Spanish and LLM Benchmarks: is MMLU Lost in Translation?
2406.17789
0
0
Abstract
The evaluation of Large Language Models (LLMs) is a key element in their continuous improvement process and many benchmarks have been developed to assess the performance of LLMs in different tasks and topics. As LLMs become adopted worldwide, evaluating them in languages other than English is increasingly important. However, most LLM benchmarks are simply translated using an automated tool and then run in the target language. This means that the results depend not only on the LLM performance in that language but also on the quality of the translation. In this paper, we consider the case of the well-known Massive Multitask Language Understanding (MMLU) benchmark. Selected categories of the benchmark are translated into Spanish using Azure Translator and ChatGPT4 and run on ChatGPT4. Next, the results are processed to identify the test items that produce different answers in Spanish and English. Those are then analyzed manually to understand if the automatic translation caused the change. The results show that a significant fraction of the failing items can be attributed to mistakes in the translation of the benchmark. These results make a strong case for improving benchmarks in languages other than English by at least revising the translations of the items and preferably by adapting the tests to the target language by experts.
Create account to get full access
Overview
- Investigates the performance of large language models (LLMs) on the Multimodal Multiple-Choice Question Answering (MMLU) benchmark, with a focus on Spanish-language performance
- Examines whether translation is sufficient for achieving strong performance on MMLU in languages other than English
- Explores potential biases and limitations in MMLU that could lead to performance disparities across languages
Plain English Explanation
This paper looks at how well large language models (LLMs) - powerful AI systems that can understand and generate human-like text - perform on a benchmark called MMLU. MMLU is a test that asks multiple-choice questions on a wide range of topics, and is designed to measure how well these models can reason and understand information.
The researchers were particularly interested in how LLMs do on the Spanish-language version of MMLU. They wanted to see if simply translating the English MMLU content into Spanish is enough for the models to perform well, or if there are deeper cultural and linguistic factors that affect their performance.
The key finding is that translation alone may not be enough - the researchers discovered some potential biases and limitations in the MMLU benchmark that could lead to large discrepancies in performance between English and Spanish. This suggests that building truly multilingual AI models that can perform well across different languages and cultures remains a significant challenge.
Technical Explanation
The paper begins by introducing the Multimodal Multiple-Choice Question Answering (MMLU) benchmark, which tests the reasoning and knowledge capabilities of large language models across a diverse set of topics. The authors then describe their experiment of evaluating several popular LLMs, including GPT-3, BLOOM, and PaLM, on both the English and Spanish versions of MMLU.
Their results show that while the models perform well on the English MMLU, their performance drops significantly on the Spanish version. The authors hypothesize that this gap may be due to issues with the translation process or inherent cultural biases in the MMLU dataset itself.
To further investigate this, the researchers conduct additional analyses, including examining the relationship between model performance and linguistic features of the MMLU questions. Their findings suggest that the MMLU benchmark may not be equally suitable for evaluating LLM capabilities across different languages and cultural contexts.
Critical Analysis
The paper raises important questions about the validity and cultural sensitivity of benchmarks like MMLU when used to assess multilingual AI systems. While the authors acknowledge the challenges of creating truly representative and unbiased datasets, their findings highlight the need for more rigorous evaluation of how these models perform across diverse linguistic and cultural contexts.
One potential limitation of the study is that it focuses only on a single benchmark (MMLU) and a small set of LLMs. It would be valuable to see a broader analysis that incorporates other benchmarks and a wider range of models to better understand the generalizability of the issues identified.
Additionally, the authors do not offer specific recommendations for how the MMLU benchmark or the development of multilingual LLMs could be improved. Further research into more inclusive and culturally-aware evaluation approaches could provide valuable insights for the field.
Conclusion
This paper highlights the challenges of building and evaluating truly multilingual AI systems, using the MMLU benchmark as a case study. The authors' findings suggest that simply translating existing benchmarks may not be enough to ensure fair and accurate assessment of LLM performance across languages and cultures.
Their work underscores the importance of developing more representative and culturally-sensitive evaluation frameworks for multilingual AI. Addressing these issues will be crucial as the field of large language models continues to advance and these systems are increasingly deployed in real-world applications serving diverse global audiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
0
0
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
6/17/2024
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Chaoqun Liu, Wenxuan Zhang, Yiran Zhao, Anh Tuan Luu, Lidong Bing
0
0
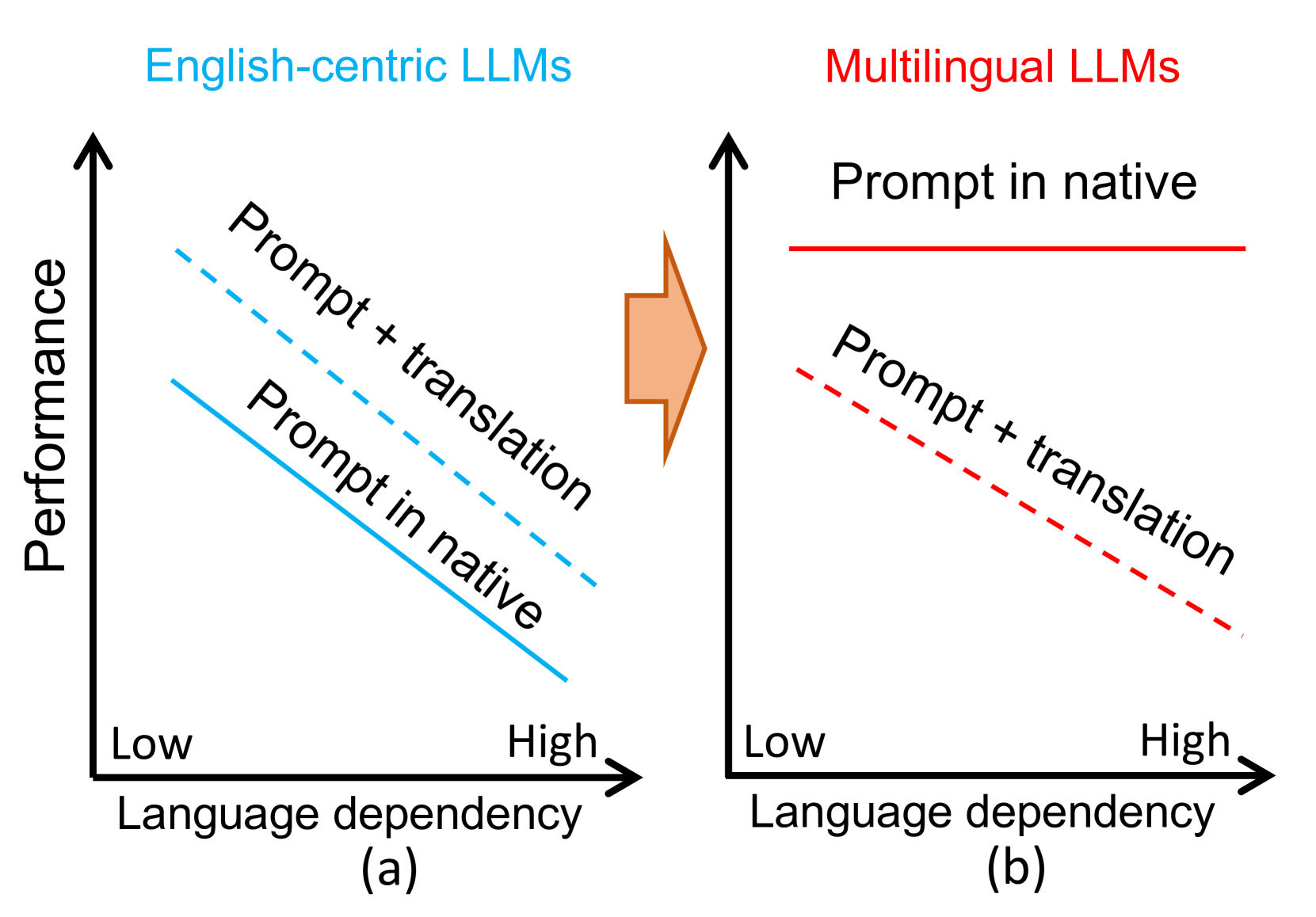
Large language models (LLMs) have demonstrated multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances through translation, primarily on natural language processing (NLP) tasks. This work extends the evaluation from NLP tasks to real user queries and from English-centric LLMs to non-English-centric LLMs. While translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language tends to be more promising as it better captures the nuances of culture and language. Our experiments reveal varied behaviors among different LLMs and tasks in the multilingual context. Therefore, we advocate for more comprehensive multilingual evaluation and more efforts toward developing multilingual LLMs beyond English-centric ones.
6/21/2024
Beyond Metrics: Evaluating LLMs' Effectiveness in Culturally Nuanced, Low-Resource Real-World Scenarios
Millicent Ochieng, Varun Gumma, Sunayana Sitaram, Jindong Wang, Vishrav Chaudhary, Keshet Ronen, Kalika Bali, Jacki O'Neill
0
0
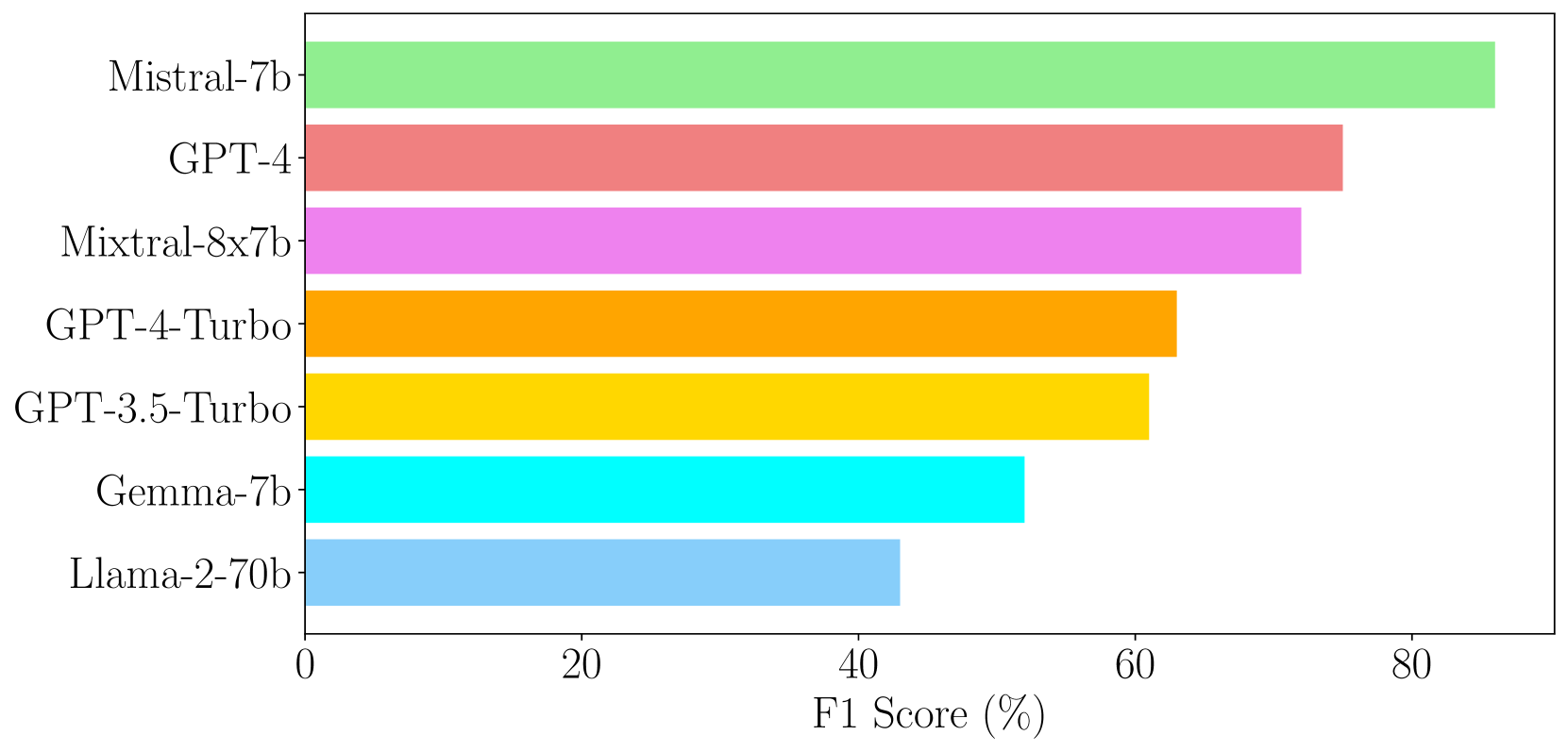
The deployment of Large Language Models (LLMs) in real-world applications presents both opportunities and challenges, particularly in multilingual and code-mixed communication settings. This research evaluates the performance of seven leading LLMs in sentiment analysis on a dataset derived from multilingual and code-mixed WhatsApp chats, including Swahili, English and Sheng. Our evaluation includes both quantitative analysis using metrics like F1 score and qualitative assessment of LLMs' explanations for their predictions. We find that, while Mistral-7b and Mixtral-8x7b achieved high F1 scores, they and other LLMs such as GPT-3.5-Turbo, Llama-2-70b, and Gemma-7b struggled with understanding linguistic and contextual nuances, as well as lack of transparency in their decision-making process as observed from their explanations. In contrast, GPT-4 and GPT-4-Turbo excelled in grasping diverse linguistic inputs and managing various contextual information, demonstrating high consistency with human alignment and transparency in their decision-making process. The LLMs however, encountered difficulties in incorporating cultural nuance especially in non-English settings with GPT-4s doing so inconsistently. The findings emphasize the necessity of continuous improvement of LLMs to effectively tackle the challenges of culturally nuanced, low-resource real-world settings and the need for developing evaluation benchmarks for capturing these issues.
6/14/2024
Could We Have Had Better Multilingual LLMs If English Was Not the Central Language?
Ryandito Diandaru, Lucky Susanto, Zilu Tang, Ayu Purwarianti, Derry Wijaya
0
0
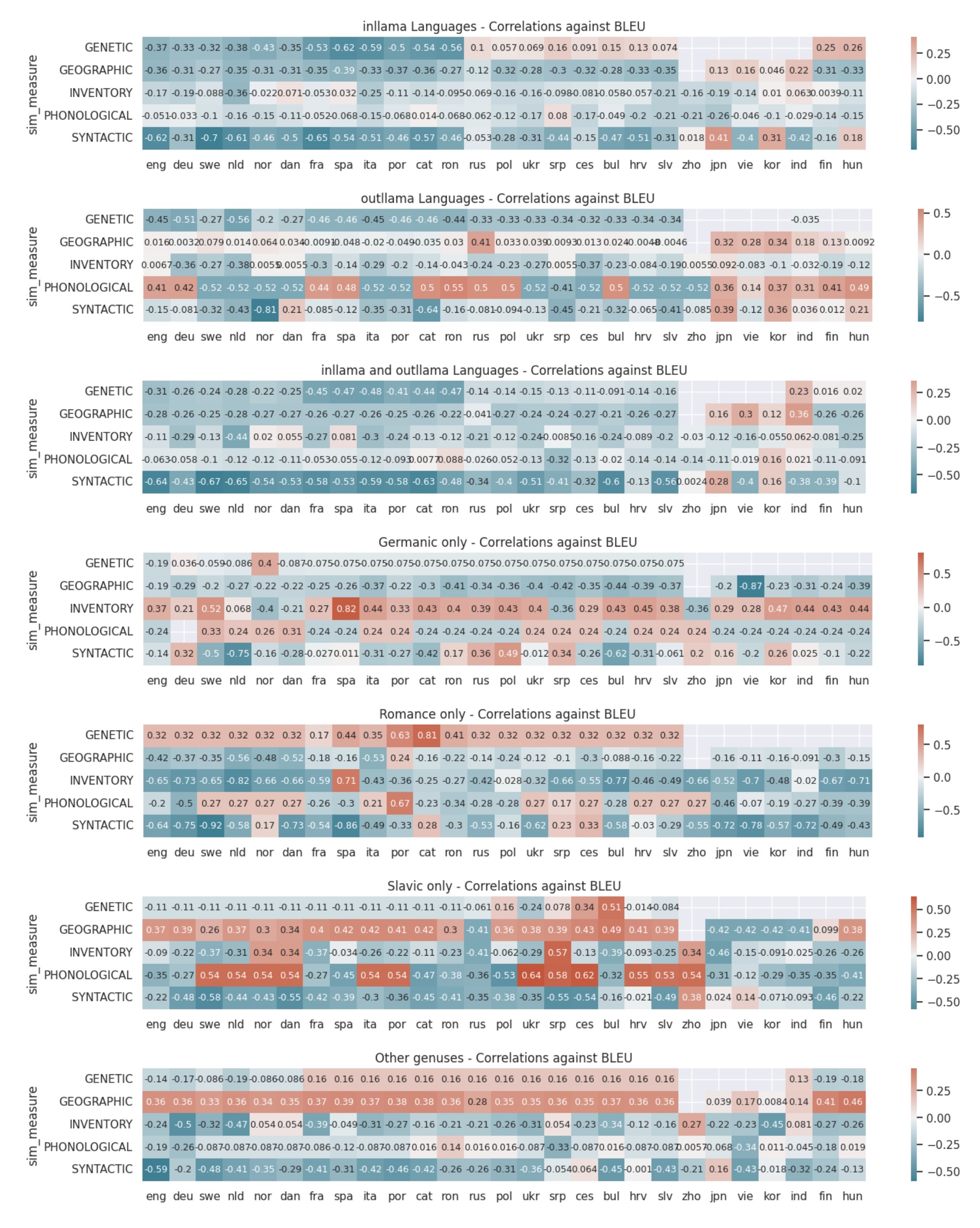
Large Language Models (LLMs) demonstrate strong machine translation capabilities on languages they are trained on. However, the impact of factors beyond training data size on translation performance remains a topic of debate, especially concerning languages not directly encountered during training. Our study delves into Llama2's translation capabilities. By modeling a linear relationship between linguistic feature distances and machine translation scores, we ask ourselves if there are potentially better central languages for LLMs other than English. Our experiments show that the 7B Llama2 model yields above 10 BLEU when translating into all languages it has seen, which rarely happens for languages it has not seen. Most translation improvements into unseen languages come from scaling up the model size rather than instruction tuning or increasing shot count. Furthermore, our correlation analysis reveals that syntactic similarity is not the only linguistic factor that strongly correlates with machine translation scores. Interestingly, we discovered that under specific circumstances, some languages (e.g. Swedish, Catalan), despite having significantly less training data, exhibit comparable correlation levels to English. These insights challenge the prevailing landscape of LLMs, suggesting that models centered around languages other than English could provide a more efficient foundation for multilingual applications.
4/8/2024