Event-Triggered Reinforcement Learning Based Joint Resource Allocation for Ultra-Reliable Low-Latency V2X Communications

0

Sign in to get full access
Overview
- Event-Triggered Reinforcement Learning (ETRL) is used for joint resource allocation in ultra-reliable low-latency vehicle-to-everything (V2X) communications
- The goal is to maximize reliability and minimize latency while efficiently using network resources
- The ETRL approach triggers resource allocation updates only when necessary, reducing overhead compared to traditional methods
Plain English Explanation
In this paper, the researchers propose using Event-Triggered Reinforcement Learning (ETRL) to optimize resource allocation for ultra-reliable low-latency vehicle-to-everything (V2X) communications. The goal is to maximize the reliability and minimize the latency of these V2X communications, while using network resources efficiently.
Traditional resource allocation methods often update allocations at fixed time intervals, even when the situation hasn't changed much. In contrast, the ETRL approach only triggers an update when it's really necessary, reducing the overhead and complexity. The ETRL agent learns when to update the resource allocation based on the current conditions, making the system more dynamic and responsive.
Technical Explanation
The paper presents an ETRL-based joint resource allocation framework for ultra-reliable low-latency V2X communications. The framework consists of three main components:
-
State Representation: The agent's state incorporates information about the current channel conditions, traffic demands, and resource utilization.
-
Action Space: The agent can adjust the resource allocation, including transmit power, bandwidth, and time slots, for each vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) link.
-
Reward Function: The reward function encourages the agent to maximize reliability (in terms of outage probability) and minimize latency, while considering fairness and efficient resource utilization.
The ETRL agent learns the optimal resource allocation policy through iterative interactions with the environment. Unlike traditional fixed-interval approaches, the ETRL agent only triggers an update when the change in the environment exceeds a certain threshold, reducing unnecessary computations and signaling overhead.
Critical Analysis
The paper presents a promising approach to address the challenges of ultra-reliable low-latency V2X communications, which is a crucial requirement for enabling advanced automotive applications like autonomous driving and vehicle platooning.
However, the authors acknowledge some limitations of their work. For example, the ETRL framework assumes perfect knowledge of the environment, which may not be realistic in practical scenarios. Additionally, the paper does not consider the impact of multiple vehicles competing for resources, which could introduce additional complexities.
Further research could explore ways to relax these assumptions, such as incorporating imperfect information and multi-agent interactions. Exploring the scalability of the ETRL approach as the number of vehicles and network complexity increases would also be a valuable avenue for future work.
Conclusion
This paper presents an Event-Triggered Reinforcement Learning (ETRL)-based joint resource allocation framework for ultra-reliable low-latency V2X communications. By dynamically updating resource allocations only when necessary, the ETRL approach can improve efficiency and reduce overhead compared to traditional fixed-interval methods.
The proposed framework demonstrates the potential of reinforcement learning techniques to address the complex challenges of V2X communications, which are crucial for the development of advanced automotive applications. While the paper highlights some limitations, the overall approach offers a promising direction for further research and innovation in this important domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Event-Triggered Reinforcement Learning Based Joint Resource Allocation for Ultra-Reliable Low-Latency V2X Communications
Nasir Khan, Sinem Coleri
Future 6G-enabled vehicular networks face the challenge of ensuring ultra-reliable low-latency communication (URLLC) for delivering safety-critical information in a timely manner. Existing resource allocation schemes for vehicle-to-everything (V2X) communication systems primarily rely on traditional optimization-based algorithms. However, these methods often fail to guarantee the strict reliability and latency requirements of URLLC applications in dynamic vehicular environments due to the high complexity and communication overhead of the solution methodologies. This paper proposes a novel deep reinforcement learning (DRL) based framework for the joint power and block length allocation to minimize the worst-case decoding-error probability in the finite block length (FBL) regime for a URLLC-based downlink V2X communication system. The problem is formulated as a non-convex mixed-integer nonlinear programming problem (MINLP). Initially, an algorithm grounded in optimization theory is developed based on deriving the joint convexity of the decoding error probability in the block length and transmit power variables within the region of interest. Subsequently, an efficient event-triggered DRL-based algorithm is proposed to solve the joint optimization problem. Incorporating event-triggered learning into the DRL framework enables assessing whether to initiate the DRL process, thereby reducing the number of DRL process executions while maintaining reasonable reliability performance. Simulation results demonstrate that the proposed event-triggered DRL scheme can achieve 95% of the performance of the joint optimization scheme while reducing the DRL executions by up to 24% for different network settings.
Read more7/22/2024

0
Graph Neural Networks and Deep Reinforcement Learning Based Resource Allocation for V2X Communications
Maoxin Ji, Qiong Wu, Pingyi Fan, Nan Cheng, Wen Chen, Jiangzhou Wang, Khaled B. Letaief
In the rapidly evolving landscape of Internet of Vehicles (IoV) technology, Cellular Vehicle-to-Everything (C-V2X) communication has attracted much attention due to its superior performance in coverage, latency, and throughput. Resource allocation within C-V2X is crucial for ensuring the transmission of safety information and meeting the stringent requirements for ultra-low latency and high reliability in Vehicle-to-Vehicle (V2V) communication. This paper proposes a method that integrates Graph Neural Networks (GNN) with Deep Reinforcement Learning (DRL) to address this challenge. By constructing a dynamic graph with communication links as nodes and employing the Graph Sample and Aggregation (GraphSAGE) model to adapt to changes in graph structure, the model aims to ensure a high success rate for V2V communication while minimizing interference on Vehicle-to-Infrastructure (V2I) links, thereby ensuring the successful transmission of V2V link information and maintaining high transmission rates for V2I links. The proposed method retains the global feature learning capabilities of GNN and supports distributed network deployment, allowing vehicles to extract low-dimensional features that include structural information from the graph network based on local observations and to make independent resource allocation decisions. Simulation results indicate that the introduction of GNN, with a modest increase in computational load, effectively enhances the decision-making quality of agents, demonstrating superiority to other methods. This study not only provides a theoretically efficient resource allocation strategy for V2V and V2I communications but also paves a new technical path for resource management in practical IoV environments.
Read more7/10/2024
0
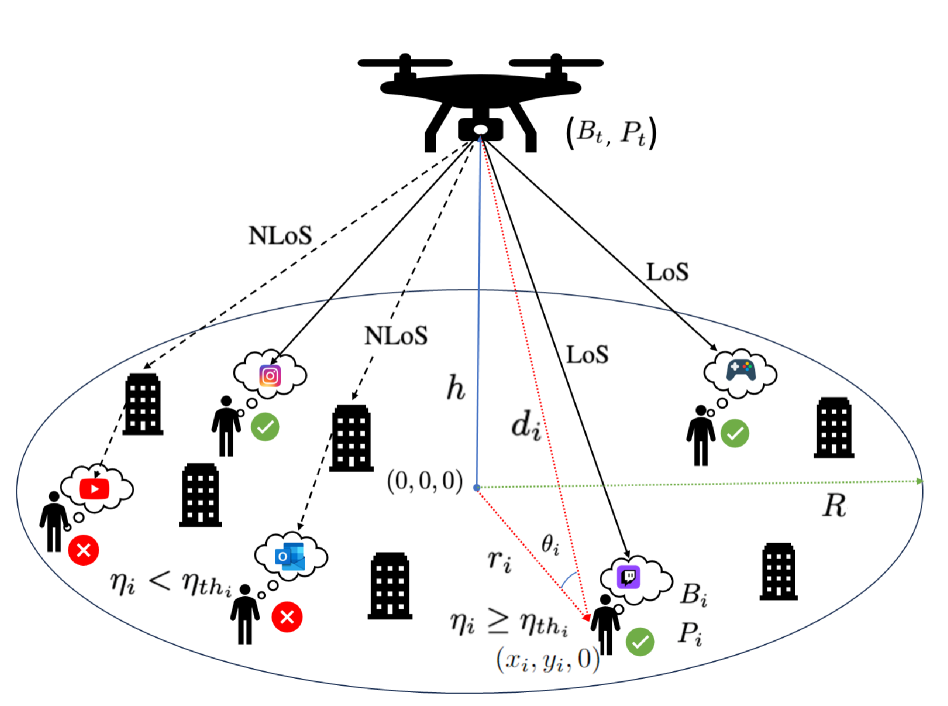
A Novel Joint DRL-Based Utility Optimization for UAV Data Services
Xuli Cai, Poonam Lohan, Burak Kantarci
In this paper, we propose a novel joint deep reinforcement learning (DRL)-based solution to optimize the utility of an uncrewed aerial vehicle (UAV)-assisted communication network. To maximize the number of users served within the constraints of the UAV's limited bandwidth and power resources, we employ deep Q-Networks (DQN) and deep deterministic policy gradient (DDPG) algorithms for optimal resource allocation to ground users with heterogeneous data rate demands. The DQN algorithm dynamically allocates multiple bandwidth resource blocks to different users based on current demand and available resource states. Simultaneously, the DDPG algorithm manages power allocation, continuously adjusting power levels to adapt to varying distances and fading conditions, including Rayleigh fading for non-line-of-sight (NLoS) links and Rician fading for line-of-sight (LoS) links. Our joint DRL-based solution demonstrates an increase of up to 41% in the number of users served compared to scenarios with equal bandwidth and power allocation.
Read more6/18/2024
0
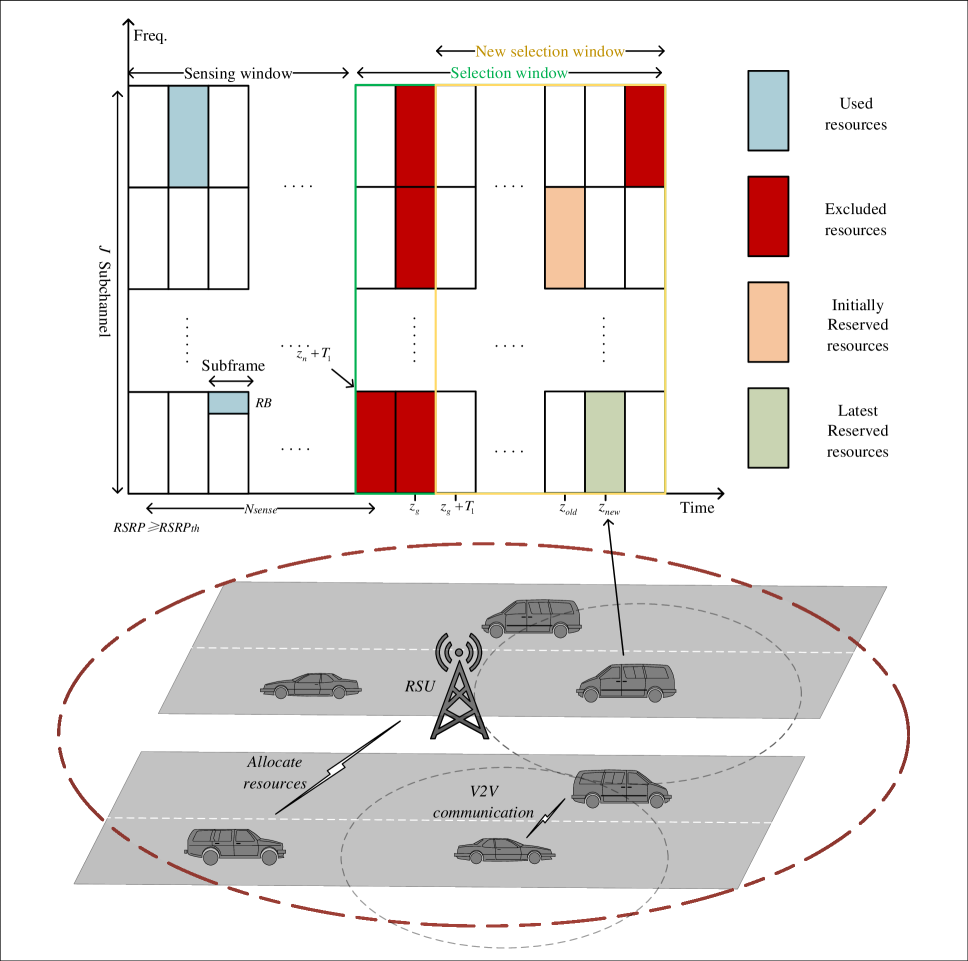
Joint Optimization of Age of Information and Energy Consumption in NR-V2X System based on Deep Reinforcement Learning
Shulin Song, Zheng Zhang, Qiong Wu, Qiang Fan, Pingyi Fan
Autonomous driving may be the most important application scenario of next generation, the development of wireless access technologies enabling reliable and low-latency vehicle communication becomes crucial. To address this, 3GPP has developed Vehicle-to-Everything (V2X) specifications based on 5G New Radio (NR) technology, where Mode 2 Side-Link (SL) communication resembles Mode 4 in LTE-V2X, allowing direct communication between vehicles. This supplements SL communication in LTE-V2X and represents the latest advancement in cellular V2X (C-V2X) with improved performance of NR-V2X. However, in NR-V2X Mode 2, resource collisions still occur, and thus degrade the age of information (AOI). Therefore, a interference cancellation method is employed to mitigate this impact by combining NR-V2X with Non-Orthogonal multiple access (NOMA) technology. In NR-V2X, when vehicles select smaller resource reservation interval (RRI), higher-frequency transmissions take ore energy to reduce AoI. Hence, it is important to jointly consider AoI and communication energy consumption based on NR-V2X communication. Then, we formulate such an optimization problem and employ the Deep Reinforcement Learning (DRL) algorithm to compute the optimal transmission RRI and transmission power for each transmitting vehicle to reduce the energy consumption of each transmitting vehicle and the AoI of each receiving vehicle. Extensive simulations have demonstrated the performance of our proposed algorithm.
Read more7/12/2024