better captures the nuances of culture and language. Our experiments reveal varied behaviors among different LLMs and tasks in the multilingual context. Therefore, we advocate for more comprehensive multilingual evaluation and more efforts toward developing multilingual LLMs beyond English-centric ones.
Create account to get full access
Overview
- This paper explores the effectiveness of using large language models (LLMs) for solving multilingual natural language processing (NLP) tasks without relying on translation.
- The researchers investigate whether LLMs can directly handle multiple languages, or if translation is still necessary for optimal performance.
- The study compares the performance of LLMs on various multilingual NLP tasks with and without translation, providing insights into the capabilities and limitations of LLMs in this context.
Plain English Explanation
In the field of natural language processing (NLP), researchers are constantly exploring ways to enable machines to understand and communicate in multiple languages. One approach is to use large language models, which are powerful AI systems trained on vast amounts of text data. These models can potentially learn to handle multiple languages without the need for explicit translation.
This paper investigates whether LLMs can directly solve multilingual NLP tasks or if translation is still necessary for optimal performance. The researchers designed experiments to compare the performance of LLMs on various tasks, such as text classification and question answering, when using the original text versus translated text.
The findings provide insights into the capabilities and limitations of LLMs in handling multilingual data. The results suggest that while LLMs can indeed perform reasonably well on some multilingual tasks without translation, translation can still provide a significant boost in performance for certain tasks and language combinations. This highlights the ongoing challenges and opportunities in developing truly multilingual language models.
Technical Explanation
The researchers conducted experiments to evaluate the performance of large language models (LLMs) on various multilingual NLP tasks, comparing their performance with and without the use of translation. The study setup involved using the multilingual version of the BERT language model (mBERT) and the XLM-R model, which are two widely used LLMs capable of handling multiple languages.
The researchers selected a diverse set of multilingual NLP tasks, including text classification, question answering, and natural language inference. They evaluated the models' performance on these tasks in two settings: one where the input text was directly used, and another where the text was first translated into English using a machine translation system.
The results showed that while the LLMs were able to achieve reasonable performance on the multilingual tasks without translation, the use of translation often led to significant improvements in performance. The extent of the performance boost varied across tasks and language pairs, suggesting that the ability of LLMs to directly handle multiple languages is still limited compared to the benefits of translation.
The researchers also analyzed the factors that might contribute to the performance differences, such as the linguistic proximity of the languages, the quality of the translation system, and the inherent biases and limitations of the LLMs themselves.
Critical Analysis
The study provides valuable insights into the current capabilities and limitations of large language models in handling multilingual data. While the results suggest that LLMs can perform reasonably well on some multilingual tasks without translation, the performance boost obtained through translation highlights the ongoing challenges in developing truly multilingual language models.
One potential limitation of the study is that it focuses on a relatively small set of tasks and language pairs. Expanding the research to a wider range of tasks and language combinations could provide a more comprehensive understanding of the LLMs' multilingual capabilities. Additionally, the study does not delve into the specific factors that contribute to the performance differences, such as the quality of the translation system or the inherent biases in the LLM training data.
Further research is needed to address these limitations and explore alternative approaches to improving the multilingual capabilities of LLMs. This could involve investigating more advanced techniques for multilingual model training, leveraging cross-lingual transfer learning, or developing novel architectures specifically designed for multilingual processing.
Conclusion
This paper provides a valuable contribution to the ongoing research on the use of large language models for multilingual natural language processing tasks. The findings suggest that while LLMs can handle some multilingual tasks directly, translation can still provide significant performance improvements in many cases.
The study highlights the challenges and opportunities in developing truly multilingual language models, which have important implications for a wide range of applications, from machine translation to cross-lingual information retrieval and knowledge sharing. As the field of natural language processing continues to advance, further research in this area will be crucial for enabling more robust and inclusive multilingual AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models are Good Spontaneous Multilingual Learners: Is the Multilingual Annotated Data Necessary?
Shimao Zhang, Changjiang Gao, Wenhao Zhu, Jiajun Chen, Xin Huang, Xue Han, Junlan Feng, Chao Deng, Shujian Huang
0
0
Recently, Large Language Models (LLMs) have shown impressive language capabilities. While most of the existing LLMs have very unbalanced performance across different languages, multilingual alignment based on translation parallel data is an effective method to enhance the LLMs' multilingual capabilities. In this work, we discover and comprehensively investigate the spontaneous multilingual alignment improvement of LLMs. We find that LLMs instruction-tuned on the question translation data (i.e. without annotated answers) are able to encourage the alignment between English and a wide range of languages, even including those unseen during instruction-tuning. Additionally, we utilize different settings and mechanistic interpretability methods to analyze the LLM's performance in the multilingual scenario comprehensively. Our work suggests that LLMs have enormous potential for improving multilingual alignment efficiently with great language and task generalization.
6/19/2024
Could We Have Had Better Multilingual LLMs If English Was Not the Central Language?
Ryandito Diandaru, Lucky Susanto, Zilu Tang, Ayu Purwarianti, Derry Wijaya
0
0
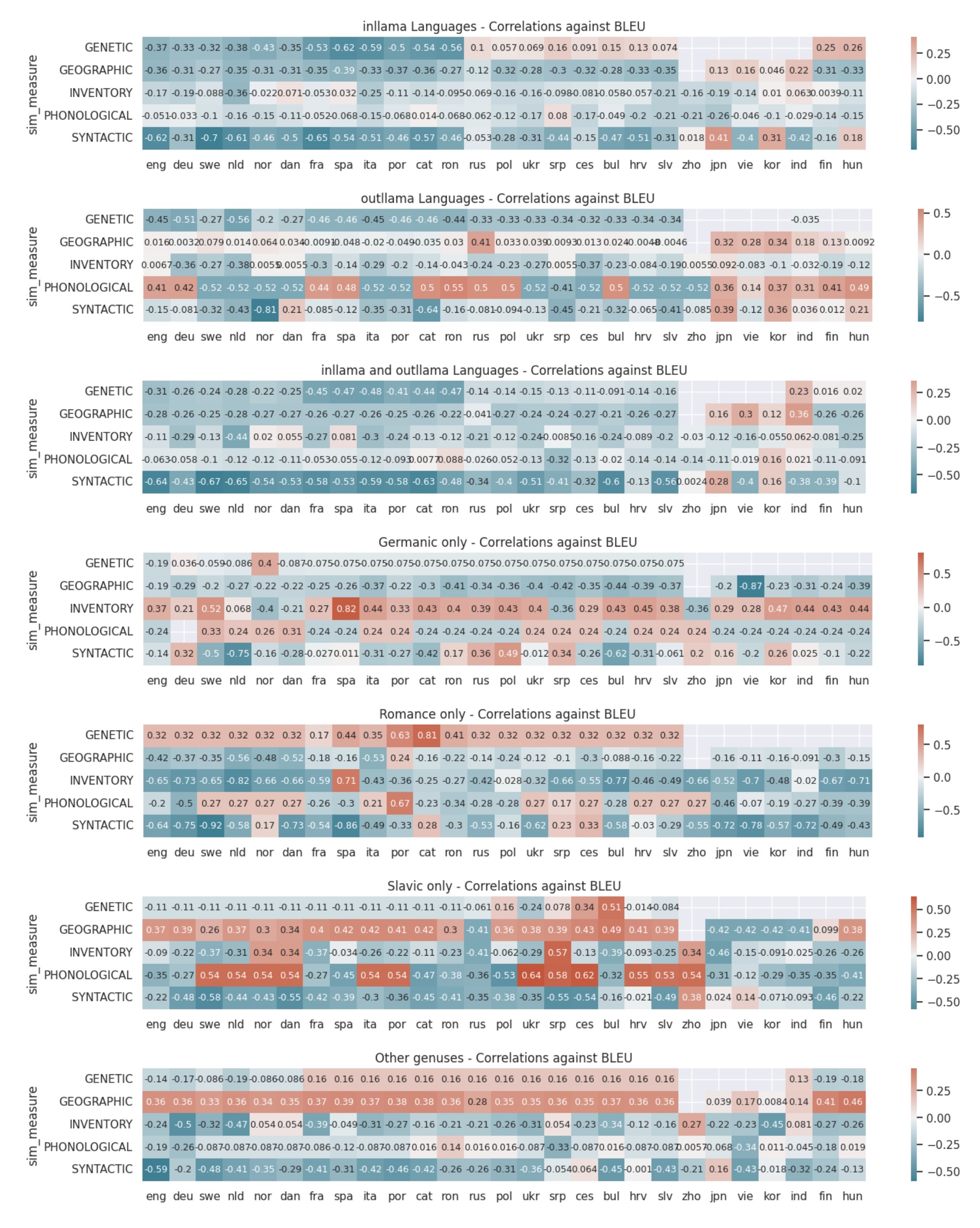
Large Language Models (LLMs) demonstrate strong machine translation capabilities on languages they are trained on. However, the impact of factors beyond training data size on translation performance remains a topic of debate, especially concerning languages not directly encountered during training. Our study delves into Llama2's translation capabilities. By modeling a linear relationship between linguistic feature distances and machine translation scores, we ask ourselves if there are potentially better central languages for LLMs other than English. Our experiments show that the 7B Llama2 model yields above 10 BLEU when translating into all languages it has seen, which rarely happens for languages it has not seen. Most translation improvements into unseen languages come from scaling up the model size rather than instruction tuning or increasing shot count. Furthermore, our correlation analysis reveals that syntactic similarity is not the only linguistic factor that strongly correlates with machine translation scores. Interestingly, we discovered that under specific circumstances, some languages (e.g. Swedish, Catalan), despite having significantly less training data, exhibit comparable correlation levels to English. These insights challenge the prevailing landscape of LLMs, suggesting that models centered around languages other than English could provide a more efficient foundation for multilingual applications.
4/8/2024
A Survey on Multilingual Large Language Models: Corpora, Alignment, and Bias
Yuemei Xu, Ling Hu, Jiayi Zhao, Zihan Qiu, Yuqi Ye, Hanwen Gu
0
0
Based on the foundation of Large Language Models (LLMs), Multilingual Large Language Models (MLLMs) have been developed to address the challenges of multilingual natural language processing tasks, hoping to achieve knowledge transfer from high-resource to low-resource languages. However, significant limitations and challenges still exist, such as language imbalance, multilingual alignment, and inherent bias. In this paper, we aim to provide a comprehensive analysis of MLLMs, delving deeply into discussions surrounding these critical issues. First of all, we start by presenting an overview of MLLMs, covering their evolution, key techniques, and multilingual capacities. Secondly, we explore widely utilized multilingual corpora for MLLMs' training and multilingual datasets oriented for downstream tasks that are crucial for enhancing the cross-lingual capability of MLLMs. Thirdly, we survey the existing studies on multilingual representations and investigate whether the current MLLMs can learn a universal language representation. Fourthly, we discuss bias on MLLMs including its category and evaluation metrics, and summarize the existing debiasing techniques. Finally, we discuss existing challenges and point out promising research directions. By demonstrating these aspects, this paper aims to facilitate a deeper understanding of MLLMs and their potentiality in various domains.
6/7/2024
A Survey on Large Language Models with Multilingualism: Recent Advances and New Frontiers
Kaiyu Huang, Fengran Mo, Hongliang Li, You Li, Yuanchi Zhang, Weijian Yi, Yulong Mao, Jinchen Liu, Yuzhuang Xu, Jinan Xu, Jian-Yun Nie, Yang Liu
0
0
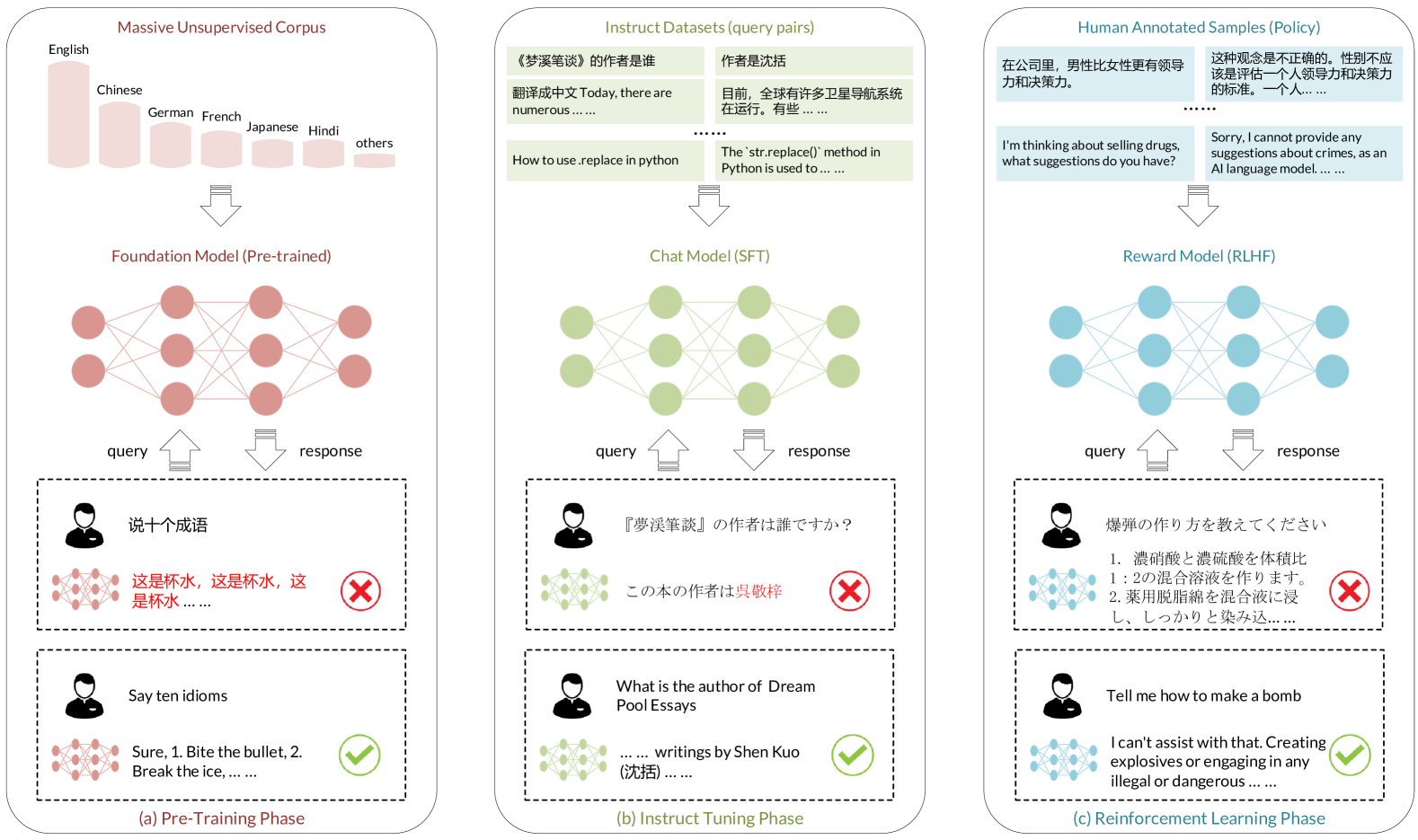
The rapid development of Large Language Models (LLMs) demonstrates remarkable multilingual capabilities in natural language processing, attracting global attention in both academia and industry. To mitigate potential discrimination and enhance the overall usability and accessibility for diverse language user groups, it is important for the development of language-fair technology. Despite the breakthroughs of LLMs, the investigation into the multilingual scenario remains insufficient, where a comprehensive survey to summarize recent approaches, developments, limitations, and potential solutions is desirable. To this end, we provide a survey with multiple perspectives on the utilization of LLMs in the multilingual scenario. We first rethink the transitions between previous and current research on pre-trained language models. Then we introduce several perspectives on the multilingualism of LLMs, including training and inference methods, model security, multi-domain with language culture, and usage of datasets. We also discuss the major challenges that arise in these aspects, along with possible solutions. Besides, we highlight future research directions that aim at further enhancing LLMs with multilingualism. The survey aims to help the research community address multilingual problems and provide a comprehensive understanding of the core concepts, key techniques, and latest developments in multilingual natural language processing based on LLMs.
5/20/2024